
ეთიკის
ხელოვნური ინტელექტის ამჟამინდელი პრაქტიკა შესაძლოა საავტორო უფლებების ტროლების ახალი თაობის გააქტიურება იყოს

Huawei-სა და აკადემიას შორის ახალი კვლევითი თანამშრომლობა ვარაუდობს, რომ ხელოვნური ინტელექტისა და მანქანათმცოდნეობის სფეროში ყველაზე მნიშვნელოვანი მიმდინარე კვლევების დიდი ნაწილი შეიძლება სასამართლოში გამოჩნდეს, როგორც კი ის კომერციულად ცნობილი გახდება, რადგან მონაცემთა ნაკრები, რომელიც შესაძლებელს ხდის გარღვევას, ნაწილდება არასწორად. ლიცენზიები, რომლებიც არ პატივს სცემენ იმ საჯარო დომენების თავდაპირველ პირობებს, საიდანაც იქნა მიღებული მონაცემები.
ფაქტობრივად, ამას ორი თითქმის გარდაუვალი შესაძლო შედეგი აქვს: რომ ძალიან წარმატებული, კომერციული AI ალგორითმები, რომლებიც, როგორც ცნობილია, იყენებდნენ მონაცემთა ამგვარ ნაკრებებს, გახდებიან ოპორტუნისტული პატენტის ტროლების მომავალი სამიზნე, რომელთა საავტორო უფლებები არ იქნა დაცული მათი მონაცემების გაფუჭებისას; და რომ ორგანიზაციებს და ინდივიდებს შეეძლებათ გამოიყენონ იგივე სამართლებრივი ხარვეზები, რათა გააპროტესტონ მანქანათმცოდნეობის ტექნოლოგიების გავრცელება ან გავრცელება, რომელიც მათ მიაჩნიათ არასასიამოვნო.
ის ქაღალდი სახელდება შემიძლია გამოვიყენო ეს საჯაროდ ხელმისაწვდომი მონაცემთა ნაკრები კომერციული AI პროგრამული უზრუნველყოფის შესაქმნელად? დიდი ალბათობით არა, და არის Huawei Canada-სა და Huawei China-ს თანამშრომლობა, გაერთიანებული სამეფოს იორკის უნივერსიტეტთან და კანადის ვიქტორიას უნივერსიტეტთან ერთად.
ექვსიდან ხუთი (პოპულარული) ღია კოდის მონაცემთა ნაკრები ლეგალურად არ გამოიყენება
კვლევისთვის ავტორებმა ჰუავეის დეპარტამენტებს სთხოვეს აირჩიონ ყველაზე სასურველი ღია კოდის მონაცემთა ნაკრები, რომელთა გამოყენებაც სურთ კომერციულ პროექტებში, და პასუხებიდან შეარჩიეს ექვსი ყველაზე მოთხოვნადი მონაცემთა ნაკრები: CIFAR-10 (ქვეჯგუფი 80 მილიონი პატარა სურათი მონაცემთა ნაკრები, მას შემდეგ ამოღებული "დამამცირებელი ტერმინებისთვის" და "შეურაცხმყოფელი სურათებისთვის", თუმცა მისი წარმოებულები მრავლდება); IMAGEnet; ქალაქის პეიზაჟები (რომელიც შეიცავს ექსკლუზიურად ორიგინალურ მასალას); FFHQ; VGGFace2და MSCOCO.
იმის გასაანალიზებლად, იყო თუ არა შერჩეული მონაცემთა ნაკრები კომერციულ პროექტებში ლეგალური გამოყენებისთვის, ავტორებმა შეიმუშავეს ახალი მილსადენი, რათა თვალყური ადევნონ ლიცენზიების ჯაჭვს, რამდენადაც ეს შესაძლებელი იყო თითოეული ნაკრებისთვის, თუმცა მათ ხშირად უწევდათ მიმართონ ვებ-არქივის აღრიცხვას. იპოვნეთ ლიცენზიები ახლა ვადაგასული დომენებიდან და ზოგიერთ შემთხვევაში უნდა გამოეცნოთ ლიცენზიის სტატუსი უახლოესი ხელმისაწვდომი ინფორმაციის მიხედვით.
