
ხელოვნური ინტელექტი
არის არასაკმარისი კურირებული ჰიპერმასშტაბიანი AI მონაცემთა ნაკრები უფრო უარესი ვიდრე თავად ინტერნეტი?

მკვლევარებმა ირლანდიიდან, დიდი ბრიტანეთიდან და აშშ-დან გააფრთხილეს, რომ ჰიპერმასშტაბიანი AI სასწავლო მონაცემთა ნაკრების ზრდა საფრთხეს უქმნის მათი ინტერნეტ წყაროების ყველაზე ცუდი ასპექტების გავრცელებას, ამტკიცებენ, რომ ახლახან გამოქვეყნებული აკადემიური მონაცემთა ბაზის მახასიათებლებია. გაუპატიურების, პორნოგრაფიის, ავთვისებიანი სტერეოტიპების, რასისტული და ეთნიკური შეურაცხყოფის და სხვა უკიდურესად პრობლემური შინაარსის შემაშფოთებელი და აშკარა სურათები და ტექსტური წყვილი..
მკვლევარები თვლიან, რომ მასიური არასაკმარისად დამუშავებული ან არასწორად გაფილტრული მულტიმოდალური (მაგალითად, სურათები და სურათები) მონაცემთა ნაკრების ახალი ტალღა, სავარაუდოდ, უფრო საზიანოა ასეთი ნეგატიური შინაარსის ეფექტის გაძლიერების უნარით, რადგან მონაცემთა ნაკრები ინახავს გამოსახულებებს და სხვა კონტენტს. რომელიც მას შემდეგ შეიძლება ამოღებულ იქნა ონლაინ პლატფორმებიდან მომხმარებლის საჩივრების, ადგილობრივი მოდერაციის ან ალგორითმების მეშვეობით.
ისინი ასევე აღნიშნავენ, რომ შეიძლება წლები დასჭირდეს - ImageNet-ის ძლევამოსილი მონაცემთა ნაკრების შემთხვევაში, მთელი ათწლეული - გრძელვადიანი საჩივრების განხილვას მონაცემთა შიგთავსის შესახებ, და რომ ეს შემდგომი გადასინჯვები ყოველთვის არ აისახება მათგან მიღებული მონაცემთა ახალ ნაკრებებშიც კი. .
ის ქაღალდი, სახელწოდებით მულტიმოდალური მონაცემთა ნაკრები: მიზოგინია, პორნოგრაფია და ავთვისებიანი სტერეოტიპები, მოდის დუბლინის და ლეროს საუნივერსიტეტო კოლეჯის მკვლევარების, ედინბურგის უნივერსიტეტისა და UnifyID ავტორიზაციის პლატფორმის მთავარი მეცნიერის მიერ.
თუმცა ნამუშევარი ფოკუსირებულია ბოლო გამოშვებაზე CLIP- გაფილტრული LAION-400M მონაცემთა ბაზა, ავტორები კამათობენ ზოგადი ტენდენციის წინააღმდეგ მზარდი რაოდენობის მონაცემების გადაყრის მანქანური სწავლების ჩარჩოებში, როგორიცაა ნერვული ენის მოდელი GPT-3, და ამტკიცებენ, რომ შედეგებზე ორიენტირებული უკეთესი დასკვნისკენ (და თუნდაც ხელოვნური ზოგადი ინტელექტისკენ [AGI)კენ] ), იწვევს მონაცემთა საზიანო წყაროების ad hoc გამოყენებას საავტორო უფლებების დაუდევრობით ზედამხედველობით; ზიანის გამოწვევისა და ხელშეწყობის პოტენციალი; და შესაძლებლობა არა მხოლოდ გააგრძელოს უკანონო მონაცემები, რომლებიც სხვაგვარად შეიძლება გაქრეს საჯარო დომენიდან, არამედ რეალურად ჩართოს ასეთი მონაცემების მორალური მოდელები ქვედა დინებაში ხელოვნური ინტელექტის განხორციელებებში.
LAION-400მ
გასულ თვეში გამოქვეყნდა LAION-400M მონაცემთა ბაზა, რომელიც დაემატა მრავალმოდალური, ენობრივი მონაცემთა ნაკრების მზარდ რაოდენობას, რომლებიც ეყრდნობა ჩვეულებრივი სეირნობა საცავი, რომელიც არღვევს ინტერნეტს განურჩევლად და გადასცემს პასუხისმგებლობას ფილტრაციისა და კურირების პროექტებზე, რომლებიც იყენებენ მას. მიღებული მონაცემთა ნაკრები შეიცავს 400 მილიონ ტექსტს/სურათის წყვილს.
