
Хиймэл оюун
"Мөрдөгч" хиймэл оюун ухаан нь олон эх сурвалжаас ойлгомжгүй хүмүүсийг таньж чадна

Оксфордын их сургуулийн судлаачид видеон дээрх хүмүүсийг хэн болохыг нь, контекстээс нь болон олон нийтэд нээлттэй хоёрдогч эх сурвалжаас, мөрдөгч маягтай, олон домэйн судалгаа хийж, цогцоор нь таних боломжтой хиймэл оюун ухаантай системийг бүтээжээ. аудио эх сурвалжийг интернетээс харааны материалтай тааруулах.
Судалгаа нь телевизийн нэвтрүүлэг, кинонд гарч буй хүмүүс гэх мэт олон нийтийн зүтгэлтнүүдийг тодорхойлоход төвлөрдөг ч нөхцөл байдлаас нь ялган таних зарчим нь онлайн эх сурвалжид нүүр царай, дуу хоолой, нэр нь гарсан хэн бүхэнд онолын хувьд хэрэгждэг.
Үнэндээ бол цаас Алдар нэрийн талаарх өөрийн тодорхойлолт нь зөвхөн шоу бизнесийн ажилчдаар хязгаарлагдахгүй бөгөөд судлаачид "Бид цахим ертөнцөд өөрсдийнхөө олон зурагтай хүмүүсийг хэлдэг. алдартай'.
Шууд видео руу
Оксфордын Инженерийн шинжлэх ухааны тэнхимийн харааны геометрийн бүлгийн судлаачид уг ажилд урам зориг өгсөн хүний хэв маягийн эрэн сурвалжлах арга барилыг тоймложээ.
“Та видео үзэж байгаад шинэ хүнтэй учирч байна гэж төсөөлөөд үз дээ. Тэднийг итгэлтэйгээр таньж мэдэхийн тулд та эхлээд дэлгэцэн дээрх бичвэр, ярианд нэр нь дурдагдсан гэх мэт видео бичлэгээс эсвэл интернетийн архиваас жүжигчдийн жагсаалтаас тэдний нэрийг хайх хэрэгтэй. Дараа нь та тухайн хүнийг онлайнаар хайснаар энэ нэр зөв болохыг батлах зарим нотлох баримт олж болно.'
Баримт бичигт санал болгож буй аргачлал нь бүрэн автоматжуулсан бөгөөд бүх нэмэлт гарын авлагын шошгыг арилгадаг (онлайн эх сурвалжийн ханган нийлүүлэгчдийн хийсэн аливаа зүйлийг хөнгөлөх). Систем нь домайн дасан зохицох шаардлагагүй гурван хамааралгүй өгөгдлийн багц дээр сайн ажилладаг нь батлагдсан.
Энэхүү ажлын хэрэглээний талаар судлаачид тэмдэглэгээгүй, тунгалаг видео өгөгдлийн экспоненциал өсөлт, хүний удирдсан үнэтэй тайлбаргүйгээр тэдгээрээс таних мэдээллийг олж авах шинэ систем шаардлагатай байгааг тэмдэглэжээ.
'[Өгөгдлийн] асар том хэмжээ нь холбогдох мета өгөгдлийн хомсдолтой хослуулан энэ агуулгыг индексжүүлэх, дүн шинжилгээ хийх, удирдах нь улам хэцүү ажил болж байна. Хүний гарын авлагын нэмэлт тайлбарт найдах нь цаашид хэрэгжих боломжгүй болсон бөгөөд эдгээр видеог удирдах үр дүнтэй арга байхгүй бол энэ мэдлэгийн санд хандах боломжгүй болно.'
Ийм төрлийн индексжүүлэх систем нь хайлтын үр дүнгийн холбоосыг видеоны хайлтын сэдэв гарч ирэх цэг дээр шууд олох боломжийг нээж өгдөг бөгөөд энэ нь төслийн өгсөн үзэл баримтлалын баталгааны вэб хайлтаас харагдаж байна.
