
Хиймэл оюун
Ганц асуултанд зориулсан GPT загварын хэлний загварыг бий болгох

Хятадын судлаачид GPT-3 маягийн байгалийн хэл боловсруулах системийг бий болгох эдийн засгийн аргыг боловсруулж, өндөр хэмжээний өгөгдлийн багцыг бэлтгэхэд цаг хугацаа, мөнгө их зардлаас зайлсхийсэн нь өсөн нэмэгдэж буй чиг хандлага нь AI-ийн энэ салбарыг саармагжуулах болно. FAANG тоглогчид болон өндөр түвшний хөрөнгө оруулагчдад.
Санал болгож буй хүрээ гэж нэрлэдэг Даалгаварт суурилсан хэлний загварчлал (TLM). Хэдэн тэрбум үг, олон мянган шошго, ангиудаас бүрдсэн асар том, нарийн төвөгтэй загварыг сургахын оронд TLM нь загвар дотор шууд асуулга агуулсан хамаагүй жижиг загварыг сургадаг.

Зүүн талд, их хэмжээний хэлний загварт зориулсан ердийн гипер масштабын арга; зөв, сэдэв тус бүр эсвэл асуулт тус бүрээр том хэлний корпусыг судлах TLM-ийн нимгэн арга. Эх сурвалж: https://arxiv.org/pdf/2111.04130.pdf
Олон төрлийн асуултанд хариулж чадах асар том, төвөгтэй ерөнхий хэлний загварыг бий болгохын оронд нэг асуултанд хариулахын тулд өвөрмөц NLP алгоритм эсвэл загварыг үр дүнтэйгээр бүтээдэг.
Судлаачид TLM-ийг туршихдаа шинэ арга нь Урьдчилан бэлтгэгдсэн хэлний загвартай төстэй эсвэл илүү сайн үр дүнд хүрдэг болохыг тогтоожээ. Роберта-Том, болон OpenAI-ийн GPT-3, Google-ийн ТРИЛЛИОН параметр шилжүүлэгч трансформатор гэх мэт NLP системүүд. загвар, Солонгос улсын HyperClover, AI21 Labs' Юрийн галавын 1, болон Microsoft Megatron-Turing NLG 530B.
Дөрвөн домайн дахь найман ангиллын өгөгдлийн багцыг TLM-ийн туршилтаар зохиогчид нэмэлтээр систем нь сургалтын FLOP-ийг бууруулдаг болохыг олж тогтоосон.секундэд хөвөх цэгийн үйл ажиллагаа) хоёр дарааллын дагуу шаардлагатай. Судлаачид TLM нь NLP загваруудыг орон нутагт бодитоор суулгах боломжгүй тул элит болж буй салбарыг "ардчилуулж" чадна гэж найдаж байгаа бөгөөд үүний оронд GPT-3-ын ард сууна үнэтэй болон OpenAI-ийн хязгаарлагдмал хандалтын API болон, одоо, Microsoft Azure.
Зохиогчид сургалтын хугацааг хоёр дарааллаар багасгах нь нэг өдрийн сургалтын зардлыг 1,000 гаруй GPU-г 8 цагийн турш 48 GPU болгон бууруулна гэж бичжээ.
Шинэ тайлан гэсэн гарчигтай Том хэмжээний урьдчилсан сургалтгүйгээр эхнээс нь NLP: Энгийн бөгөөд үр дүнтэй тогтолцоо, Бээжингийн Цинхуа их сургуулийн гурван судлаач, Хятадад төвтэй хиймэл оюун ухаан хөгжүүлэх Recurrent AI, Inc компанийн судлаач нар юм.
Боломжгүй хариултууд
The зардал Үр дүнтэй, бүх зорилготой хэлний загваруудыг сургах нь гүйцэтгэлтэй, үнэн зөв NLP-ийн соёлд хэр зэрэг тархах боломжит "дулааны хязгаар" гэж улам бүр тодорхойлогддог.