LAION-400M არის Google AI-ის დახურული WIT-ის ღია კოდის ვარიანტი (WebImageText) მონაცემთა ბაზა გამოვიდა 2021 წლის მარტში და შეიცავს ტექსტ-სურათის წყვილებს, სადაც მონაცემთა ბაზაში არსებული სურათი ასოცირდება თანმხლებ ექსპლიციტურ ან მეტამონაცემთა ტექსტთან (მაგალითად, გამოსახულების ალტერნატიული ტექსტი ვებ გალერეაში). ეს საშუალებას აძლევს მომხმარებლებს განახორციელონ ტექსტზე დაფუძნებული გამოსახულების მოძიება, გამოავლინონ ასოციაციები, რომლებიც ფუძემდებლური AI ჩამოაყალიბა ამ დომენებთან დაკავშირებით (ე.ი. "ცხოველი", "ველოსიპედი", "ადამიანი", "კაცი", "ქალი").
ეს ურთიერთობა სურათსა და ტექსტს შორის და კოსინუსური მსგავსება, რომელსაც შეუძლია მიკერძოების ჩასმა შეკითხვის შედეგებში, არის ქაღალდის მოწოდების საფუძველი გაუმჯობესებული მეთოდოლოგიებისთვის, რადგან LAION-400M მონაცემთა ბაზაში ძალიან მარტივმა შეკითხვებმა შეიძლება გამოავლინოს მიკერძოება.
მაგალითად, პიონერი ქალი ასტრონავტის ეილინ კოლინზის გამოსახულება scitkit-გამოსახულებების ბიბლიოთეკაში იღებს ორ ასოცირებულ წარწერას LAION-400M-ში: "ეს არის ასტრონავტის პორტრეტი ამერიკის დროშით" მდე "ეს არის გაღიმებული დიასახლისის ფოტო ნარინჯისფერ კომბინეზონში ამერიკის დროშით".

ამერიკელი ასტრონავტი ეილინ კოლინზი იღებს ორ სრულიად განსხვავებულ შეხედულებას მის მიღწევებზე, როგორც პირველი ქალი კოსმოსში LAION-400M-ის ქვეშ. წყარო: https://arxiv.org/pdf/2110.01963.pdf
მოხსენებული კოსინუსური მსგავსება, რომელიც ორივე წარწერას შესაძლებელს ხდის, ძალიან ახლოს არის ერთმანეთთან და ავტორები ამტკიცებენ, რომ ასეთი სიახლოვე აიძულებს ხელოვნური ინტელექტის სისტემებს, რომლებიც იყენებენ LAION-400M-ს, შედარებით სავარაუდოა, რომ წარმოადგენენ ორივეს, როგორც შესაფერის წარწერას.
პორნოგრაფია კვლავ მაღლა დგას
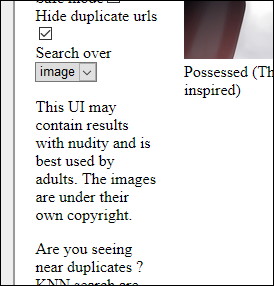
LAION-400M-მა შექმნა საძიებო ინტერფეისი ხელმისაწვდომია, სადაც „უსაფრთხო ძიების“ ღილაკის მოხსნა ცხადყოფს, რამდენად დომინირებს პორნოგრაფიული გამოსახულებები და ტექსტური ასოციაციები ლეიბლებსა და კლასებში. Მაგალითად, ეძებს "მონაზონი" (NSFW თუ შემდგომში გამორთავთ უსაფრთხო რეჟიმს) მონაცემთა ბაზაში აბრუნებს შედეგებს, რომლებიც ძირითადად დაკავშირებულია საშინელებასთან, კოსპლეისთან და კოსტიუმებთან, ძალიან ცოტა რეალური მონაზვნებით.
Safe Mode-ის გამორთვა იმავე ძიებაში გამოავლენს პორნოგრაფიულ სურათებს, რომლებიც დაკავშირებულია ტერმინთან, რაც ნებისმიერ არაპორნო სურათს უბიძგებს ძიების შედეგების გვერდზე და ცხადყოფს, რამდენად დიდი წონა ანიჭებს LAION-400M პორნო სურათებს, რადგან ისინი გავრცელებულია ტერმინით „მონაზონი“ ონლაინ წყაროებში.