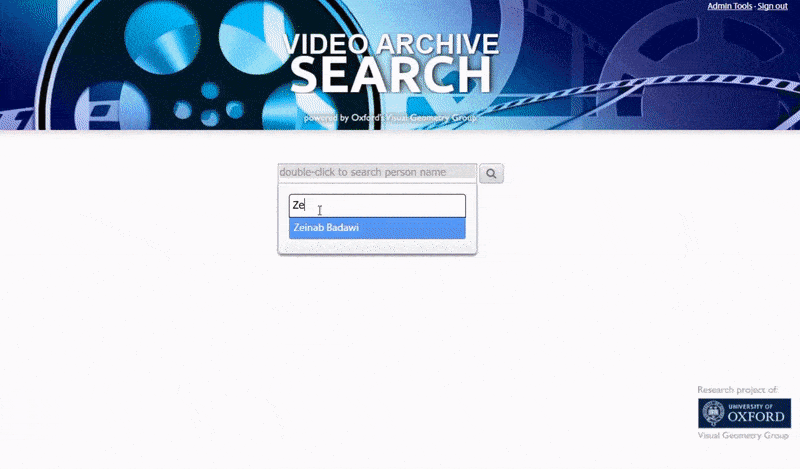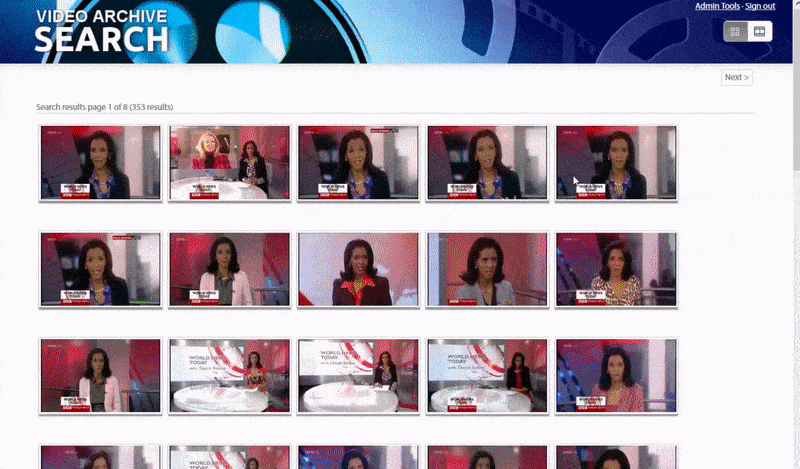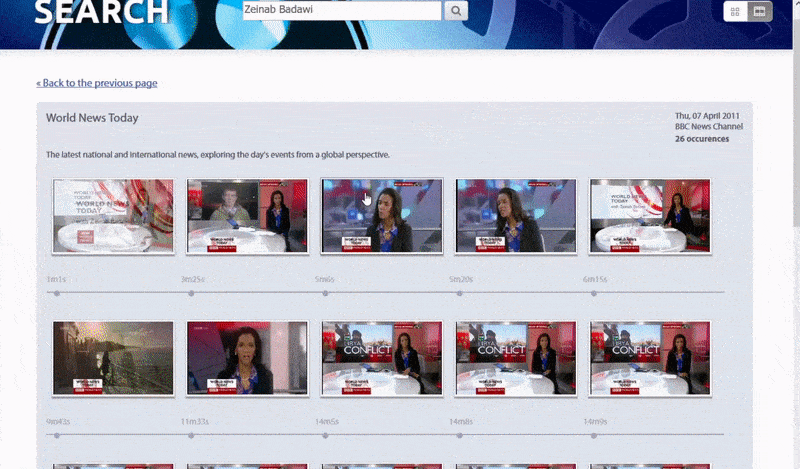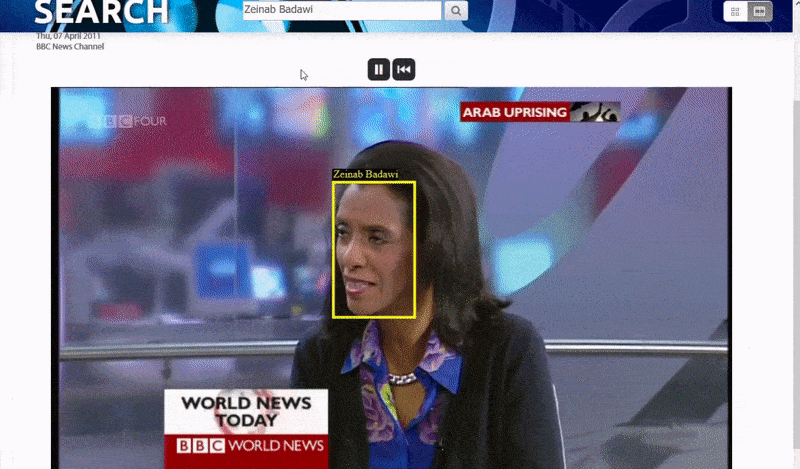
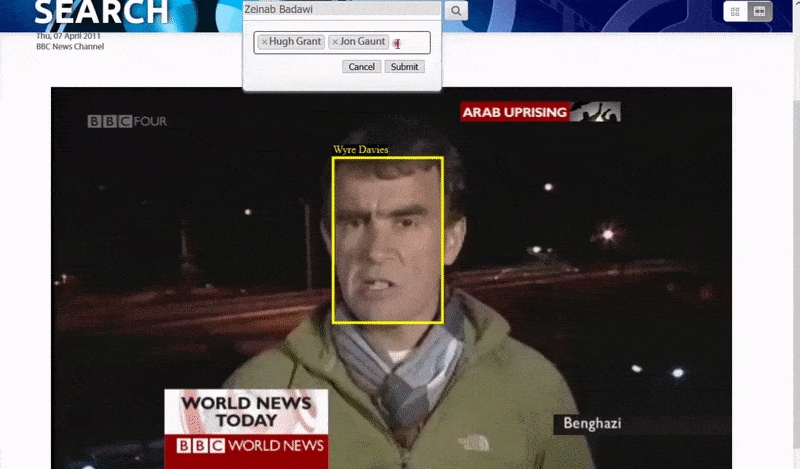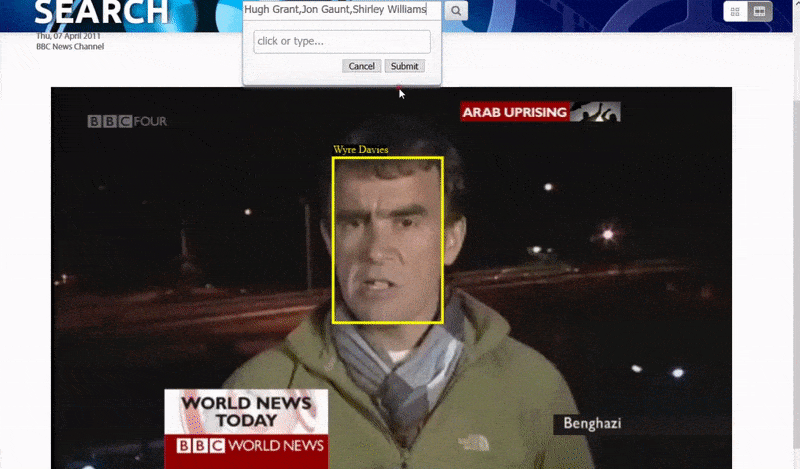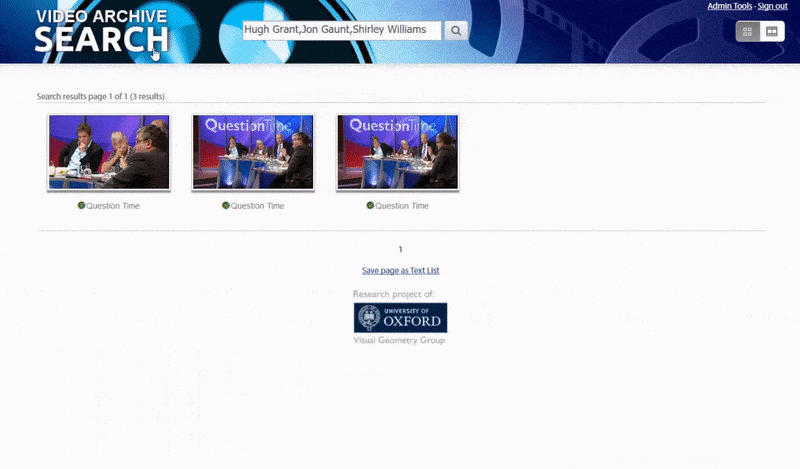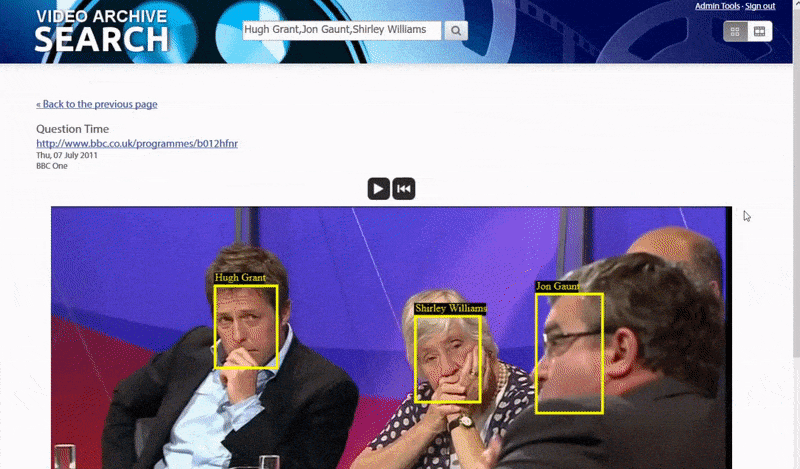
Оксфордын систем нь танигдсан хүний жишээг хайх боломжийг олгодог. Хайлтын үр дүн нь үзэгчийг видеон дээрх тухайн хүн гарч ирэх цэг рүү шууд аваачиж, дараа нь тухайн цэгээс видеог тоглуулах боломжтой.. Эх сурвалж: https://www.robots.ox.ac.uk/~vgg/research/person_id_in_video/
Систем нь "тодорхой" хүмүүсийг тодорхойлох арга замуудын нэг бол тэдний бусадтай харьцаж буй нөхцөл байдал юм. Тиймээс хайлтын систем нь нэг видеон дээр гарч буй олон таних тэмдгийг хайхад маш сайн хэрэглүүртэй.
Том ба жижиг загас
