人工知能
AudioSep : 任意のものを分離する
LASSまたはLanguage-queried Audio Source Separationは、CASAまたはComputational Auditory Scene Analysisの新しいパラダイムであり、自然言語クエリを使用して、与えられたオーディオの混合からターゲット音を分離することを目的としています。LASSフレームワークは、音楽インストルメンタルなどの特定のオーディオソースに対する望ましいパフォーマンスを達成する点で、過去数年で大幅に進歩しましたが、オープンドメインではターゲットオーディオを分離することができません。
AudioSepは、LASSフレームワークの現在の限界を解決することを目的とした基礎モデルであり、自然言語クエリを使用してターゲットオーディオを分離します。AudioSepフレームワークの開発者は、モデルを大規模な多モーダルデータセットで広範に訓練し、音楽インストルメンタル分離、オーディオイベント分離、スピーチ強化など、さまざまなオーディオタスクのパフォーマンスを評価しました。AudioSepの初期パフォーマンスはベンチマークを満たしており、印象的なゼロショット学習能力と強力なオーディオ分離パフォーマンスを示しています。
この記事では、AudioSepフレームワークの構造、訓練と評価に使用されるデータセット、AudioSepモデルが動作する際に関与する基本概念について、より深く掘り下げて説明します。まず、CASAフレームワークの基本的な紹介から始めましょう。
CASA、USS、QSS、LASSフレームワーク:AudioSepの基礎
CASAまたはComputational Auditory Scene Analysisフレームワークは、開発者が人間の聴覚システムと同様の方法で複雑な音環境を認識できるマシンリスニングシステムを設計するために使用されるフレームワークです。音源分離、特にターゲット音源分離は、CASAフレームワーク内での基本的な研究分野であり、「カクテルパーティーの問題」または個々のオーディオソースのレコーディングまたはファイルから実世界のオーディオレコーディングを分離することを目的としています。音源分離の重要性は、主に音楽ソース分離、オーディオソース分離、スピーチ強化、ターゲット音源識別など、広範な応用に帰着します。
過去に行われた音源分離に関する大部分の研究は、音楽分離やスピーチ分離などの1つまたは複数のオーディオソースの分離に主に焦点を当てています。USSまたはUniversal Sound Separationという名前の新しいモデルは、実世界のオーディオレコーディング内の任意の音を分離することを目的としています。ただし、世界に存在するさまざまな音源の広範な存在により、オーディオミキサーよりもすべての音源を分離することは、特にリアルタイムで動作する実世界のアプリケーションの場合、課題的で制限的なタスクです。
USS方法の実行可能な代替手段は、QSSまたはQuery-based Sound Separation方法であり、特定のクエリに基づいてオーディオミキサーよりターゲット音源を分離することを目的としています。これにより、QSSフレームワークは、開発者とユーザーが、オーディオミキサーより必要なオーディオソースを、必要に応じて抽出できるようにします。これにより、QSS方法は、メディアコンテンツ編集やオーディオ編集などのデジタル実世界アプリケーションにとって、より実用的な解決策となります。
さらに、開発者は、ターゲット音源をオーディオミキサーより分離するために、ターゲット音源の自然言語説明を使用するLASSフレームワークまたはLanguage-queried Audio Source SeparationフレームワークというQSSフレームワークの拡張を提案しました。LASSフレームワークは、ユーザーが自然言語の命令セットを使用してターゲットオーディオソースを抽出できるようにするため、デジタルオーディオアプリケーションに広範な応用を持つ強力なツールになる可能性があります。伝統的なオーディオクエリまたはビジョンクエリ方法と比較して、オーディオ分離のために自然言語命令を使用することは、柔軟性を追加し、クエリ情報の取得をより簡単で便利にするという大きな利点があります。さらに、事前に定義された命令またはクエリセットを使用するラベルクエリベースのオーディオ分離フレームワークと比較して、LASSフレームワークは入力クエリの数を制限せず、オープンドメインにシームレスに一般化できる柔軟性があります。