Safe Mode-ის ნაგულისხმევი გააქტიურება მატყუარაა ონლაინ საძიებო ინტერფეისში, რადგან ის წარმოადგენს ინტერფეისის უცნაურობას, ფილტრს, რომელიც არა მხოლოდ აუცილებლად გააქტიურდება მიღებული ხელოვნური ინტელექტის სისტემებში, არამედ განზოგადებულია "nun" დომენში. რომელიც არც ისე ადვილად იფილტრება ან არ გამოირჩევა (შედარებით) SFW შედეგებისგან ალგორითმული გამოყენების თვალსაზრისით.
ნაშრომში წარმოდგენილია ბუნდოვანი მაგალითები სხვადასხვა საძიებო ტერმინებში, ბოლოში დამატებით მასალებში. ისინი არ შეიძლება აქ წარმოდგენილი იყოს ტექსტის ენის გამო, რომელიც თან ახლავს ბუნდოვან ფოტოებს, მაგრამ მკვლევარები აღნიშნავენ იმ ზარალს, რაც მათზე გადაიღო სურათების შესწავლამ და დაბინდვამ და აცნობიერებენ, რომ ასეთი მასალის მოწესრიგება დიდი ზომის ადამიანთა ზედამხედველობისთვის. - მასშტაბის მონაცემთა ბაზები:
ჩვენ (ისევე, როგორც ჩვენს კოლეგებს, რომლებიც დაგვეხმარნენ) განვიცადეთ სხვადასხვა დონის დისკომფორტი, გულისრევა და თავის ტკივილი მონაცემთა შემოწმების პროცესში. გარდა ამისა, ამ ტიპის ნამუშევარი არაპროპორციულად აწყდება მნიშვნელოვან ნეგატიურ კრიტიკას აკადემიური ხელოვნური ინტელექტის სფეროში, რაც არა მხოლოდ დამატებით ემოციურ ზარალს მატებს ასეთი მონაცემთა ნაკრების შესწავლისა და ანალიზის ისედაც მძიმე ამოცანას, არამედ ხელს უშლის მსგავსი სამომავლო სამუშაოების შესრულებას, რაც დიდ ზიანს აყენებს ხელოვნური ინტელექტის სფერო და ზოგადად საზოგადოება.'
მკვლევარები ამტკიცებენ, რომ მიუხედავად იმისა, რომ ადამიანის ციკლში მკურნალობა ძვირია და დაკავშირებულია პირად ხარჯებთან, ავტომატური ფილტრაციის სისტემები, რომლებიც შექმნილია ასეთი მასალის ამოსაღებად ან სხვაგვარად გამოსასწორებლად, აშკარად არ არის ადეკვატური ამოცანის შესასრულებლად, რადგან NLP სისტემებს უჭირთ შეურაცხყოფის იზოლაცია ან დისკონტირება. მასალა, რომელიც შეიძლება დომინირებდეს გახეხილ მონაცემთა ბაზაში და შემდგომში აღქმული იყოს მნიშვნელოვანი მოცულობის გამო.
აკრძალული კონტენტის განმტკიცება და საავტორო უფლებების დაცვის მოხსნა
ნაშრომი ამტკიცებს, რომ ამ ბუნების არასაკმარისად დამუშავებული მონაცემთა ნაკრები „დიდი ალბათობით“ გააგრძელებს უმცირესობის ინდივიდების ექსპლუატაციას და ასახავს იმას, აქვს თუ არა უფლება ღია კოდის მონაცემთა მსგავს პროექტებს, იურიდიულად თუ მორალურად, შეაჩერონ პასუხისმგებლობა მასალაზე. საბოლოო მომხმარებელი:
„ფიზიკურ პირებს შეუძლიათ წაშალონ თავიანთი მონაცემები ვებსაიტიდან და ჩათვალონ, რომ ისინი სამუდამოდ გაქრა, მაშინ როცა ის შეიძლება კვლავ არსებობდეს რამდენიმე მკვლევარის და ორგანიზაციის სერვერებზე. ჩნდება კითხვა, ვინ არის პასუხისმგებელი მონაცემთა ნაკრებიდან გამოყენებისგან ამოღებაზე? LAION-400M-ისთვის შემქმნელებმა ეს დავალება გადასცეს მონაცემთა ნაკრების მომხმარებელს. იმის გათვალისწინებით, რომ ასეთი პროცესები მიზანმიმართულად რთულდება და საშუალო მომხმარებელს არ გააჩნია ტექნიკური ცოდნა, რომ ამოიღოს თავისი მონაცემები, არის ეს გონივრული მიდგომა?'