Энэхүү систем нь эхлээд IMDB гэх мэт олон нийтийн мэдээллийн нөөцтэй видеон дээрх мета өгөгдөл эсвэл OCR текстийг тааруулах замаар олон нийтэд нээлттэй сүлжээний нөөцөд нүүр царай нь маш сайн индексжүүлсэн тул таних нь харьцангуй өчүүхэн байдаг хүмүүсийг "бага унжсан жимс"-тэй шийддэг. жагсаалтууд. Видео тайлбар, кредит болон видеон дээрх растержуулсан текст дэх хиймэл оюун ухаанаар тайлбарласан текстийг мөн адил тодорхойлоход ашигладаг.
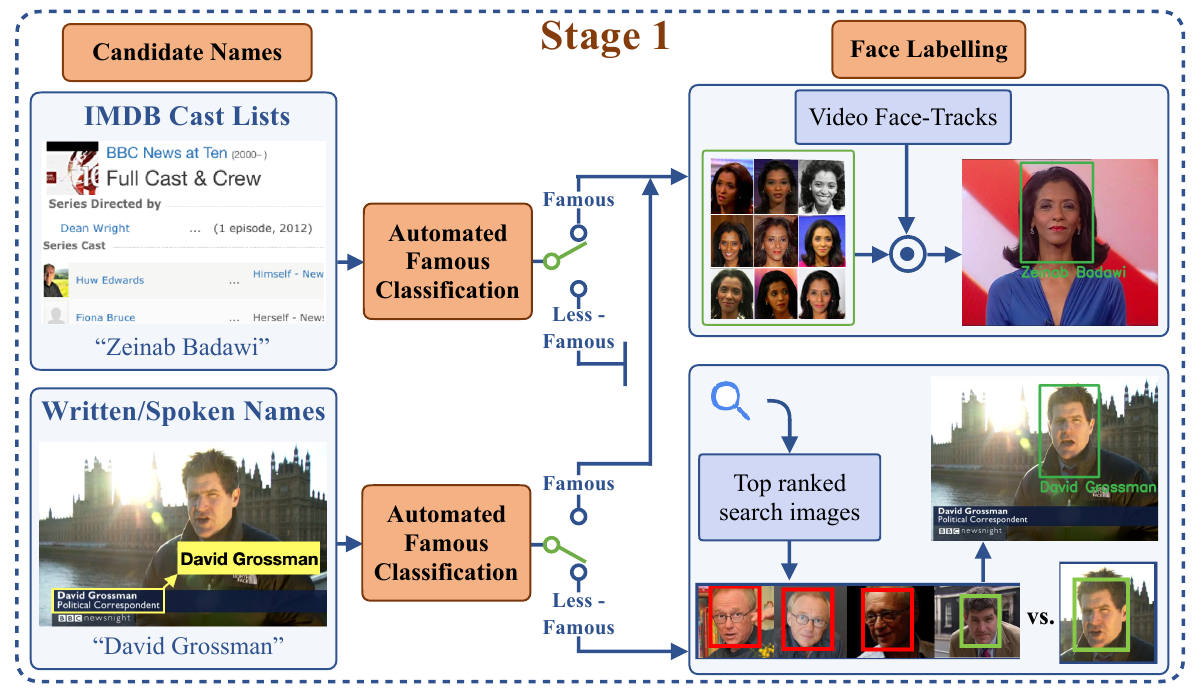
Хайлтын нэр дэвшигчдийн нэрийг растержуулсан текстийн оптик тэмдэгтийг таних (OCR) эсвэл бусад эх сурвалжийн жагсаалт гэх мэт бодит текст дээр үндэслэн систем автоматаар илрүүлж болно. Тиймээс хүмүүсийг эцсийн хэрэглэгчид өөрсдийнхөө нэрийн эсрэг ямар нэгэн асуулт асуухгүйгээр, хиймэл оюун ухаантай нийгмийн сүлжээнд урьдчилж оролцохгүйгээр автоматаар индексжүүлж болно. Эх сурвалж: https://www.robots.ox.ac.uk/~vgg/publications/2021/Brown21/brown21.pdf