もともと、LASSフレームワークは、ラベル付きオーディオテキストペアデータのセットで訓練された教師あり学習に依存しています。ただし、このアプローチの主な問題は、ラベル付きオーディオテキストデータの入手可能性が限られていることです。LASSフレームワークの依存関係をラベル付きオーディオテキストラベルデータに減らすために、モデルは多モーダル監視学習アプローチを使用して訓練されます。多モーダル監視アプローチを使用する主な目的は、CLIPまたはContrastive Language Image Pre Trainingモデルなどの多モーダル対比学習モデルをフレームワークのクエリエンコーダーとして使用することです。CLIPフレームワークは、テキスト埋め込みをオーディオやビジョンなどの他のモダリティと同期できるため、開発者はデータ豊富なモダリティを使用してLASSモデルを訓練し、ゼロショット設定でテキストデータと干渉できるようにします。ただし、現在のLASSフレームワークは、小規模なデータセットを使用して訓練されており、数百の潜在的なドメインへのLASSフレームワークの応用はまだ探索されていません。
LASSフレームワークが直面している現在の限界を解決するために、開発者は、自然言語説明を使用してオーディオミキサーより音を分離することを目的とした基礎モデルであるAudioSepを導入しました。AudioSepの現在の焦点は、オープンドメインアプリケーションでLASSモデルを一般化できる、大規模な多モーダルデータセットを活用する事前訓練済みの音源分離モデルを開発することです。要約すると、AudioSepモデルは、「自然言語クエリまたは説明を使用してオープンドメインで普遍的な音源分離を行うための基礎モデルであり、大規模なオーディオおよび多モーダルデータセットで訓練されています」です。
AudioSep:主要コンポーネントとアーキテクチャ
AudioSepフレームワークのアーキテクチャは、2つの主要コンポーネントで構成されています。テキストエンコーダーと分離モデルです。
テキストエンコーダー
AudioSepフレームワークは、CLIPまたはContrastive Language Image Pre Trainingモデル、またはCLAPまたはContrastive Language Audio Pre Trainingモデルのテキストエンコーダーを使用して、自然言語クエリ内でテキスト埋め込みを抽出します。入力テキストクエリは、トークンのシーケンス「N」で構成されており、テキストエンコーダーによって処理されて、入力言語クエリのテキスト埋め込みが抽出されます。テキストエンコーダーは、トランスフォーマーブロックのスタックを使用して入力テキストトークンをエンコードし、出力表現はトランスフォーマーレイヤーを通過した後集約され、固定長のD次元ベクトル表現が開発されます。ここで、DはCLAPまたはCLIPモデルの次元に対応します。テキストエンコーダーは訓練期間中は凍結されています。
CLIPモデルは、対比学習を使用して大規模な画像テキストペアデータセットで事前訓練されており、そのテキストエンコーダーは、テキスト説明を、ビジュアル表現と共有するセマンティック空間にマッピングすることを学習します。AudioSepがCLIPのテキストエンコーダーを使用することで得られる利点は、視覚埋め込みを代替手段として使用して、ラベル付けされたオーディオテキストペアデータの必要性なしにLASSモデルを訓練できることです。
CLAPモデルはCLIPモデルと同様に機能し、対比学習目的を使用して、テキストエンコーダーとオーディオエンコーダーを使用してオーディオと言語を接続し、テキストとオーディオの説明を、テキストとオーディオの潜在的な空間に結び付けます。
分離モデル
AudioSepフレームワークは、分離バックボーンとして、周波数ドメインのResUNetモデルを使用します。このモデルには、オーディオクリップの混合が入力として与えられます。モデルは、まず、波形信号からSTFTまたはShort-Time Fourier Transformを適用して、複素スペクトログラム、magnitudeスペクトログラム、Xの位相を抽出します。モデルは次に、magnitudeスペクトログラムを処理するためのエンコーダーとデコーダーのネットワークを構築します。
