
Artificial Intelligence
InstructIR: 人間の指示に従って高品質の画像を復元

画像は多くの情報を伝えることができますが、モーション ブラー、かすみ、ノイズ、低ダイナミック レンジなどのさまざまな問題によって損なわれる可能性もあります。これらの問題は、一般に低レベルのコンピュータ ビジョンの低下と呼ばれ、熱や雨などの困難な環境条件、またはカメラ自体の制限によって発生する可能性があります。画像の復元は、コンピュータ ビジョンにおける中心的な課題であり、このような劣化が見られる画像から高品質でクリーンな画像を回復することに努めます。特定のイメージを復元するには複数の解決策が存在する可能性があるため、イメージの復元は複雑です。一部のアプローチは、ノイズの削減やぼやけやかすみの除去など、特定の劣化をターゲットとしています。
これらの方法は、特定の問題に対して良好な結果をもたらす可能性がありますが、さまざまな種類の劣化に一般化するのが難しい場合がよくあります。多くのフレームワークは、幅広い画像復元タスクに汎用ニューラル ネットワークを採用していますが、これらのネットワークはそれぞれ個別にトレーニングされます。劣化の種類ごとに異なるモデルが必要なため、このアプローチは計算コストと時間がかかるため、最近の開発ではオールインワン復元モデルに焦点が当てられています。これらのモデルは、複数のレベルとタイプの劣化に対処する単一のディープ ブラインド修復モデルを利用し、パフォーマンスを向上させるために劣化固有のプロンプトまたはガイダンス ベクトルを使用することがよくあります。オールインワン モデルは通常、有望な結果を示しますが、依然として逆問題という課題に直面しています。
InstructIR は、この分野における最初の画期的なアプローチです。 画像修復 人間が書いた指示を通じて修復モデルをガイドするように設計されたフレームワーク。自然言語プロンプトを処理して、さまざまな劣化タイプを考慮して、劣化した画像から高品質の画像を復元できます。 InstructIR は、ディレイニング、ノイズ除去、かすみ除去、ぼけ除去、低照度画像の強化など、幅広い画像復元タスクのパフォーマンスにおける新しい標準を確立します。
この記事は、InstructIR フレームワークを詳しく説明することを目的としており、最先端の画像およびビデオ生成フレームワークとの比較とともに、フレームワークのメカニズム、方法論、アーキテクチャを探ります。それでは始めましょう。
InstructIR: 高品質の画像復元
画像の復元は、劣化が見られる画像から高品質のきれいな画像を復元することを目的としているため、コンピュータ ビジョンの基本的な問題です。低レベルのコンピューター ビジョンでは、劣化とは、モーション ブラー、ヘイズ、ノイズ、低ダイナミック レンジなど、画像内で観察される不快な影響を表すために使用される用語です。画像の復元が複雑な逆の課題である理由は、画像を復元するには複数の異なるソリューションが存在する可能性があるためです。インスタンス ノイズの削減や画像のノイズ除去などの特定の劣化に重点を置いているフレームワークもあれば、ぼやけやぼやけの除去、かすみの除去やかすみ除去に重点を置いているフレームワークもあります。
最近の深層学習手法は、従来の画像復元手法と比較して、より強力で一貫したパフォーマンスを示しています。これらの深層学習画像復元モデルは、トランスフォーマーと畳み込みニューラル ネットワークに基づくニューラル ネットワークの使用を提案しています。これらのモデルは、さまざまな画像復元タスク用に個別にトレーニングでき、ローカルおよびグローバルな特徴の相互作用をキャプチャして強化する機能も備えているため、満足のいく一貫したパフォーマンスが得られます。これらの方法の中には、特定の種類の劣化に対しては適切に機能するものもありますが、通常は、さまざまな種類の劣化に対しては適切に推定できません。さらに、多くの既存のフレームワークは多数の画像復元タスクに同じニューラル ネットワークを使用しますが、すべてのニューラル ネットワークの定式化は個別にトレーニングされます。したがって、考えられるすべての劣化に対して個別のニューラル モデルを採用するのは非現実的で時間がかかることは明らかです。そのため、最近の画像復元フレームワークはオールインワン復元プロキシに集中しています。
オールインワン、マルチ劣化、またはマルチタスクの画像復元モデルは、劣化ごとにモデルを個別にトレーニングする必要がなく、画像内の複数のタイプとレベルの劣化を復元できるため、コンピュータ ビジョンの分野で人気が高まっています。 。オールインワン画像復元モデルは、単一のディープ ブラインド画像復元モデルを使用して、さまざまな種類とレベルの画像劣化に対処します。さまざまなオールインワン モデルは、ブラインド モデルをガイドして劣化した画像を復元するためのさまざまなアプローチを実装します。たとえば、劣化を分類するための補助モデルや、モデルが画像内のさまざまな種類の劣化を復元するのに役立つ多次元のガイダンス ベクトルやプロンプトなどです。画像。
そうは言っても、テキストベースの画像操作は、テキストから画像への生成やテキストベースの画像編集タスクのために過去数年間にいくつかのフレームワークによって実装されてきたため、テキストベースの画像操作に到達します。これらのモデルは多くの場合、テキスト プロンプトを利用してアクションや画像を説明します。 拡散ベースのモデル 対応する画像を生成します。 InstructIR フレームワークの主なインスピレーションは、入力画像のテキスト ラベル、説明、またはキャプションの代わりにどのようなアクションを実行するかをモデルに指示するユーザー指示を使用して、モデルが画像を編集できるようにする InstructPix2Pix フレームワークです。その結果、ユーザーは、サンプル画像や追加の画像説明を提供することなく、自然なテキストを使用してモデルに実行するアクションを指示できます。
これらの基本に基づいて構築された InstructIR フレームワークは、人間が作成した命令を使用して画像復元を実現し、逆問題を解決する史上初のコンピューター ビジョン モデルです。自然言語プロンプトの場合、InstructIR モデルは劣化した画像から高品質の画像を復元でき、複数の劣化タイプも考慮します。 InstructIR フレームワークは、画像のディレイニング、ノイズ除去、かすみ除去、ぼけ除去、低照度画像強調などの幅広い画像復元タスクで最先端のパフォーマンスを提供できます。学習されたガイダンス ベクトルまたはプロンプト埋め込みを使用して画像復元を実現する既存の研究とは対照的に、InstructIR フレームワークはテキスト形式の生のユーザー プロンプトを採用します。 InstructIR フレームワークは、人間が書いた指示を使用したイメージの復元に一般化でき、InstructIR によって実装された単一のオールインワン モデルは、以前のモデルよりも多くの復元タスクをカバーします。次の図は、InstructIR フレームワークのさまざまな復元サンプルを示しています。

