AI 101
ディープラーニングにおけるRNNとLSTMとは何か?
自然言語処理とAIチャットボットの多くの驚異的な進歩は、再帰型ニューラルネットワーク(RNN)と長短期記憶(LSTM)ネットワークによって推進されています。RNNとLSTMは、時系列データを処理することができる特殊なニューラルネットワークアーキテクチャです。LSTMは、基本的にRNNの改良版であり、より長いデータシーケンスを解釈することができます。RNNとLSTMの構造と、どのようにして高度な自然言語処理システムを作成することができるかを見てみましょう。
フィードフォワードニューラルネットワークとは何か?
LSTMと畳み込みニューラルネットワーク(CNN)について話す前に、ニューラルネットワークの一般的な形式について話しましょう。
ニューラルネットワークは、データを分析し、パターンを学習するように設計されています。そうして、他のデータにこれらのパターンを適用し、新しいデータを分類することができます。ニューラルネットワークは、3つのセクションに分かれています。入力層、隠れ層(または複数の隠れ層)、および出力層です。
入力層は、データをニューラルネットワークに入力するものです。隠れ層は、データのパターンを学習するものです。隠れ層は、入力層と出力層に「重み」と「バイアス」で接続されています。これらは、データポイント間の関係についての仮定です。これらの重みは、トレーニング中に調整されます。ネットワークがトレーニングされると、モデルはトレーニングデータ(出力値)についての推測を実際のトレーニングラベルと比較します。トレーニングの過程で、ネットワークはデータポイント間の関係を予測する精度が高まるはずです。深層ニューラルネットワークは、多くの層を持つネットワークです。層とノードが多くなるほど、モデルはデータのパターンを認識する能力が高まります。
通常のフィードフォワードニューラルネットワークは、上で説明したように、しばしば「密なニューラルネットワーク」と呼ばれます。これらの密なニューラルネットワークは、さまざまなネットワークアーキテクチャと組み合わせて、さまざまな種類のデータを解釈することができます。
RNN(再帰型ニューラルネットワーク)とは何か?

再帰型ニューラルネットワークは、フィードフォワードニューラルネットワークの一般的な原理を取り入れ、モデルに内部メモリを与えることで、時系列データを処理することができます。RNNの名前の「再帰」部分は、入力と出力がループすることから来ています。ネットワークの出力が生成されると、出力はコピーされ、ネットワークに再び入力として戻されます。決定を下す際には、現在の入力と出力だけではなく、前の入力も考慮されます。言い換えると、ネットワークの初期入力がXで、出力がHの場合、HとX1(データシーケンスの次の入力)は、次のラウンドの学習のためにネットワークにフィードされます。こうして、ネットワークがトレーニングされると、データのコンテキスト(前の入力)が保存されます。
このアーキテクチャの結果は、RNNが時系列データを処理することができるということです。ただし、RNNにはいくつかの問題があります。RNNは、消えていく勾配と爆発する勾配の問題に悩まされています。
RNNが解釈できるシーケンスの長さは、LSTMと比較してかなり限られています。
LSTM(長短期記憶)ネットワークとは何か?
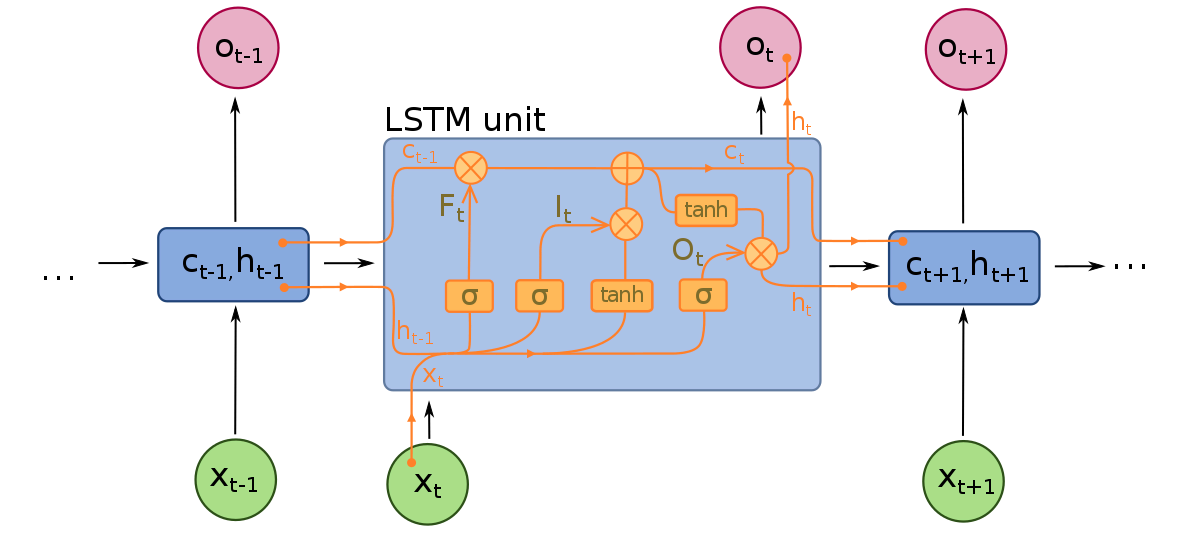
長短期記憶ネットワークは、RNNの拡張版と見なすことができます。LSTMは、入力のコンテキストを保存する概念をさらに適用しています。ただし、LSTMは、より長いデータシーケンスを解釈することができるように、いくつかの重要な点で改良されています。LSTMの改良は、消えていく勾配の問題に対処し、LSTMがより長い入力シーケンスを考慮することができるようにしています。

LSTMモデルは、3つの異なるコンポーネント、またはゲートで構成されています。入力ゲート、出力ゲート、忘却ゲートがあります。RNNと同様に、LSTMは、前のタイムステップからの入力を考慮して、モデルのメモリと入力重みを変更します。入力ゲートは、どの値が重要で、モデルを通過する必要があるかについての決定を下します。入力ゲートでは、シグモイド関数が使用され、値を通過させるかどうかを決定します。0は値をドロップし、1は値を保存します。ここでは、タンハイパボリック関数も使用され、入力値の重要性を-1から1の範囲で決定します。
現在の入力とメモリ状態が考慮された後、出力ゲートは、次のタイムステップに値をプッシュするかどうかを決定します。出力ゲートでは、値が分析され、-1から1の範囲で重要性が割り当てられます。これにより、データが次のタイムステップの計算に進む前に、データが規制されます。最後に、忘却ゲートの役割は、モデルが決定を下すために不要な情報をドロップすることです。忘却ゲートでは、値に対してシグモイド関数が使用され、0(忘れる)と1(保存)の間の数字が出力されます。
LSTMニューラルネットワークは、時系列ワードデータを解釈する特殊なLSTM層と、上で説明した密な層で構成されています。データがLSTM層を通過すると、密な層に進みます。








