
Artificial Intelligence
実画像の代わりにランダムノイズでコンピュータビジョンモデルをトレーニングする

MIT コンピューター サイエンス & 人工知能研究所 (CSAIL) の研究者は、コンピューター ビジョン データセット内のランダム ノイズ画像を使用してコンピューター ビジョン モデルをトレーニングする実験を行い、この方法がゴミを生成する代わりに驚くほど効果的であることを発見しました。

実験で得られた生成モデルをパフォーマンス別に並べたもの。 出典: https://openreview.net/pdf?id=RQUl8gZnN7O
明らかな「視覚的ゴミ」を一般的なコンピュータ ビジョン アーキテクチャに投入しても、この種のパフォーマンスが得られるはずはありません。 上の画像の右端にある黒い列は、精度スコアを表します ( イメージネット-100) XNUMX つの「実際の」データセットの場合。 これに先行する「ランダム ノイズ」データセット (さまざまな色で図示、左上の索引を参照) はそれに一致しませんが、ほぼすべて精度が許容できる上限と下限 (赤い破線) 内にあります。
この意味で、「精度」とは、結果が必ずしも次のように見えることを意味するものではありません。 顔 教会 ピザ、または作成に興味があるその他の特定のドメイン 画像合成 Generative Adversarial Network やエンコーダ/デコーダ フレームワークなどのシステム。
むしろ、これは、CSAIL モデルが、明らかに構造化されていないため提供できないはずの画像データから、広く適用可能な中心的な「真実」を導き出したことを意味します。
多様性 vs. 自然主義
これらの結果はどちらにも起因するものではありません 過剰適合:活気のある 議論 Open Review の著者と査読者の間で行われた調査では、視覚的に多様なデータセット (「枯葉」、「フラクタル」、「手続き的ノイズ」など – 下の画像を参照) からのさまざまなコンテンツをトレーニング データセットに混合することが明らかになりました。 実際に 向上させる 精度 これらの実験では。
これは、「多様性」が「自然主義」に勝る、新しいタイプの「過小適合」を示唆しています(そして、これは少し革命的な概念です)。
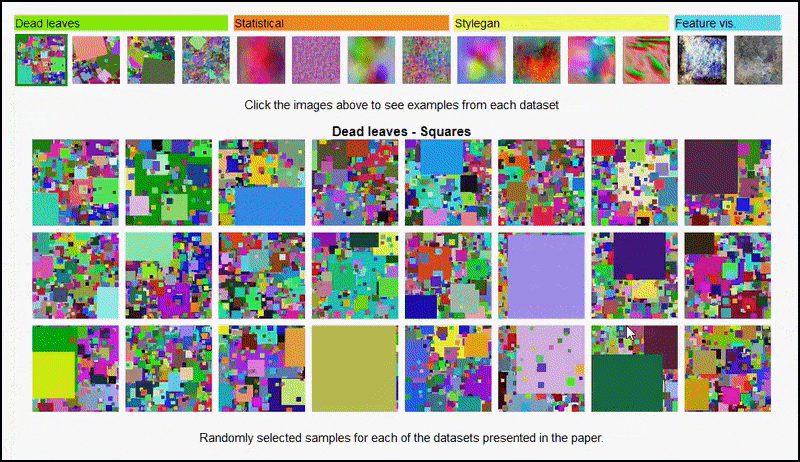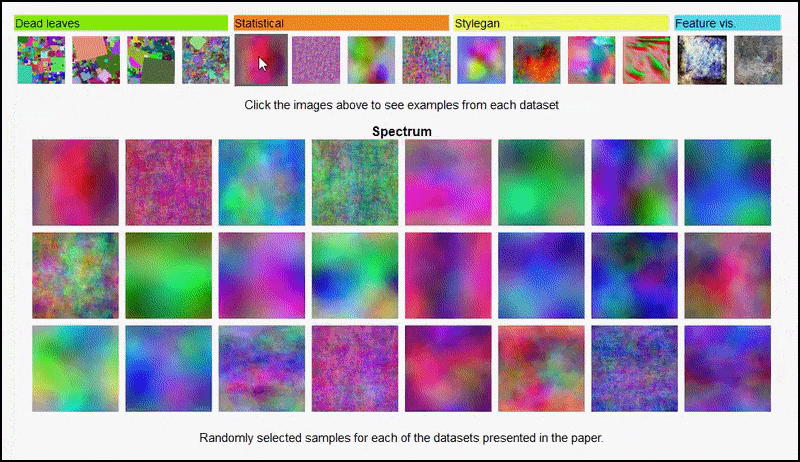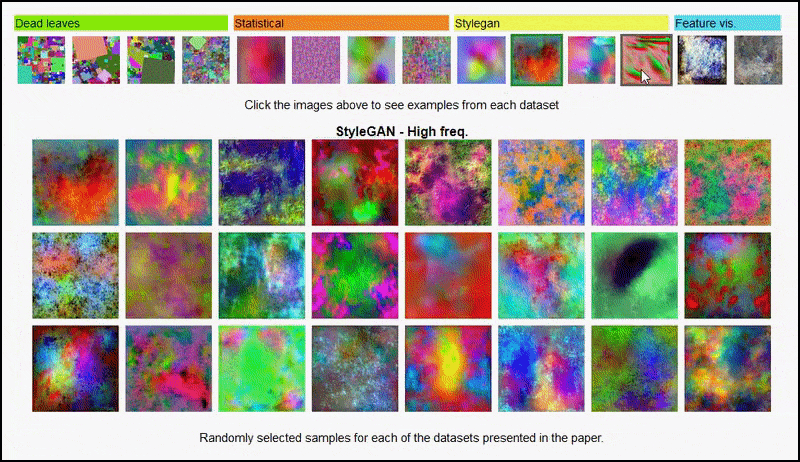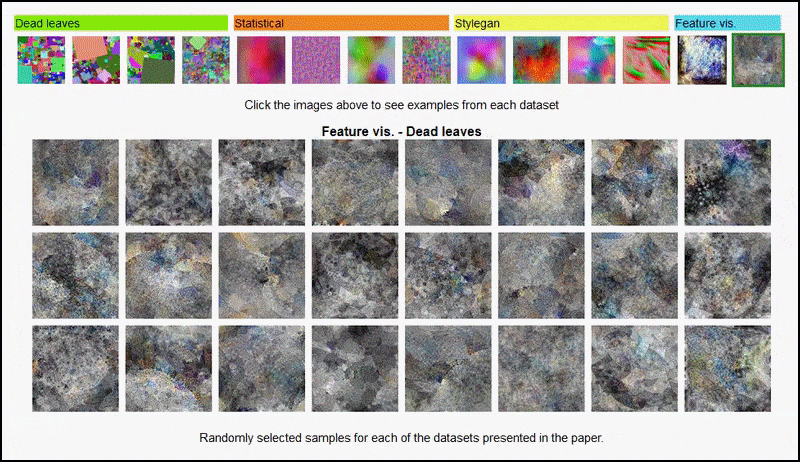
プロジェクトページ この取り組みでは、実験で使用されたさまざまな種類のランダム画像データセットを対話的に表示できます。 出典: https://mbaradad.github.io/learning_with_noise/
研究者らによって得られた結果は、画像ベースのニューラル ネットワークと、驚くべきことに投げ込まれる「現実世界」の画像との基本的な関係に疑問を投げかけています。 より大きなボリューム 毎年、情報を入手し、管理し、その他の方法で議論する必要があることを暗示しています。 ハイパースケール画像データセット 最終的には不要になる可能性があります。 著者らは次のように述べています。
「現在の視覚システムは巨大なデータセットでトレーニングされており、これらのデータセットにはコストが伴います。キュレーションには費用がかかり、人間の偏見を受け継ぎ、プライバシーと使用権に対する懸念があります。」 これらのコストに対抗するために、ラベルのない画像などの安価なデータソースから学習することへの関心が高まっています。
「この論文では、さらに一歩進んで、手続き型ノイズ プロセスから学習することで、実際の画像データセットを完全に廃止できるかどうかを検討します。」
研究者らは、現在の機械学習アーキテクチャは、これまで考えられていたよりもはるかに根本的な(または少なくとも予想外の)何かを画像から推論している可能性があり、「ナンセンスな」画像は潜在的にこの知識をはるかに多く与える可能性があると示唆しています。トレーニング時にランダムな画像を生成するデータセット生成アーキテクチャを介して、アドホックな合成データを使用する可能性がある場合でも、安価に実現できます。
'私たちは、視覚システムのトレーニングに適した合成データを作成する 1 つの重要な特性、2) 自然主義、XNUMX) 多様性を特定します。 興味深いことに、自然主義には多様性が犠牲になる可能性があるため、最も自然主義的なデータが常に最良であるとは限りません。
「自然主義的なデータが役立つという事実は驚くべきことではないかもしれません。そしてそれは実際に大規模な実際のデータには価値があることを示唆しています。」 しかし、重要なのはデータが正しいかどうかではないことがわかりました。 リアル でもそうなること 自然主義つまり、実際のデータの特定の構造特性をキャプチャする必要があります。
「これらの特性の多くは、単純なノイズ モデルで捉えることができます。」