ისინი ასევე ამტკიცებენ, რომ LAION-400M შეიძლება არ იყოს შესაფერისი გამოსაშვებად მისი მიღებული Creative Common CC-BY 4.0 ლიცენზიის მოდელის მიხედვით, მიუხედავად პოტენციური უპირატესობებისა დიდი მასშტაბის მონაცემთა ნაკრების დემოკრატიზაციისთვის, რომელიც ადრე იყო კარგად დაფინანსებული კომპანიების ექსკლუზიური დომენი, როგორიცაა Google და. OpenAI.
LAION-400M დომენი ამტკიცებს, რომ მონაცემთა ნაკრების სურათები „საკუთარი საავტორო უფლებების ქვეშაა“ – „გამტარების“ მექანიზმი, რომელიც დიდწილად ჩართულია ბოლო წლების სასამართლო გადაწყვეტილებებითა და მთავრობის სახელმძღვანელოებით, რომლებიც ფართოდ ამტკიცებენ ვებ – სკრაპირებას კვლევის მიზნებისთვის. წყარო: https://rom1504.github.io/clip-retrieval/
ავტორები ვარაუდობენ, რომ ფართომასშტაბიანი (მაგ. ბრბოდან მოპოვებული მოხალისეები) შეიძლება გადაჭრას მონაცემთა ზოგიერთი საკითხი და რომ მკვლევარებმა შეიმუშაონ გაუმჯობესებული ფილტრაციის ტექნიკა.
„მიუხედავად ამისა, აქ მონაცემთა სუბიექტის უფლებები მიუწვდომელია. უგუნური და სახიფათოა ასეთი ფართომასშტაბიანი მონაცემთა ნაკრების თანდაყოლილი ზიანის ზემოქმედება და მათი გამოყენება სამრეწველო და კომერციულ გარემოში. ლიცენზიის სქემის პასუხისმგებლობა, რომლის მიხედვითაც მონაცემთა ბაზა არის მოწოდებული, ეკისრება მხოლოდ მონაცემთა ნაკრების შემქმნელს.
ჰიპერმასშტაბიანი მონაცემების დემოკრატიზაციის პრობლემები
ნაშრომი ამტკიცებს, რომ ვიზუალურ-ლინგვისტური მონაცემთა ნაკრები, როგორც LAION-400M, ადრე მიუწვდომელი იყო დიდი ტექნიკური კომპანიების გარეთ და შეზღუდული რაოდენობის კვლევითი ინსტიტუტები, რომლებიც ფლობენ რესურსებს მათი შეგროვების, კურირებისა და დამუშავებისთვის. ისინი ასევე მიესალმებიან ახალი გამოშვების სულს და აკრიტიკებენ მის შესრულებას.
ავტორები ამტკიცებენ, რომ „დემოკრატიზაციის“ მიღებული განმარტება, როგორც ეს ეხება ღია კოდის ჰიპერმასშტაბიან მონაცემთა ნაკრებებს, ძალიან შეზღუდულია და „ვერ ითვალისწინებს მოწყვლადი პირებისა და თემების უფლებებს, კეთილდღეობასა და ინტერესებს, რომელთაგან ბევრი, სავარაუდოდ, ყველაზე მეტად დაზარალდება ამ მონაცემთა ნაკრებისა და მასზე მომზადებული მოდელების ქვედა დინებაში ზემოქმედებისგან“.
მას შემდეგ, რაც GPT-3 მასშტაბის ღია კოდის მოდელების შემუშავება საბოლოოდ შექმნილია იმისთვის, რომ გავრცელდეს მილიონობით (და პროქსით, შესაძლოა მილიარდობით) მომხმარებლებზე მთელს მსოფლიოში, და ვინაიდან კვლევით პროექტებს შეუძლიათ მიიღონ მონაცემთა ნაკრები მათ შემდგომ რედაქტირებამდე ან თუნდაც წაშლამდე. პრობლემები შემუშავებული იყო მოდიფიკაციების გადასაჭრელად, ავტორები ამტკიცებენ, რომ არასაკმარისად დამუშავებული მონაცემთა ნაკრების უყურადღებო გამოშვება არ უნდა იქცეს ღია კოდის მანქანური სწავლების ჩვეულ ფუნქციად.