Сүлжээнд байрлуулсан асар их зураг, видео тухайн хүний хэн болохыг баталж байгаа тохиолдолд мөрдөн байцаалтын явцад хэн болохыг нь баталдаг. Гэхдээ тухайн хүн илүү ойлгомжгүй байгаа тохиолдолд бусад аргуудыг ашигладаг, тухайлбал видео бичлэгээс авсан аудиог хэн болохыг батлах баталгаа болгон ашиглаж болно. Хэдийгээр энэ ажилд тусгагдаагүй ч гэсэн логикийн хувьд цэвэр аудио эх сурвалж, түүнчлэн видеон дахь аудио бүрэлдэхүүн хэсгүүдийг ашигладаг ийм төрлийн хүрээг зогсоох зүйл байхгүй.
Өөрийгөө дэлгэрүүлэх Паноптикон
Оксфордын төсөлд яриа таних технологийг растержуулсан эсвэл цэвэр текстээс нэр дэвшигчийн нэрийг үүсгэхээс гадна зөвхөн нэрсийг таних зорилгоор ашигладаг. ярианы аудио агуулгад. Тиймээс нэг эсвэл хоёр хүн байхгүй гуравдагч этгээдийг дурдаад л таниулбарыг эхлүүлж болно.
Оксфордын төслөөс нэвтрүүлж буй хамгаалалт нь нэр дэвшигч нь IMDB мэдээллийн санд байх ёстой, гэхдээ энэ дур зоргоороо заалтыг хассанаар системийн боломжийн цар хүрээг ихээхэн өргөжүүлж, энэ нь бүхэлдээ вэб хаягдал нөөцөд тулгуурладаг.