InstructIR : メソッドとアーキテクチャ
InstructIR フレームワークの核心は、テキスト エンコーダーと画像モデルで構成されます。このモデルは、画像モデルとして U-Net アーキテクチャに従う効率的な画像復元モデルである NAFNet フレームワークを使用します。さらに、このモデルは、単一のモデルを使用して複数のタスクを学習するタスク ルーティング手法を実装しています。次の図は、InstructIR フレームワークのトレーニングと評価のアプローチを示しています。

InstructPix2Pix モデルからインスピレーションを得た InstructIR フレームワークは、ユーザーが追加情報を提供する必要がないため、制御メカニズムとして人間が記述した命令を採用しています。これらの指示は、表現力豊かで明確な対話方法を提供し、ユーザーが画像内の劣化の正確な場所と種類を指摘できるようにします。さらに、固定劣化固有のプロンプトの代わりにユーザー プロンプトを使用すると、必要な分野の専門知識を持たないユーザーでもモデルを使用できるため、モデルの使いやすさとアプリケーションが強化されます。 InstructIR フレームワークに多様なプロンプトを理解する機能を装備するために、このモデルは GPT-4 (大規模な言語モデル) を使用して多様なリクエストを作成し、曖昧で不明確なプロンプトはフィルター処理後に削除されます。
テキストエンコーダ
テキスト エンコーダーは、ユーザー プロンプトをテキスト埋め込みまたは固定サイズのベクトル表現にマップするために言語モデルによって使用されます。従来、テキストエンコーダは、 クリップモデル CLIP フレームワークは視覚的なプロンプトに優れているため、テキスト ベースの画像生成、およびユーザー プロンプトをエンコードするためのテキスト ベースの画像操作モデルにとって重要なコンポーネントです。ただし、ほとんどの場合、ユーザーは視覚的なコンテンツをほとんどまたはまったく表示しないため、効率が大幅に低下するため、そのようなタスクには大きな CLIP エンコーダが役に立たなくなります。この問題に取り組むために、InstructIR フレームワークは、意味のある埋め込み空間で文をエンコードするようにトレーニングされたテキストベースの文エンコーダーを選択します。文エンコーダは数百万の例で事前にトレーニングされており、従来の CLIP ベースのテキスト エンコーダと比較してコンパクトで効率的でありながら、多様なユーザー プロンプトのセマンティクスをエンコードする機能を備えています。
テキストガイダンス
InstructIR フレームワークの主な特徴は、画像モデルの制御メカニズムとしてエンコードされた命令を実装することです。これに基づいて、多くのタスク学習のタスク ルーティングにヒントを得た InstructIR フレームワークは、モデル内でタスク固有の変換を可能にする命令構築ブロック (ICB) を提案します。従来のタスク ルーティングでは、タスク固有のバイナリ マスクがチャネル機能に適用されます。ただし、InstructIR フレームワークは劣化を認識していないため、この手法は直接実装されません。さらに、画像の特徴とエンコードされた命令に対して、InstructIR フレームワークはタスク ルーティングを適用し、シグモイド関数を使用してアクティブ化された線形レイヤーを使用してマスクを生成し、テキストの埋め込みに応じて一連の重みを生成します。これにより、ごとに c 次元が取得されます。チャネルバイナリマスク。このモデルは、NAFBlock を使用して条件付き機能をさらに強化し、NAFBlock と命令条件付きブロックを使用してエンコーダー ブロックとデコーダー ブロックの両方で機能を条件付けします。
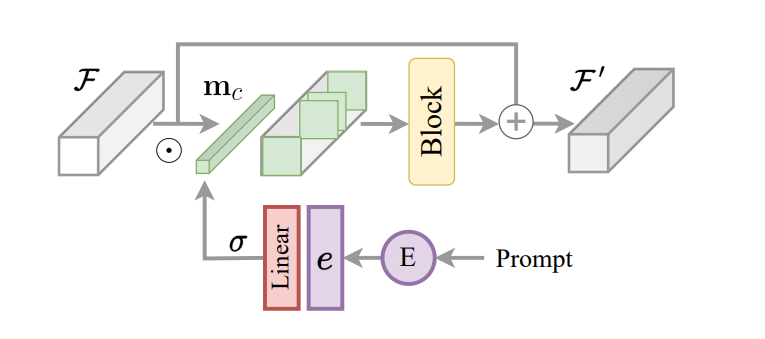
InstructIR フレームワークはニューラル ネットワーク フィルターを明示的に条件付けしませんが、マスクにより、モデルが画像の命令と情報に基づいて最も関連性の高いチャネルを選択することが容易になります。