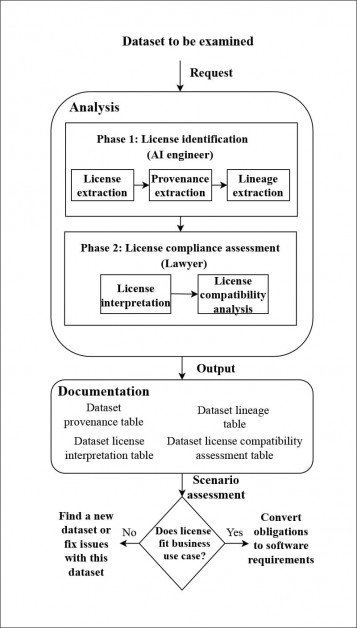
ავტორების მიერ შემუშავებული წარმოშობის მიკვლევის სისტემის არქიტექტურა. წყარო: https://arxiv.org/pdf/2111.02374.pdf
ავტორებმა დაადგინეს, რომ ლიცენზირებულია ექვსი მონაცემთა ნაკრებიდან ხუთზე "შეიცავს რისკებს, რომლებიც დაკავშირებულია მინიმუმ ერთ კომერციული გამოყენების კონტექსტთან":
„[ჩვენ] ვაკვირდებით, რომ MS COCO-ს გარდა, არც ერთი შესწავლილი ლიცენზია არ აძლევს პრაქტიკოსებს უფლებას განახორციელონ ხელოვნური ინტელექტის მოდელის კომერციალიზაცია, რომელიც მომზადებულია გაწვრთნილი AI მოდელის მონაცემებზე ან თუნდაც გამოსავალზე. ასეთი შედეგი ასევე ეფექტურად აფერხებს პრაქტიკოსებს ამ მონაცემთა ნაკრებებზე მომზადებული წინასწარ მომზადებული მოდელების გამოყენებაშიც კი. საჯაროდ ხელმისაწვდომი მონაცემთა ნაკრები და AI მოდელები, რომლებიც წინასწარ არის მომზადებული მათზე ფართოდ გამოიყენება კომერციულად. *
ავტორები დამატებით აღნიშნავენ, რომ ექვსი შესწავლილი მონაცემთა ნაკრებიდან სამმა შეიძლება დამატებით გამოიწვიოს ლიცენზიის დარღვევა კომერციულ პროდუქტებში, თუ მონაცემთა ნაკრები შეცვლილია, რადგან მხოლოდ MS-COCO იძლევა ამის საშუალებას. თუმცა მონაცემთა გაძლიერება და გავლენიანი მონაცემთა ნაკრების ქვეჯგუფები და სუპერ-კომპლექტები ჩვეულებრივი პრაქტიკაა.
CIFAR-10-ის შემთხვევაში, თავდაპირველმა შემდგენელებმა საერთოდ არ შექმნეს ლიცენზიის რაიმე ჩვეულებრივი ფორმა, მხოლოდ მოითხოვდნენ, რომ პროექტები, რომლებიც იყენებენ მონაცემთა ბაზას, შეიცავდეს ციტირებას თავდაპირველ ნაშრომზე, რომელიც თან ახლდა მონაცემთა ნაკრების გამოქვეყნებას, რაც წარმოადგენს შემდგომ დაბრკოლებას. მონაცემთა სამართლებრივი მდგომარეობა.
გარდა ამისა, მხოლოდ CityScapes მონაცემთა ნაკრები შეიცავს მასალას, რომელიც ექსკლუზიურად გენერირდება მონაცემთა ნაკრების შემქმნელების მიერ, ვიდრე არ არის „კურირებული“ (გაფხეკილი) ქსელის წყაროებიდან, CIFAR-10 და ImageNet-ით, რომლებიც იყენებენ მრავალ წყაროს, რომელთაგან თითოეული უნდა იყოს გამოკვლეული. და უკან დახევა, რათა შეიქმნას რაიმე სახის საავტორო უფლებების მექანიზმი (ან თუნდაც მნიშვნელოვანი უარი პასუხისმგებლობაზე).
