
Artificial Intelligence
AI-ondersteunde objectbewerking met Google's Imagic en Runway's 'Erase and Replace'

Deze week bieden twee nieuwe, maar contrasterende AI-gestuurde grafische algoritmen nieuwe manieren voor eindgebruikers om zeer gedetailleerde en effectieve wijzigingen aan objecten in foto's aan te brengen.
De eerste is Imagisch, van Google Research, in samenwerking met Israel's Institute of Technology en Weizmann Institute of Science. Imagic biedt tekstgeconditioneerde, fijnmazige bewerking van objecten via de fijnafstemming van diffusiemodellen.

Verander wat je leuk vindt en laat de rest staan - Imagic belooft gedetailleerde bewerking van alleen de delen die je wilt wijzigen. Bron: https://arxiv.org/pdf/2210.09276.pdf
Iedereen die ooit heeft geprobeerd om slechts één element in een herweergave van Stable Diffusion te wijzigen, weet maar al te goed dat het systeem voor elke succesvolle bewerking vijf dingen zal veranderen die je leuk vond zoals ze waren. Het is een tekortkoming waardoor veel van de meest getalenteerde SD-enthousiastelingen momenteel voortdurend heen en weer schakelen tussen Stable Diffusion en Photoshop om dit soort 'nevenschade' op te lossen. Alleen al vanuit dit standpunt lijken de prestaties van Imagic opmerkelijk.
Op het moment van schrijven heeft Imagic nog niet eens een promotievideo, en gezien die van Google omzichtige houding tot het vrijgeven van onbelemmerde tools voor beeldsynthese, is het onzeker in hoeverre we de kans zullen krijgen om het systeem te testen.
Het tweede aanbod is dat van Runway ML wat toegankelijker Wissen en vervangen faciliteit, een nieuwe functie in de 'AI Magic Tools'-sectie van zijn exclusieve online suite van op machine learning gebaseerde hulpprogramma's voor visuele effecten.