InstructIR: 実装と結果
InstructIR モデルはエンドツーエンドでトレーニング可能であり、画像モデルは事前トレーニングを必要としません。トレーニングする必要があるのは、テキスト埋め込み投影と分類ヘッドのみです。テキスト エンコーダは、BGE エンコーダを使用して初期化されます。BGE エンコーダは、汎用目的の文エンコード用に大量の教師ありおよび教師なしデータで事前トレーニングされた BERT に似たエンコーダです。 InstructIR フレームワークはイメージ モデルとして NAFNet モデルを使用し、NAFNet のアーキテクチャは、各レベルでブロック数が異なる 4 レベルのエンコーダ デコーダで構成されます。このモデルでは、エンコーダーとデコーダーの間に 4 つの中間ブロックも追加され、機能がさらに強化されています。さらに、スキップ接続の連結の代わりに、デコーダは加算を実装し、InstructIR モデルはエンコーダとデコーダのみでタスク ルーティング用の ICB または命令条件付きブロックのみを実装します。次に、復元された画像とグラウンドトゥルースのクリーンな画像間の損失を使用して InstructIR モデルが最適化され、クロスエントロピー損失がテキスト エンコーダーの意図分類ヘッドに使用されます。 InstructIR モデルは、バッチ サイズ 32、学習率 5e-4 でほぼ 500 エポックの AdamW オプティマイザーを使用し、コサイン アニーリング学習率減衰も実装します。 InstructIR フレームワークの画像モデルは 16 万個のパラメータのみで構成され、学習済みのテキスト投影パラメータは 100 万個しかないため、InstructIR フレームワークは標準 GPU で簡単にトレーニングでき、計算コストが削減され、適用性が向上します。
複数の劣化結果
複数の機能低下と複数タスクの復元のために、InstructIR フレームワークは 2 つの初期セットアップを定義します。
- 3 つの劣化モデルの XNUMXD で、かすみ除去、ノイズ除去、排水などの劣化問題に取り組みます。
- 5D の XNUMX つの劣化モデルは、画像のノイズ除去、低照度強調、かすみ除去、ノイズ除去、ディレインなどの劣化問題に対処します。
5D モデルのパフォーマンスを次の表に示し、最先端の画像復元およびオールインワン モデルと比較しています。

ご覧のとおり、単純な画像モデルとわずか 16 万個のパラメーターを備えた InstructIR フレームワークは、命令ベースのガイダンスのおかげで 3 つの異なる画像復元タスクを正常に処理でき、優れた結果をもたらします。次の表は、XNUMXD モデルでのフレームワークのパフォーマンスを示しており、結果は上記の結果と同等です。

InstructIR フレームワークの主なハイライトは、命令ベースの画像復元です。次の図は、特定のタスクに対する幅広い命令を理解する InstructIR モデルの驚くべき能力を示しています。また、敵対的命令の場合、InstructIR モデルは強制されないアイデンティティを実行します。

最終的な考え
画像の復元は、劣化が見られる画像から高品質のきれいな画像を復元することを目的としているため、コンピュータ ビジョンの基本的な問題です。低レベルのコンピューター ビジョンでは、劣化とは、モーション ブラー、ヘイズ、ノイズ、低ダイナミック レンジなど、画像内で観察される不快な影響を表すために使用される用語です。この記事では、人間が書いた指示を使用して画像復元モデルをガイドすることを目的とした世界初の画像復元フレームワークである InstructIR について説明しました。自然言語プロンプトの場合、InstructIR モデルは劣化した画像から高品質の画像を復元でき、複数の劣化タイプも考慮します。 InstructIR フレームワークは、画像のディレイニング、ノイズ除去、かすみ除去、ぼけ除去、低照度画像強調などの幅広い画像復元タスクで最先端のパフォーマンスを提供できます。