ჯინის ბოთლში დაბრუნება
ზოგიერთი მონაცემთა ნაკრები, რომლებიც ჩახშობილი იქნა დიდი ხნის შემდეგ, რაც მათი შინაარსი გადავიდა, შესაძლოა განუყოფლად, გრძელვადიან AI პროექტებში, შედის Duke MTMC (Multi-Target, Multi-Camera) მონაცემთა ნაკრები, რომელიც საბოლოოდ გაუქმდა იმის გამო განმეორებითი შეშფოთება უფლებადამცველი ორგანიზაციებისგან ჩინეთის რეპრესიული ხელისუფლების მიერ მისი გამოყენების ირგვლივ; Microsoft Celeb (MS-Celeb-1M), 10 მილიონი "ვარსკვლავების" სახის გამოსახულების ნაკრები, რომელიც მოხდა მოიცავდნენ ჟურნალისტებს, აქტივისტებს, პოლიტიკის შემქმნელებს და მწერლებს, რომელთა გამოქვეყნებაში ბიომეტრიული მონაცემების გამოქვეყნება მწვავედ გააკრიტიკეს; და Tiny Images მონაცემთა ნაკრები, ამოღებულია 2020 წელს თვით აღიარებული „მიკერძოებულობის, შეურაცხმყოფელი და მავნე გამოსახულებებისა და დამამცირებელი ტერმინოლოგიისთვის“.
რაც შეეხება მონაცემთა ნაკრებებს, რომლებიც შეიცვალა და არა ამოღებული კრიტიკის შემდეგ, მაგალითები მოიცავს ძალიან პოპულარულ ImageNet მონაცემთა ბაზას, რომელიც, მკვლევარები აღნიშნავენ, ათი წელი დასჭირდა (2009-2019) იმოქმედოს განმეორებით კრიტიკაზე კონფიდენციალურობისა და არაიმიჯნური კლასების გარშემო.
ნაშრომი აღნიშნავს, რომ LAION-400M ეფექტურად აბრუნებს ამ დილატაციურ გაუმჯობესებებსაც კი, „ძირითადად უგულებელყოფს“ ImageNet-ის წარმომადგენლობაში ზემოხსენებულ ვერსიებს ახალ გამოცემაში და აკვირდება უფრო ფართო ტენდენციას ამ კუთხით*:
'ეს ხაზგასმულია უფრო დიდი მონაცემთა ნაკრების გაჩენაში, როგორიცაა Tencent ML-გამოსახულებების მონაცემთა ნაკრები (2020 წლის თებერვალში), რომელიც მოიცავს მათ უმეტესობას არაწარმოსახვადი კლასები, მოდელების მუდმივი ხელმისაწვდომობა, რომლებიც გაწვრთნილი იქნა სრულ ImageNet-21k მონაცემთა ბაზაზე საცავებში როგორიცაა TF-hub, გაუფილტრავი-ImageNet-21k-ის უწყვეტი გამოყენება უახლეს SotA მოდელებში (როგორიცაა Google-ის უახლესი EfficientNetV2 და CoAtNet მოდელები) და მკაფიო განცხადებები, რომლებიც საშუალებას იძლევა გამოიყენონ გაუფილტრავი-ImageNet-21k წინასწარი მომზადება რეპუტაციის კონკურსებში როგორიცაა LVIS გამოწვევა 2021.
„ჩვენ ხაზს ვუსვამთ ამ მნიშვნელოვან დაკვირვებას: ImageNet-ის დონის გუნდს, რომელიც მართავს 15 მილიონზე ნაკლებ სურათს, იბრძოდა და წარუმატებელი აღმოჩნდა ამ დეტოქსიკაციის მცდელობებში.
„საგულისხმო ძალისხმევის მასშტაბი, რომელიც საჭიროა ამ მასიური მულტიმოდალური მონაცემთა ნაკრებისა და ქვედა დინების მოდელების გაწვრთნილი მონაცემთა ბაზაზე, რომელიც მოიცავს პოტენციურად მილიარდობით გამოსახულების წარწერის წყვილს, უდავოდ ასტრონომიული იქნება.
* ავტორის შიდა ციტატების ჩემი გადაყვანა ჰიპერბმულებად.