Тиймээс растер текстээс гаралтай нэрс, бодит текст, ярианд суурилсан дурдалт, маш хязгаарлагдмал визуал материал зэрэг эх сурвалжуудыг хослуулснаар харааны сүлжээ багатай хүмүүсийг тодорхойлох боломжтой болно.
Техникийн хувьд, ямар ч зураг, видео бичлэг хараахан холбогдоогүй байгаа, гэхдээ шинээр нэвтэрсэн видеоны эх сурвалжтай бусад хүчин зүйлүүд хамааралтай бол эцэст нь зураг эсвэл видеог хавсаргаж болох хувь хүний профайлыг бий болгох боломжтой болно.
Туршилтын мэдээллийн багц
Судлаачид системийн үр ашгийг үнэлэхийн тулд гурван мэдээллийн багц ашигласан: MediaEval, 2010-2015 оны хооронд авсан Creative Commons-ийн сошиал медиа болон олон нийтийн зургийн нөөцүүдийг (Wikipedia болон Flickr зэрэг) агуулсан; Оксфордын группын 2017 он Шерлок мэдээллийн багц, Конан Дойлын сонгодог дүрийн орчин үеийн алдартай BBC дасан зохицох видеоны тайлбартай видео мэдээллийг агуулсан; мөн BBC-ийн янз бүрийн тайлбартай мэдээний бичлэгийг ашигладаг уг төсөлд тусгайлан бүтээсэн шинэ BBC видео мэдээллийн багц.