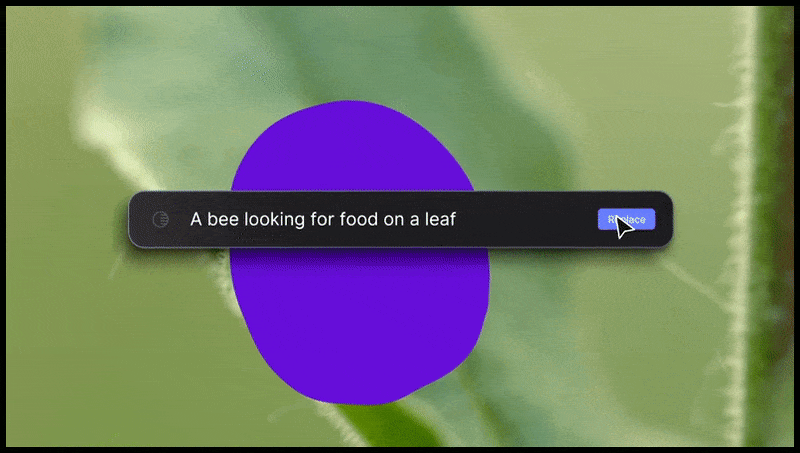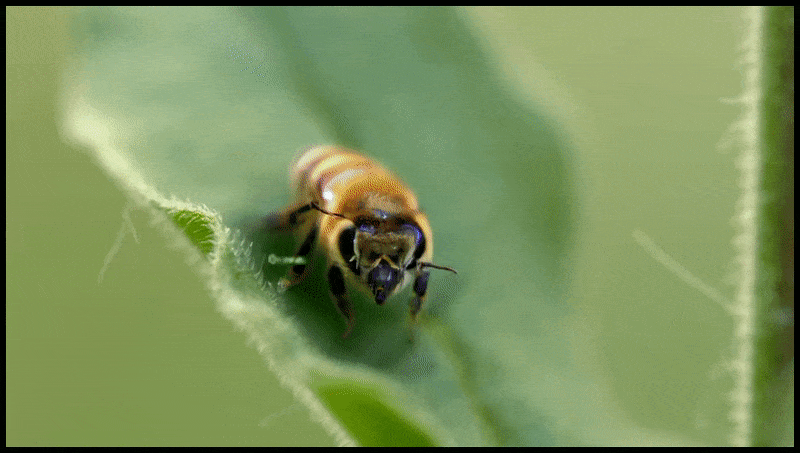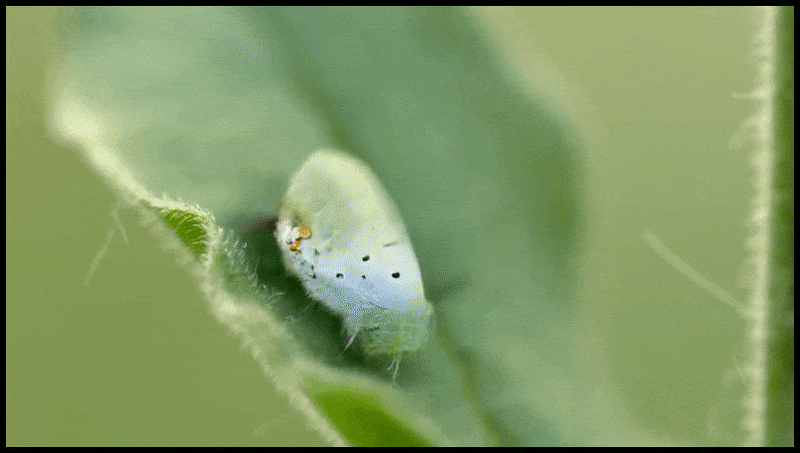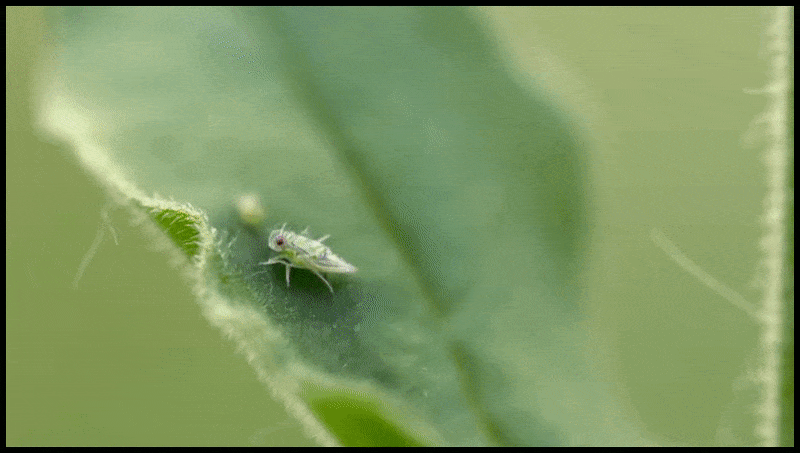
Runway ML's Erase and Replace-functie, al gezien in een preview voor een tekst-naar-video-bewerkingssysteem. Bron: https://www.youtube.com/watch?v=41Qb58ZPO60
Laten we eerst eens kijken naar het optreden van Runway.
Wissen en vervangen
Net als Imagic heeft Erase and Replace uitsluitend betrekking op stilstaande beelden, hoewel Runway dat wel heeft gedaan preview dezelfde functionaliteit in een tekst-naar-videobewerkingsoplossing die nog niet is uitgebracht:

Hoewel iedereen de nieuwe functie voor wissen en vervangen op afbeeldingen kan uitproberen, is de videoversie nog niet openbaar beschikbaar. Bron: https://twitter.com/runwayml/status/1568220303808991232
Hoewel Runway ML geen details heeft vrijgegeven over de technologieën achter Erase and Replace, suggereert de snelheid waarmee je een kamerplant kunt vervangen door een redelijk overtuigende buste van Ronald Reagan dat een diffusiemodel zoals Stable Diffusion (of, veel minder waarschijnlijk, een gelicentieerde DALL-E 2) is de engine die het object van uw keuze opnieuw uitvindt in Erase and Replace.

Een kamerplant vervangen door een buste van The Gipper gaat niet zo snel als dit, maar wel behoorlijk snel. Bron: https://app.runwayml.com/
Het systeem heeft enkele beperkingen van het DALL-E 2-type – afbeeldingen of tekst die de Erase and Replace-filters markeren, zullen een waarschuwing activeren over mogelijke accountopschorting in het geval van verdere overtredingen – praktisch een standaardkloon van OpenAI's lopende beleidsmaatregelen door te lezen. voor DALL-E 2 .