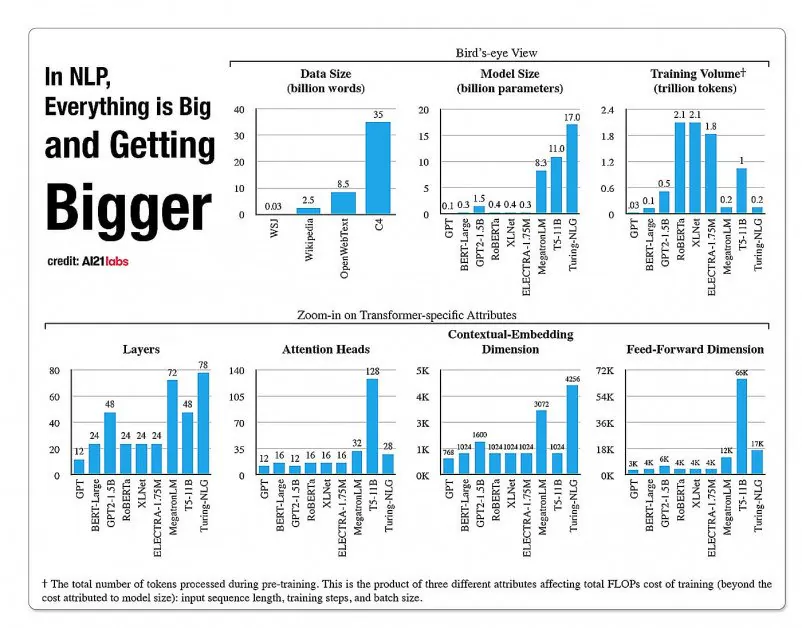
A2020 Labs-ийн 121 оны тайлангаас авсан NLP загварын архитектурын талбаруудын өсөлтийн статистик. Эх сурвалж: https://arxiv.org/pdf/2004.08900.pdf
2019 онд судлаач тооцсон сургахад 61,440 ам.доллар шаардлагатай XLNet загвар (Тухайн үед NLP даалгавруудад BERT-ийг ялсан гэж мэдээлсэн) 2.5 төхөөрөмж дээрх 512 цөм дээр 64 хоног ажилласан бол GPT-3 Тооцоолсон Өмнөх GPT-12-г сургахад 200 сая доллар зарцуулсан (хэдийгээр сүүлийн үеийн дахин тооцооллоор үүнийг одоо сургах боломжтой гэж мэдэгджээ. ердөө 4,600,000 доллар хамгийн хямд үүл GPU дээр) .
Асуулгад тулгуурласан өгөгдлийн дэд багцууд
Үүний оронд шинэ санал болгож буй архитектур нь хариулт өгөхийн тулд асуулгын хамт сургагдах томоохон хэлний мэдээллийн сангаас мэдээллийн дэд багцыг тодорхойлохын тулд асуулга ашиглан үнэн зөв ангилал, шошго, ерөнхий дүгнэлт гаргахыг эрмэлздэг. хязгаарлагдмал сэдвээр.
Зохиогчид хэлэхдээ:
'TLM нь хоёр үндсэн санаагаар өдөөгддөг. Нэгдүгээрт, хүн төрөлхтөн дэлхийн мэдлэгийн багахан хэсгийг ашиглан аливаа ажлыг эзэмшдэг (жишээлбэл, оюутнууд шалгалтанд орохын тулд дэлхийн бүх номнуудын дундаас хэдхэн бүлгийг үзэх хэрэгтэй).
"Тодорхой даалгаварт зориулж том корпуст их хэмжээний илүүдэл байгаа гэж бид таамаглаж байна. Хоёрдугаарт, хяналттай шошготой өгөгдлийн сургалт нь шошгогүй өгөгдөл дээрх хэлний загварчлалын зорилгыг оновчтой болгохоос илүү доод түвшний гүйцэтгэлд илүү үр ашигтай байдаг. Эдгээр сэдэл дээр үндэслэн TLM нь ерөнхий корпусын өчүүхэн хэсгийг авахын тулд даалгаврын өгөгдлийг асуулга болгон ашигладаг. Үүний дараа олж авсан өгөгдөл болон даалгаврын өгөгдлийг хоёуланг нь ашиглан хяналттай даалгаврын зорилго болон хэлний загварчлалын зорилгыг хамтад нь оновчтой болгоно.'