Энэхүү систем нь нүүр нь тусгал эсвэл харанхуйд дарагдсан тохиолдол зэрэг өргөн хүрээний өгөгдлийн багц орчинд амжилттай ажилладаг.
Энэ үйл явц нь шууд зургийн хайлтын зэрэглэлийг ашигладаг.
Системийн үр дүн нь гурван загварт өндөр нарийвчлалтай болсон. Шерлокийн өгөгдлийн багцын хувьд хамгийн ойрын хөршийн ангилагчийг ашиглаж байсан ч олон талт ангилагчд дэмжлэг үзүүлэх вектор машин (SVMs) ашигладаг өмнөх аргаас 3-6%-иар шинэ систем сайжирсанд судлаачид гайхсан. шинэ бүтээл нь хүч чадал багатай хэрэгсэл юм.
үр дагавар
Оксфордын төслийн ёс суртахууны болон практикийн ихэнх хязгаарлалтыг судлаачид өөрсдөө ногдуулдаг, тухайлбал олж илрүүлсэн таниулгууд нь IMDB-д байгаа байх шаардлагаар "алдар нэр"-ийг тодорхойлох, системийг зөвхөн тогтсон эрдэм шинжилгээний өгөгдлийн багцын эсрэг турших гэх мэт. Creative Commons лицензийг хүндэтгэх.
Гэсэн хэдий ч төслийн үндсэн архитектур нь зөвхөн интернетэд бага эсвэл тэг харагдахуйц "тодорхойгүй" хүмүүсийг тодорхойлох ерөнхий аргыг дүрсэлдэг (учир нь зөвхөн нэрийг дурдах нь цаг хугацааны явцад боловсруулж болох таних тэмдэгийг төрүүлдэг. шаардлагатай), гэхдээ эрэлт хэрэгцээ гэхээсээ илүү рекурсив, механик сониуч зан, эсвэл шошготой өгөгдөл (PII мета өгөгдөл агуулсан олон нийтийн мэдээллийн хэрэгслээр зураг байршуулах гэх мэт) зэрэгт тулгуурласан хувь хүмүүсийн матрицыг бий болгох.
Төсөл нь газарзүйн байршлын өгөгдөл эсвэл нийгмийн мэдээллийн хэрэгслээр байршуулалтад анхдагч байдлаар суулгасан газарзүйн байршлын мэдээлэл (хэрэглэгчийн сонголтоор хасагдаагүй) гэх мэт баталгаажуулах баримт бичигт олж болох өргөн боломжтой мета өгөгдлийн бусад хэлбэрийг ашигладаггүй. Гэсэн хэдий ч баталгаажуулах үйл явцыг бэхжүүлэхийн тулд өгөгдлийн ийм нэмэлт хэмжээсийг ашиглахад ямар ч саад бэрхшээл байхгүй.
Оксфордын төсөл нь машин сургалтын төслүүдэд нийтлэг байдаг арга замаар (IMDB-д бүртгэгдээгүйгээс гадна бараг тэг байдаг таниулбаруудыг) тайрдаг бол ийм хамгийн бага мэдээлэл нь үл мэдэгдэх хүнийг танихаас илүү үр дүнтэй байж болох юм. тэдний талаар илүү их хэмжээний төлөөллийн мэдээлэл байсан. Хэрэв хэт давсан үзүүлэлтүүд нь таны хайж байгаа зүйл бол (өөрөөр хэлбэл сүлжээний талбай багатай хувь хүмүүс) бол сийрэг өгөгдөл нь маш сайн үзүүлэлт байж болно.
бэлэн байдал
Оксфордын судлаачид төслийн функцийг Google-тэй төстэй хайлтын системд багтаасан бөгөөд үүнийг Docker-ээр дамжуулан локал машин дээр татан авч суулгаж болно (гэхдээ 2021 оны XNUMX-р сарын баримт бичгийн суулгах заавар нь одоогоор Docker Tools-ийн шаардлагын хуучирсан мэдээллийг агуулсан байгаа. үйл явцад саад учруулж болзошгүй).

Бүх гурван мэдээллийн багцад төслийн хэрэгжилтийг хамарсан шууд онлайн хувилбар байхгүй бололтой, гэхдээ BBC мэдээллийн мэдээллийн багцын үр дүнг эндээс чөлөөтэй асууж болно. http://zeus.robots.ox.ac.uk/bbc_search/.