Veel van de resultaten missen de typische ruwe kantjes van Stable Diffusion. Runway ML zijn investeerders en onderzoekspartners in SD, en het is mogelijk dat ze een bedrijfseigen model hebben getraind dat superieur is aan de open source 1.4 checkpoint-gewichten waar de rest van ons momenteel mee worstelt (zoals veel andere ontwikkelingsgroepen, zowel hobbyisten als professionals, momenteel aan het trainen of verfijnen zijn Stabiele diffusiemodellen).
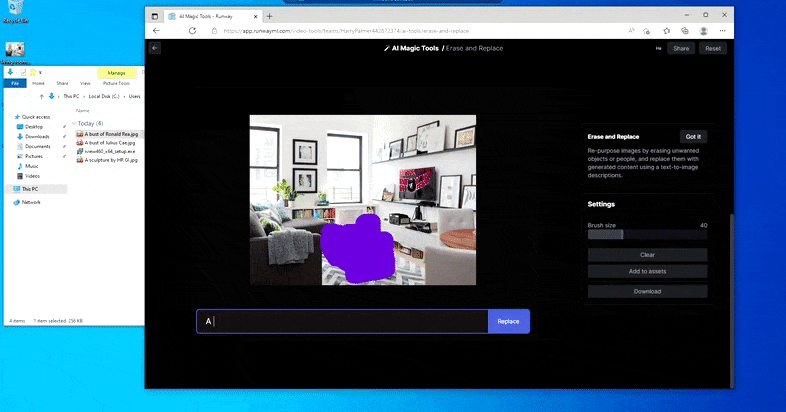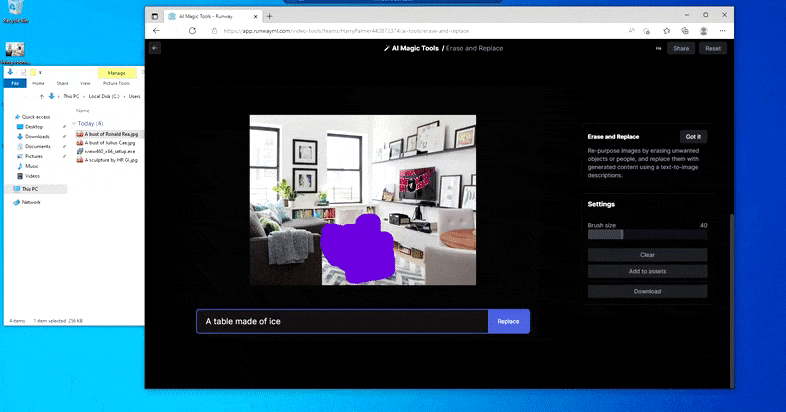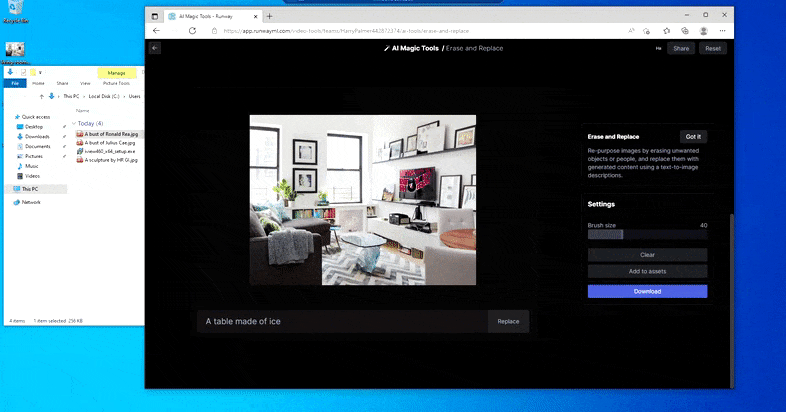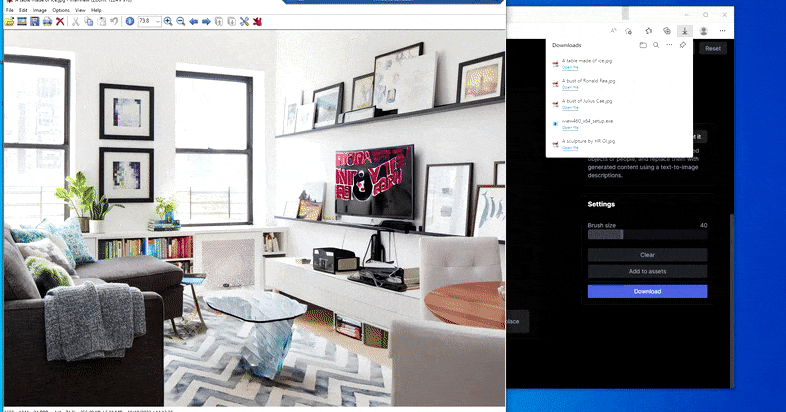
Een tafel vervangen door een 'tafel gemaakt van ijs' in Runway ML's Erase and Replace.