Зохиогчид өндөр үр дүнтэй NLP загварын сургалтыг боломжийн үнэтэй болгохоос гадна даалгаварт суурилсан NLP загварыг ашиглах нь хэд хэдэн давуу талтай гэж үзэж байна. Нэгд, судлаачид дарааллын урт, токенизаци, гиперпараметрийг тааруулах, өгөгдлийн дүрслэлд зориулсан тусгай стратеги ашиглан илүү уян хатан байдлыг эдлэх боломжтой.
Судлаачид мөн PLM-ийн хязгаарлагдмал урьдчилсан бэлтгэлийг (одоогийн хэрэгжилтэд өөрөөр төсөөлөөгүй) илүү олон талт байдал, сургалтын цаг хугацааны эсрэг ерөнхийлөлтөөс өөрчилсөн ирээдүйн эрлийз системийг хөгжүүлэхийг урьдчилан таамаглаж байна. Тэд энэ системийг домайн доторх XNUMX-shot ерөнхийлөлт аргуудыг ахиулах нэг алхам гэж үзэж байна.
Тест ба үр дүн
TLM-ийг биоанагаахын шинжлэх ухаан, мэдээ, тойм, компьютерийн шинжлэх ухаан гэсэн дөрвөн чиглэлээр найман даалгаварт ангиллын сорилтод туршиж үзсэн. Даалгавруудыг нөөц ихтэй, бага нөөцтэй гэсэн ангилалд хуваасан. Өндөр нөөцтэй ажлуудад 5,000 гаруй даалгаврын өгөгдөл багтсан, тухайлбал AGNews болон RCT, бусдын дунд; нөөц багатай ажлууд багтсан ChemProt болон ACL-ARC, Түүнчлэн HyperPartisan мэдээ илрүүлэх мэдээллийн багц.
Судлаачид Корпус-БЕРТ ба Корпус-Роберта гэсэн хоёр сургалтын багцыг боловсруулсан бөгөөд сүүлийнх нь өмнөхөөсөө арав дахин том хэмжээтэй юм. Туршилтууд нь урьдчилан бэлтгэгдсэн хэлний ерөнхий загваруудыг харьцуулсан БЕРТ (Google-ээс) болон Роберта (Фэйсбүүкээс) шинэ архитектур руу.
Энэхүү баримт бичигт TLM нь ерөнхий арга бөгөөд илүү өргөн цар хүрээтэй, илүү их хэмжээний орчин үеийн загваруудаас илүү хязгаарлагдмал хүрээ, хэрэглэх боломжтой байх ёстой ч энэ нь домэйнд дасан зохицох нарийн тааруулах аргуудтай ойролцоо ажиллах чадвартай болохыг баримт бичигт тэмдэглэжээ.

TLM-ийн гүйцэтгэлийг BERT болон RoBERTa-д суурилсан багцтай харьцуулсан үр дүн. Үр дүн нь гурван өөр сургалтын масштабын дундаж F1 оноог жагсааж, параметрийн тоо, сургалтын нийт тооцоолол (FLOP) болон сургалтын корпусын хэмжээг жагсаав.
Зохиогчид TLM нь PLM-тэй харьцуулж болохуйц эсвэл илүү сайн үр дүнд хүрэх чадвартай, шаардлагатай FLOP-ийг мэдэгдэхүйц бууруулж, сургалтын корпусын зөвхөн 1/16-ийг шаарддаг гэж дүгнэжээ. Дунд болон том хэмжээний хувьд TLM нь гүйцэтгэлийг дунджаар 0.59 ба 0.24 оноогоор сайжруулж, сургалтын мэдээллийн хэмжээг хоёр шатлалаар багасгаж чаддаг бололтой.
'Эдгээр үр дүн нь TLM нь PLM-ээс өндөр нарийвчлалтай бөгөөд илүү үр дүнтэй болохыг баталж байна. Нэмж дурдахад TLM нь илүү өргөн цар хүрээтэй үр ашгийн хувьд илүү давуу талыг олж авдаг. Энэ нь том хэмжээний PLM-үүдийг тодорхой даалгаварт ашиггүй ерөнхий мэдлэгийг хадгалахад сургасан байж болохыг харуулж байна.'