ResUNetエンコーダーとデコーダーのネットワークは、6つの残差ブロック、6つのデコーダーブロック、4つのボトルネックブロックで構成されています。各エンコーダーブロックでは、スペクトログラムは4つの残差畳み込みブロックを使用して、ボトルネック機能にダウンサンプリングされます。デコーダーブロックでは、4つの残差畳み込みブロックを使用して、機能をアップサンプリングして分離コンポーネントを取得します。各エンコーダーブロックとその対応するデコーダーブロックは、同じアップサンプリングまたはダウンサンプリングレートで動作するスキップ接続を確立します。フレームワークの残差ブロックには、2つのLeaky-ReLU活性化レイヤー、2つのバッチ正規化レイヤー、2つのCNNレイヤーがあり、さらに、各残差ブロックの入力と出力の間で追加の残差ショートカットが導入されます。ResUNetモデルは、複素スペクトログラムXを入力として取り、magnitudeマスクMを出力として生成します。位相残差は、テキスト埋め込みに条件付けられており、スペクトログラムのmagnitudeのスケーリングと回転を制御します。分離された複素スペクトログラムは、予測magnitudeマスクと位相残差を、混合のSTFT(Short-Time Fourier Transform)と乗算することで抽出できます。

AudioSepフレームワークでは、ResUNetの畳み込みブロックの展開後、分離モデルとテキストエンコーダーを接続するために、FiLmまたはFeature-wise Linearly modulatedレイヤーを使用します。
訓練と損失
AudioSepモデルの訓練中、開発者は、大声の増幅方法を使用し、L1損失関数を使用して、グラウンドトゥルース波形と予測波形の間で、AudioSepフレームワークをエンドツーエンドで訓練します。
データセットとベンチマーク
前述のように、AudioSepは、LASSモデルの現在の依存関係を解決することを目的とした基礎モデルであり、ラベル付けされたオーディオテキストペアデータセットへの依存関係を解消することを目的としています。AudioSepモデルは、多モーダル学習能力を付与するために、幅広いデータセットで訓練されています。ここでは、AudioSepフレームワークを訓練するために使用されるデータセットとベンチマークの詳細な説明が示されています。
AudioSet
AudioSetは、約200万個の10秒間のオーディオクリップで構成される、大規模な弱いラベル付けされたオーディオデータセットです。各オーディオクリップは、YouTubeから直接抽出されており、約500種類の異なるオーディオクラス(自然音、人間の音、車両音など)に分類されています。
VGGSound
VGGSoundデータセットは、YouTubeから直接抽出された、大規模な視聴覚データセットです。約20万個の10秒間のビデオクリップで構成されており、約300種類の音クラス(人間の音、自然音、鳥の音など)に分類されています。VGGSoundデータセットを使用することで、ターゲット音を生成する責任があるオブジェクトも、対応する視覚クリップで記述可能であることが保証されます。
AudioCaps
AudioCapsは、約5万個の10秒間のオーディオクリップで構成される、公開されている最大のオーディオキャプションデータセットです。データは、AudioSetデータセットから抽出されており、訓練データ、テストデータ、検証データの3つのカテゴリに分割されています。オーディオクリップは、Amazon Mechanical Turkプラットフォームを使用して人間によって自然言語説明で注釈付けされています。訓練データセットの各オーディオクリップには1つのキャプションがあり、テストデータと検証データセットのデータにはそれぞれ5つのグラウンドトゥルースキャプションがあります。
ClothoV2
ClothoV2は、FreeSoundプラットフォームから抽出されたクリップで構成される、オーディオキャプションデータセットです。AudioCapsと同様に、各オーディオクリップは、Amazon Mechanical Turkプラットフォームを使用して人間によって自然言語説明で注釈付けされています。
WavCaps
WavCapsは、約40万個のオーディオクリップで構成される、大規模な弱いラベル付けされたオーディオデータセットです。オーディオクリップは、BBC Sound Effects、AudioSet、FreeSound、SoundBibleなど、幅広いオーディオソースから抽出されています。