No Way Out
არსებობს სამი ფაქტორი, რომელსაც კომერციული ხელოვნური ინტელექტის კომპანიები ეყრდნობიან, რათა დაიცვან ისინი სამართალწარმოებისგან იმ პროდუქტების შესახებ, რომლებიც იყენებდნენ საავტორო უფლებებით დაცულ შინაარსს მონაცემთა ნაკრებიდან თავისუფლად და ნებართვის გარეშე, AI ალგორითმების მოსამზადებლად. არცერთი მათგანი არ იძლევა დიდ (ან რაიმე) საიმედო გრძელვადიან დაცვას:
1: Laissez Faire ეროვნული კანონები
მიუხედავად იმისა, რომ მთავრობები მთელს მსოფლიოში იძულებულნი არიან დაამშვიდონ კანონები მონაცემთა შეგროვების შესახებ, რათა არ დაბრუნდნენ პერსპექტიული ხელოვნური ინტელექტისკენ (რომელიც ეყრდნობა რეალურ სამყაროს მონაცემთა დიდ მოცულობას, რომლისთვისაც საავტორო უფლებების რეგულარული დაცვა და ლიცენზირება არარეალური იქნება), მხოლოდ შეერთებული შტატები გთავაზობთ სრულ იმუნიტეტს ამ კუთხით, შესაბამისად სამართლიანი გამოყენების დოქტრინა – პოლიტიკა, რომელიც რატიფიცირებულია 2015 წელს დასკვნა ავტორის გილდიის წინააღმდეგ Google, Inc.-ის, რომელმაც დაადასტურა, რომ საძიებო გიგანტს შეეძლო თავისუფლად მიეღო საავტორო უფლებებით დაცული მასალა მისი Google Books პროექტისთვის, დარღვევაში დადანაშაულების გარეშე.
თუ სამართლიანი გამოყენების დოქტრინის პოლიტიკა ოდესმე შეიცვლება (ანუ სხვა საეტაპო შემთხვევის საპასუხოდ, რომელიც მოიცავს საკმარისად მაღალი უფლებამოსილების მქონე ორგანიზაციებს ან კორპორაციებს), ეს სავარაუდოდ ჩაითვლება აპრიორი სახელმწიფო საავტორო უფლებების დამრღვევი არსებული მონაცემთა ბაზების ექსპლუატაციის, ყოფილი გამოყენების დაცვის თვალსაზრისით; მაგრამ არა მიმდინარე სისტემების გამოყენება და განვითარება, რომლებიც გააქტიურდა საავტორო უფლებებით დაცული მასალის მეშვეობით შეთანხმების გარეშე.
ეს აყენებს სამართლიანი გამოყენების დოქტრინის ამჟამინდელ დაცვას ძალიან დროებით საფუძველზე და შესაძლოა, ამ სცენარში, მოითხოვოს დადგენილი, კომერციული მანქანური სწავლების ალგორითმების ფუნქციონირების შეწყვეტა იმ შემთხვევებში, როდესაც მათი წარმოშობა ჩართული იყო საავტორო უფლებებით დაცული მასალებით - თუნდაც იმ შემთხვევებში, როდესაც მოდელის Weights ახლა ეხებიან ექსკლუზიურად ნებადართულ კონტენტს, მაგრამ გაწვრთნილი იყვნენ (და სასარგებლო გახდა) არალეგალურად კოპირებულ კონტენტზე.