Net als bij Imagic (zie hieronder), is Erase and Replace als het ware 'objectgeoriënteerd' – je kunt niet zomaar een 'leeg' deel van de afbeelding wissen en het opnieuw inkleuren met het resultaat van je tekstprompt; in dat scenario volgt het systeem eenvoudigweg het dichtstbijzijnde zichtbare object langs de gezichtslijn van het masker (zoals een muur of een televisie) en past de transformatie daar toe.
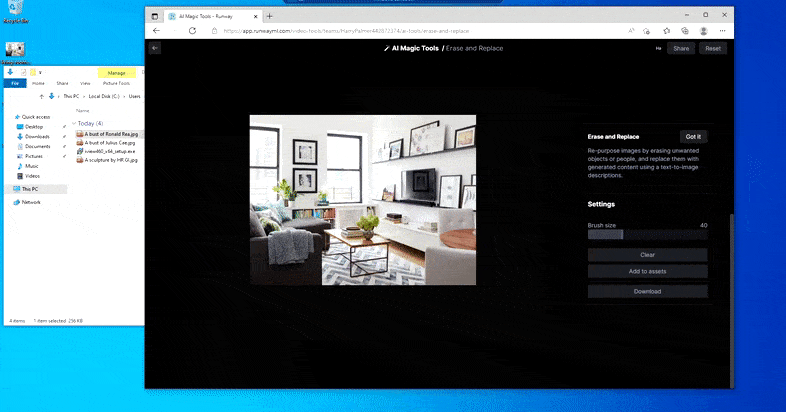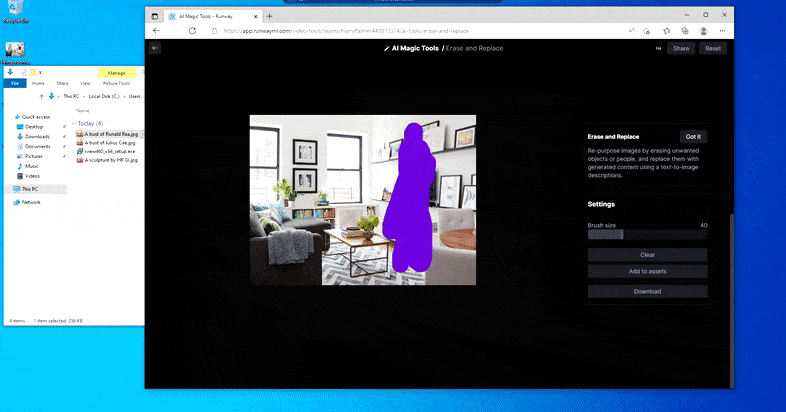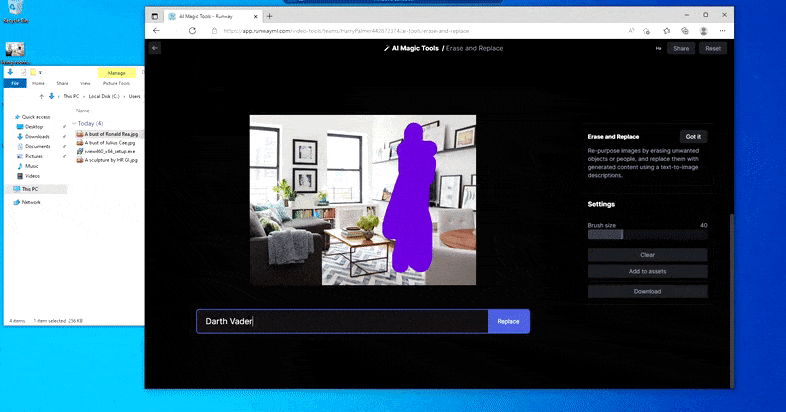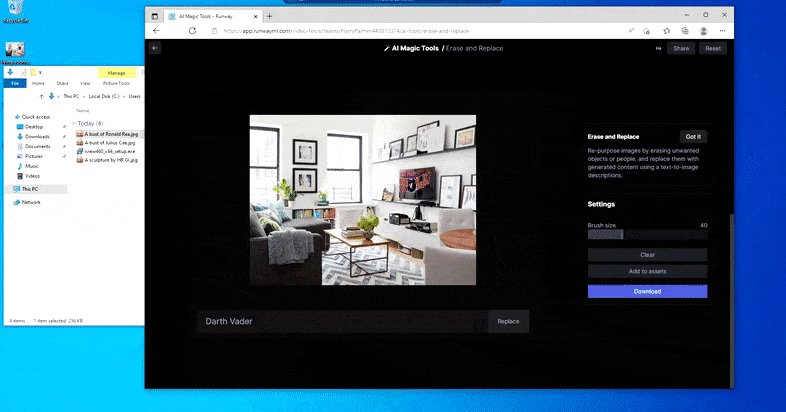
Zoals de naam al aangeeft, kunt u geen objecten in lege ruimte injecteren in Wissen en vervangen. Hier resulteert een poging om de beroemdste van de Sith-heren op te roepen in een vreemde Vader-gerelateerde muurschildering op de tv, ongeveer waar het 'vervang'-gebied werd getekend.