訓練の詳細
訓練フェーズ中、AudioSepモデルは、訓練データセットの2つの異なるオーディオクリップから2つのオーディオセグメントをランダムにサンプリングし、それらを組み合わせて訓練ミキサーオーディオを作成します。各オーディオセグメントの長さは約5秒です。モデルは、波形信号から、Hann窓のサイズ1024、ホップサイズ320で、複素スペクトログラムを抽出します。
モデルは、CLIP/CLAPモデルのテキストエンコーダーを使用して、テキストの監視をデフォルトの構成として、テキスト埋め込みを抽出します。分離モデルについては、AudioSepフレームワークは、30層、6つのエンコーダーブロック、6つのデコーダーブロックで構成されるResUNetレイヤーを使用します。さらに、各エンコーダーブロックには、カーネルサイズ3×3の2つの畳み込み層があり、エンコーダーブロックの出力特徴マップの数は、32、64、128、256、512、1024です。デコーダーブロックはエンコーダーブロックと対称性を持ち、開発者は、バッチサイズ96で、AudioSepモデルを訓練するためにAdamオプティマイザを適用します。
評価結果
既知のデータセットでの評価
以下の図は、訓練フェーズ中の既知のデータセット、つまり訓練データセットでのAudioSepフレームワークのパフォーマンスを、Speech強化モデル、LASS、CLIPなどのベースラインシステムと比較して示しています。CLIPテキストエンコーダーを使用するAudioSepモデルは、AudioSep-CLIPと表記され、CLAPテキストエンコーダーを使用するAudioSepモデルは、AudioSep-CLAPと表記されます。

図から見られるように、AudioSepフレームワークは、オーディオキャプションまたはテキストラベルを入力クエリとして使用する場合に、優れたパフォーマンスを示しています。結果は、AudioSepフレームワークが、LASSやオーディオクエリベースの音源分離モデルなどの既存のベンチマークを上回ることを示しています。
未知のデータセットでの評価
AudioSepのゼロショット設定でのパフォーマンスを評価するために、開発者は、未知のデータセットでのパフォーマンスを評価しました。AudioSepフレームワークは、ゼロショット設定で、印象的な分離パフォーマンスを示しています。結果は以下の図に示されています。

さらに、以下の画像は、AudioSepモデルをVoicebank-Demandスピーチ強化と比較した結果を示しています。

AudioSepフレームワークの評価は、ゼロショット設定で未知のデータセットでの強力な望ましいパフォーマンスを示しています。したがって、新しいデータ分布での音源操作タスクの実行が可能になります。
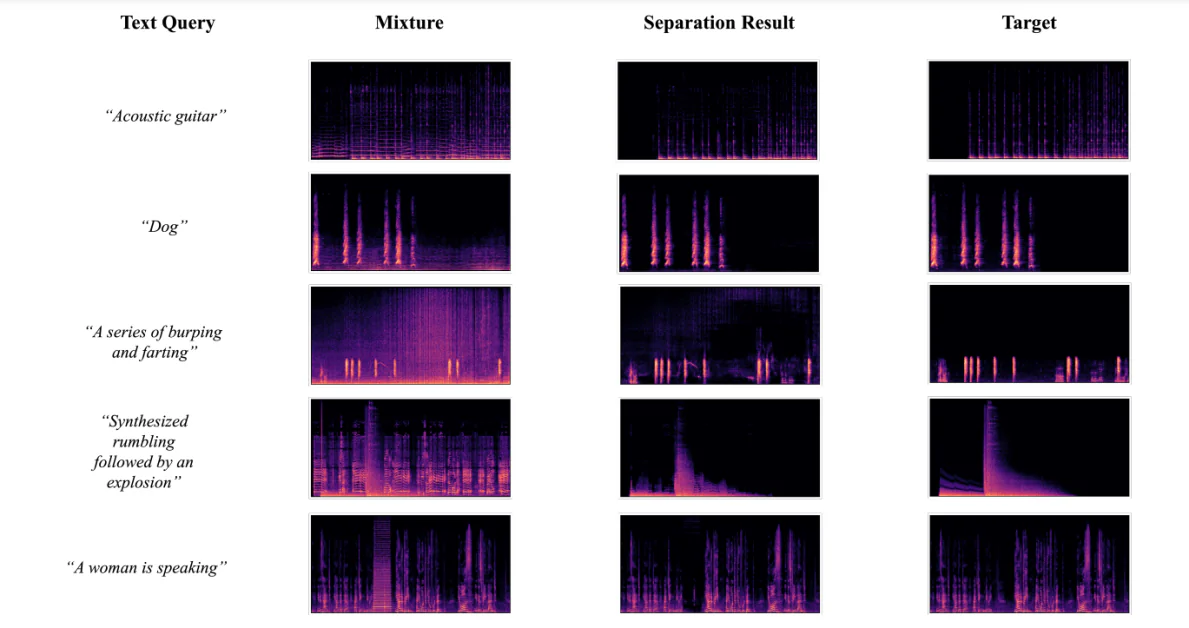
分離結果の視覚化
以下の図は、開発者がAudioSep-CLAPフレームワークを使用して、グラウンドトゥルースターゲットオーディオソース、オーディオミキサーソース、分離されたオーディオソースのスペクトログラムの視覚化を実行した結果を示しています。結果は、分離されたソースのスペクトログラムパターンが、グラウンドトゥルースのソースに近いことを示しています。これは、実験中に得られた目的の結果をさらにサポートしています。
テキストクエリの比較
開発者は、AudioCaps MiniでAudioSep-CLAPとAudioSep-CLIPのパフォーマンスを評価し、AudioSetイベントラベル、AudioCapsキャプション、再注釈付きの自然言語説明を使用して、さまざまなクエリの影響を調べました。以下の図は、AudioCaps Miniの例を示しています。

結論
AudioSepは、オープンドメインの普遍的な音源分離フレームワークであり、音源分離に自然言語説明を使用します。評価から見られるように、AudioSepフレームワークは、オーディオキャプションまたはテキストラベルをクエリとして使用する場合に、ゼロショットおよび無教師学習をシームレスに実行する能力を示しています。結果と評価パフォーマンスは、LASSや音源分離フレームワークなどの現在の最先端技術を上回る強力なパフォーマンスを示しています。したがって、音源分離フレームワークの現在の限界を解決する可能性があります。