აშშ-ს გარეთ, როგორც ავტორები აღნიშნავენ ახალ ნაშრომში, პოლიტიკა ზოგადად ნაკლებად რბილია. გაერთიანებული სამეფო და კანადა მხოლოდ ანაზღაურებენ საავტორო უფლებებით დაცული მონაცემების არაკომერციული მიზნებისთვის გამოყენებას, ხოლო ევროკავშირის ტექსტისა და მონაცემთა მოპოვების კანონი (რომელიც მთლიანად არ არის აკრძალული ბოლო წინადადებები უფრო ფორმალური AI რეგულირებისთვის) ასევე გამორიცხავს AI სისტემების კომერციულ ექსპლუატაციას, რომლებიც არ შეესაბამება ორიგინალური მონაცემების საავტორო უფლებების მოთხოვნებს.
ეს უკანასკნელი შეთანხმებები ნიშნავს, რომ ორგანიზაციას შეუძლია მიაღწიოს დიდ წარმატებას სხვა ადამიანების მონაცემებით, მათ შორის – მაგრამ არა – მისგან ფულის გამომუშავების აზრამდე. ამ ეტაპზე, პროდუქტი ან ლეგალურად გამოაშკარავდებოდა, ან შეთანხმება უნდა შედგეს ფაქტიურად მილიონობით საავტორო უფლების მფლობელთან, რომელთაგან ბევრი ამჟამად მიუწვდომელია ინტერნეტის ცვალებადი ბუნების გამო - შეუძლებელი და მიუწვდომელი პერსპექტივა.
2: Caveat Emptor
იმ შემთხვევებში, როდესაც დამრღვევი ორგანიზაციები იმედოვნებენ, რომ დაადანაშაულებენ, ახალი ქაღალდი ასევე აღნიშნავს, რომ ყველაზე პოპულარული ღია კოდის მონაცემთა ნაკრების მრავალი ლიცენზია ავტომატურად ანაზღაურებს თავს საავტორო უფლებების დარღვევის შესახებ პრეტენზიების წინააღმდეგ:
მაგალითად, ImageNet-ის ლიცენზია ცალსახად მოითხოვს პრაქტიკოსებს კომპენსაცია გაუწიონ ImageNet-ის გუნდს მონაცემთა ნაკრების გამოყენების შედეგად წარმოქმნილი პრეტენზიებისგან. FFHQ, VGGFace2 და MS COCO მონაცემთა ნაკრებები მოითხოვს მონაცემთა გავრცელების ან მოდიფიცირების შემთხვევაში წარმოდგენილი იყოს იმავე ლიცენზიით.'
ფაქტობრივად, ეს აიძულებს მათ, ვინც იყენებს FOSS მონაცემთა ნაკრებებს, აითვისონ საავტორო უფლებებით დაცული მასალის გამოყენების ბრალდება, საბოლოო სასამართლო დავის ფონზე (თუმცა ის სულაც არ იცავს თავდაპირველ შემდგენელებს იმ შემთხვევაში, როდესაც არის „უსაფრთხო ნავსადგურის“ არსებული კლიმატი).
3: კომპენსაცია გაურკვევლობის მეშვეობით
მანქანათმცოდნეობის საზოგადოების თანამშრომლობითი ბუნება საკმაოდ ართულებს კორპორატიული ოკულტიზმის გამოყენებას იმ ალგორითმების არსებობის დასაფარად, რომლებიც სარგებლობდნენ საავტორო უფლებების დამრღვევი მონაცემთა ნაკრებით. გრძელვადიანი კომერციული პროექტები ხშირად იწყება ღია FOSS გარემოში, სადაც მონაცემთა ნაკრების გამოყენება ჩანაწერის საკითხია, GitHub-ზე და სხვა საჯაროდ ხელმისაწვდომ ფორუმებზე, ან სადაც პროექტის წარმოშობა გამოქვეყნებულია წინასწარ დაბეჭდილ ან რეცენზირებად ნაშრომებში.