Het is moeilijk te zeggen of Erase and Replace ontwijkend is met betrekking tot het gebruik van auteursrechtelijk beschermde afbeeldingen (die nog steeds grotendeels worden belemmerd, zij het met wisselend succes, in DALL-E 2), of dat het model dat wordt gebruikt in de backend-rendering-engine is gewoon niet geoptimaliseerd voor dat soort dingen.

De enigszins NSFW 'Mural of Nicole Kidman' geeft aan dat het (vermoedelijk) op diffusie gebaseerde model dat voorhanden is, de eerdere systematische afwijzing van DALL-E 2 van het weergeven van realistische gezichten of pikante inhoud mist, terwijl de resultaten voor pogingen om auteursrechtelijk beschermde werken aan te tonen variëren van de dubbelzinnige ('xenomorf') tot het absurde ('de ijzeren troon'). Inzet rechtsonder, de bronafbeelding.
Het zou interessant zijn om te weten welke methoden Erase and Replace gebruikt om de objecten te isoleren die het kan vervangen. Vermoedelijk wordt de afbeelding door een of andere afleiding geleid CLIP, met de afzonderlijke items geïndividualiseerd door objectherkenning en daaropvolgende semantische segmentatie. Geen van deze bewerkingen werkt ook maar in de buurt van een gemeenschappelijke of tuininstallatie van Stable Diffusion.
Maar niets is perfect - soms lijkt het systeem te wissen en niet te vervangen, zelfs wanneer (zoals we in de afbeelding hierboven hebben gezien) het onderliggende weergavemechanisme zeker weet wat een tekstprompt betekent. In dit geval blijkt het onmogelijk om van een salontafel een xenomorph te maken – de tafel verdwijnt gewoon.
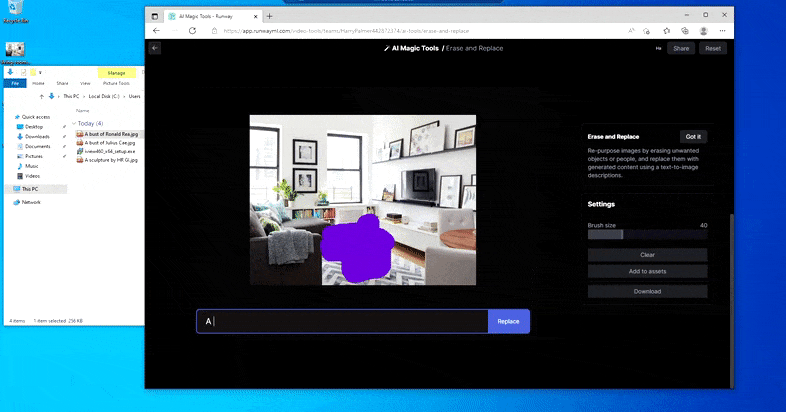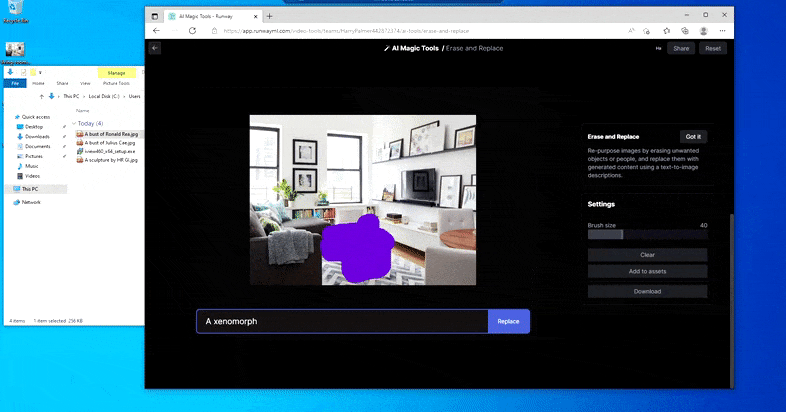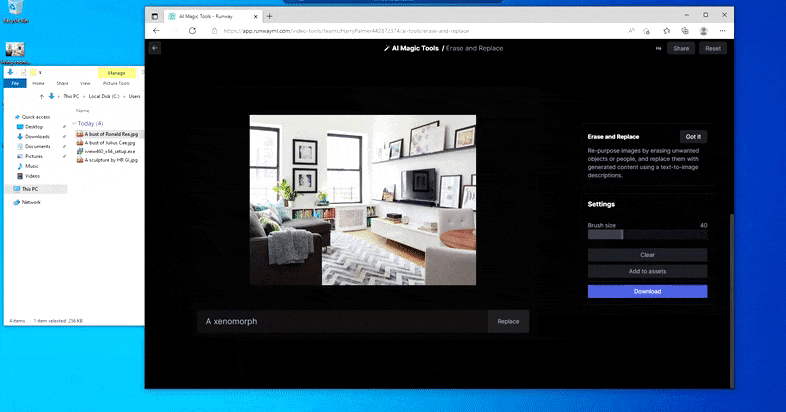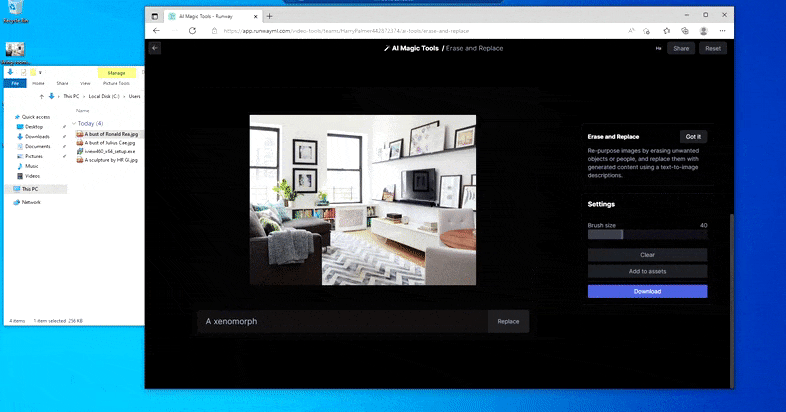