著者らが使用したさまざまな「ランダム画像」データセットの一部に対する AlexNet 由来のエンコーダーから得られた特徴の視覚化で、3 番目と 5 番目 (最終) の畳み込み層をカバーしています。 ここで使用される方法論は、で説明されているものに従います。 2017 年の Google AI 研究.
紙シドニーで開催された第 35 回神経情報処理システム会議 (NeurIPS 2021) で発表された論文のタイトルは、 ノイズを見て見ることを学ぶ、CSAIL の XNUMX 人の研究者が均等に貢献しています。
仕事は 推奨される NeurIPS 2021での注目セレクションのコンセンサスにより、ピアコメンターはこの論文を、たとえ答えと同じくらい多くの疑問を提起したとしても、「偉大な研究分野」を開く「科学的ブレークスルー」であると特徴づけた。
論文の中で著者らは次のように結論づけています。
「私たちは、自然画像統計に関する過去の研究の結果を使用して設計すると、これらのデータセットが視覚的表現をうまくトレーニングできることを示しました。 この論文が、さまざまな視覚タスクで使用された場合にさらに高いパフォーマンスを達成する構造化ノイズを生成できる新しい生成モデルの研究に動機を与えることを願っています。
「ImageNet の事前トレーニングで得られるパフォーマンスに匹敵することは可能でしょうか?」 おそらく、特定のタスクに固有の大規模なトレーニング セットが存在しない場合、最適な事前トレーニングは、ImageNet などの標準的な実際のデータセットを使用しない可能性があります。