მაშინაც კი, როცა ეს ასე არ არის, მოდელის ინვერსია is სულ უფრო უნარიანი მონაცემთა ნაკრების ტიპიური მახასიათებლების გამოვლენა (ან თუნდაც ცალსახად გამომავალი ზოგიერთი წყაროს მასალა), ან წარმოადგენს თავისთავად მტკიცებულებას, ან საკმარის ეჭვს დარღვევის შესახებ, რათა შესაძლებელი გახდეს სასამართლოს მიერ დადგენილი წვდომა ალგორითმის განვითარების ისტორიაზე და ამ შემუშავებაში გამოყენებული მონაცემთა ნაკრების დეტალებზე.
დასკვნა
ნაშრომი ასახავს ნებართვის გარეშე მოპოვებული საავტორო უფლებებით დაცული მასალის ქაოტურ და ad hoc გამოყენებას და სალიცენზიო ჯაჭვების სერიას, რომელიც ლოგიკურად მოჰყვა მონაცემების თავდაპირველ წყაროს, მოითხოვდა მოლაპარაკებებს საავტორო უფლებების ათასობით მფლობელთან, რომელთა ნამუშევრებიც იყო წარმოდგენილი. საიტების ეგიდით, ლიცენზირების პირობების ფართო სპექტრით, რაც გამორიცხავს წარმოებულ კომერციულ სამუშაოებს.
ავტორებმა დაასკვნეს:
„საჯარო ხელმისაწვდომი მონაცემთა ნაკრები ფართოდ გამოიყენება კომერციული AI პროგრამული უზრუნველყოფის შესაქმნელად. ამის გაკეთება შესაძლებელია, თუ [და] მხოლოდ იმ შემთხვევაში, თუ საჯაროდ ხელმისაწვდომ მონაცემთა ბაზასთან დაკავშირებული ლიცენზია იძლევა ამის უფლებას. თუმცა, საჯაროდ ხელმისაწვდომ მონაცემთა ნაკრებებთან დაკავშირებული ლიცენზიით გათვალისწინებული უფლებებისა და მოვალეობების გადამოწმება ადვილი არ არის. რადგან, ზოგჯერ ლიცენზია ან გაურკვეველია ან პოტენციურად არასწორი.'
კიდევ ერთი ახალი ნამუშევარი, სახელწოდებით იურიდიული მონაცემთა ნაკრების აგება, რომელიც გამოქვეყნდა 2 ნოემბერს სინგაპურის მენეჯმენტის უნივერსიტეტის გამოთვლითი სამართლის ცენტრიდან, ასევე ხაზს უსვამს მონაცემთა მეცნიერთა მიერ იმის აღიარების აუცილებლობას, რომ მონაცემთა დროებითი შეგროვების „ველური დასავლეთის“ ეპოქა დასასრულს უახლოვდება და ასახავს Huawei-ს რეკომენდაციებს. ქაღალდი უფრო მკაცრი ჩვევებისა და მეთოდოლოგიების დანერგვის მიზნით, რათა უზრუნველყოს, რომ მონაცემთა ბაზის გამოყენება არ გამოავლენს პროექტს სამართლებრივ შედეგებს, რადგან კულტურა დროთა განმავლობაში იცვლება და მანქანური სწავლების სექტორში მიმდინარე გლობალური აკადემიური აქტივობა ეძებს კომერციულ ანაზღაურებას წლების განმავლობაში ინვესტიციებზე. . ავტორი შენიშნავს *:
„საკანონმდებლო კორპუსი, რომელიც გავლენას ახდენს ML მონაცემთა ბაზაზე, გაიზრდება, იმ შეშფოთების ფონზე, რაც ამჟამინდელი კანონები გვთავაზობენ არასაკმარისი გარანტიები. AIA-ს პროექტი [ევროკავშირის ხელოვნური ინტელექტის აქტი], თუ და როდესაც მიღებული იქნება, მნიშვნელოვნად შეცვლის ხელოვნური ინტელექტისა და მონაცემთა მართვის ლანდშაფტს; სხვა იურისდიქციებმა შეიძლება მიბაძონ თავიანთი აქტებით. '
* ჩემი შიდა ციტატების ჰიპერბმულებად გადაქცევა