Een engere versie van 'Where's Waldo', aangezien Erase and Replace geen alien oplevert.
Erase and Replace lijkt een effectief objectvervangingssysteem te zijn, met uitstekende inschildering. Het kan bestaande waargenomen objecten echter niet bewerken, maar alleen vervangen. Het daadwerkelijk veranderen van bestaande beeldinhoud zonder het omgevingsmateriaal in gevaar te brengen is aantoonbaar een veel moeilijkere taak, die verband houdt met de lange strijd van de computer vision-onderzoekssector om ontwarring in de verschillende latente ruimtes van de populaire kaders.
Imagisch
Het is een taak die Imagic aanpakt. De nieuw papier biedt tal van voorbeelden van bewerkingen die met succes afzonderlijke facetten van een foto wijzigen terwijl de rest van de afbeelding onaangeroerd blijft.

In Imagic hebben de gewijzigde afbeeldingen geen last van het karakteristieke uitrekken, vervormen en 'occlusie raden' dat kenmerkend is voor deepfake-poppenspel, waarbij gebruik wordt gemaakt van beperkte priors die zijn afgeleid van een enkele afbeelding.
Het systeem maakt gebruik van een proces in drie fasen: optimalisatie van tekstinbedding; fijnafstemming van modellen; en ten slotte het genereren van de gewijzigde afbeelding.

Imagic codeert de doeltekstprompt om de initiële tekstinbedding op te halen en optimaliseert vervolgens het resultaat om de invoerafbeelding te verkrijgen. Daarna wordt het generatieve model nauwkeurig afgestemd op het bronbeeld, waarbij een reeks parameters wordt toegevoegd, voordat het wordt onderworpen aan de gevraagde interpolatie.
Het is niet verwonderlijk dat het framework is gebaseerd op dat van Google Beeld tekst-naar-video-architectuur, hoewel de onderzoekers stellen dat de principes van het systeem breed toepasbaar zijn op latente diffusiemodellen.
Imagen gebruikt een architectuur met drie niveaus, in plaats van de array met zeven niveaus die wordt gebruikt voor de recentere van het bedrijf iteratie van tekst naar video van de programmatuur. De drie verschillende modules omvatten een generatief diffusiemodel dat werkt met een resolutie van 64x64px; een model met superresolutie dat deze uitvoer opschaalt naar 256x256px; en een extra model met superresolutie om de uitvoer helemaal tot een resolutie van 1024 × 1024 te brengen.
Imagic komt tussenbeide in de vroegste fase van dit proces en optimaliseert de gevraagde tekstinbedding in de 64px-fase op een Adam-optimizer met een statische leersnelheid van 0.0001.

Een masterclass in ontwarring: die eindgebruikers die hebben geprobeerd zoiets eenvoudigs als de kleur van een gerenderd object in een diffusie-, GAN- of NeRF-model te veranderen, zullen weten hoe belangrijk het is dat Imagic dergelijke transformaties kan uitvoeren zonder 'uit elkaar te scheuren'. ' de consistentie van de rest van de afbeelding.
Verfijning vindt vervolgens plaats op het basismodel van Imagen, voor 1500 stappen per invoerbeeld, afhankelijk van de herziene inbedding. Tegelijkertijd wordt de secundaire 64px>256px-laag parallel aan de geconditioneerde afbeelding geoptimaliseerd. De onderzoekers merken op dat een soortgelijke optimalisatie voor de laatste 256px>1024px laag 'weinig tot geen effect' heeft op de uiteindelijke resultaten, en hebben dit daarom niet doorgevoerd.
In de krant staat dat het optimalisatieproces ongeveer acht minuten duurt voor elke afbeelding op een tweeling TPUV4 fiches. De uiteindelijke weergave vindt plaats in de kern Imagen onder de DDIM-steekproefschema.
Net als bij vergelijkbare fijnafstemmingsprocessen voor Google droomcabine, kunnen de resulterende inbeddingen bovendien worden gebruikt om stilering mogelijk te maken, evenals fotorealistische bewerkingen die informatie bevatten die is ontleend aan de bredere onderliggende database die Imagen aandrijft (aangezien, zoals de eerste kolom hieronder laat zien, de bronafbeeldingen niet de benodigde inhoud hebben om deze transformaties bewerkstelligen).

Flexibele fotorealistische bewegingen en bewerkingen kunnen worden opgewekt via Imagic, terwijl de afgeleide en ontwarde codes die tijdens het proces worden verkregen net zo gemakkelijk kunnen worden gebruikt voor gestileerde output.
De onderzoekers vergeleken Imagic met eerdere werken SDBewerken, een op GAN gebaseerde aanpak uit 2021, een samenwerking tussen Stanford University en Carnegie Mellon University; En Tekst2Live, een samenwerking, vanaf april 2022, tussen het Weizmann Institute of Science en NVIDIA.

Een visuele vergelijking tussen Imagic, SDEdit en Text2Live.
Het is duidelijk dat de eerdere benaderingen het moeilijk hebben, maar in de onderste rij, waarbij een enorme verandering van houding wordt gebruikt, slagen de gevestigde exploitanten er niet in om het bronmateriaal opnieuw vorm te geven, vergeleken met een opmerkelijk succes van Imagic.
Imagic's resourcevereisten en trainingstijd per afbeelding, hoewel kort volgens de normen van dergelijke bezigheden, maken het onwaarschijnlijk dat het wordt opgenomen in een lokale beeldbewerkingstoepassing op pc's - en het is niet duidelijk in hoeverre het proces van fijnafstemming zou kunnen worden teruggebracht tot consumentenniveau.
Zoals het er nu uitziet, is Imagic een indrukwekkend aanbod dat meer geschikt is voor API's - een omgeving waar Google Research, wantrouwend voor kritiek met betrekking tot het faciliteren van deepfaking, in ieder geval het meest comfortabel mee is.
Voor het eerst gepubliceerd op 18 oktober 2022.















