
Artificial Intelligence
RigNeRF: ニューラル放射フィールドを使用する新しいディープフェイク手法

アドビで開発された新しい研究は、以下に基づいた最初の実行可能で効果的なディープフェイク手法を提供しています。 ニューラル ラディアンス フィールド (NeRF) – おそらく、2017 年のディープフェイクの出現以来 XNUMX 年間で、アーキテクチャまたはアプローチにおける最初の本格的な革新となります。
と題されたその方法は、 リグネRF、用途 3D モーファブル顔モデル (3DMM) 目的の入力 (つまり、NeRF レンダリングに課されるアイデンティティ) とニューラル空間の間の手段の介在層として使用される、この方法は、 近年広く採用されている Generative Adversarial Network (GAN) による顔合成アプローチですが、機能的で有用なビデオ用の顔置換フレームワークはまだ作成されていません。

従来のディープフェイク動画とは異なり、ここに描かれている動くコンテンツはどれも「本物」ではなく、短い映像でトレーニングされた探索可能な神経空間です。 右側には、3D モーファブル顔モデル (3DMM) が、目的の操作 (「笑顔」、「左を見る」、「上を向く」など) と、通常は扱いにくいニューラル ラディアンス フィールドのパラメーターの間のインターフェースとして機能しています。視覚化。 このクリップの高解像度バージョンと他の例については、 プロジェクトページ、またはこの記事の最後にある埋め込みビデオをご覧ください。 出典: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM は事実上、顔の CGI モデルであり、そのパラメータは、制御が難しい NeRF や GAN などのより抽象的な画像合成システムに適合させることができます。
上の画像 (中央の画像、青いシャツを着た男性) とすぐ下の画像 (左の画像、青いシャツを着た男性) で見ているものは、「」の小さなパッチが入り込んだ「本物の」ビデオではありません。偽の顔がスーパーインポーズされていますが、体と背景を含む、ボリューム ニューラル レンダリングとしてのみ存在する完全に合成されたシーンです。

すぐ上の例では、右側の現実のビデオ (赤いドレスを着た女性) が、RigNeRF を介して左側のキャプチャされたアイデンティティ (青いシャツを着た男性) を「操る」ために使用されており、これが (著者らの主張による) 最初のビデオです。 NeRF ベースのシステムにより、ポーズと表情の分離を実現しながら、新しいビュー合成を実行できます。
上の画像の左側にある男性の人物は、70 秒のスマートフォンのビデオから「キャプチャ」され、その後、入力データ (シーン情報全体を含む) が 4 つの V100 GPU でトレーニングされてシーンを取得しました。
3DMM スタイルのパラメトリック リグも利用できるため、 全身パラメトリック CGI プロキシ (単なるフェイス リグではなく)RigNeRF は、実際の人間の動き、テクスチャ、表現が CGI ベースのパラメトリック レイヤーに渡され、アクションと表現がレンダリングされた NeRF 環境とビデオに変換される全身ディープフェイクの可能性を開く可能性があります。 。
RigNeRF については、見出しでこの用語が理解されている現在の意味で、ディープフェイク手法として認められますか? それとも、これは、DeepFaceLab やその他の労働集約的な 2017 年時代のオートエンコーダーディープフェイク システムにも実行された、もう XNUMX つの半ば足かせ的なシステムなのでしょうか?
新しい論文の研究者らはこの点について明確に次のように述べている。
「RigNeRF は顔を生き返らせることができる手法であるため、悪意のある者がディープフェイクを生成するために悪用する傾向があります。」
新しい 紙 というタイトルです RigNeRF: 完全に制御可能なニューラル 3D ポートレートこれは、RigNeRF の開発中に Adobe でインターンを務めた Stonybrook University の ShahRukh Atha 氏と、Adobe Research の他の XNUMX 人の著者によるものです。
オートエンコーダーベースのディープフェイクを超えて
過去数年間で見出しを飾ったウイルス性ディープフェイクの大部分は、 オートエンコーダベースのシステムは、2017 年に即時禁止された r/ディープフェイクのサブレディットで公開されたコードから派生しましたが、公開される前ではありませんでした。 コピーされた 現在フォークされている GitHub へ 千回以上、特に人気のあるものに(もし 物議を醸す) ディープフェイスラボ 配布、そしてまた、 フェイススワップ プロジェクト。
GAN と NeRF に加えて、オートエンコーダー フレームワークも、顔合成フレームワークを改善するための「ガイドライン」として 3DMM を実験してきました。 この例としては、 ハイファイフェイスプロジェクト ただし、これまでのところ、このアプローチから開発された実用的または人気のある取り組みはないようです。
RigNeRF シーンのデータは、スマートフォンの短いビデオをキャプチャして取得されます。 このプロジェクトでは、RigNeRF の研究者はすべての実験に iPhone XR または iPhone 12 を使用しました。 キャプチャの前半では、被写体はカメラが被写体の周囲を動かされる間、頭を動かさずにさまざまな表情や発話を行うことが求められます。
撮影の後半では、カメラは固定された位置を維持し、被写体は頭を動かしながらさまざまな表情を表現する必要があります。 結果として得られる 40 ~ 70 秒のフッテージ (約 1200 ~ 2100 フレーム) は、モデルのトレーニングに使用されるデータセット全体を表します。
データ収集の削減
対照的に、DeepFaceLab などのオートエンコーダ システムでは、YouTube ビデオやその他のソーシャル メディア チャネル、さらには映画 (有名人のディープフェイクの場合) から撮影された数千枚の多様な写真の比較的手間のかかる収集とキュレーションが必要です。
結果として得られるトレーニング済みオートエンコーダー モデルは、多くの場合、さまざまな状況で使用することを目的としています。 ただし、最も気難しい「有名人」ディープフェイク作成者は、トレーニングに XNUMX 週間以上かかる場合があるにもかかわらず、XNUMX つのビデオのためにモデル全体をゼロからトレーニングする場合があります。
新しい論文の研究者らによる警告にもかかわらず、AI ポルノや人気の YouTube/TikTok の「ディープフェイク リキャスティング」を強化する「パッチワーク」と広範囲に組み立てられたデータセットは、RigNeRF のようなディープフェイク システムでは許容できる一貫した結果を生み出す可能性は低いようです。シーン固有の方法論を備えています。 新しい研究で概説されているデータ収集の制限を考慮すると、これは、悪意のあるディープフェイク作成者による偶発的な個人情報の悪用に対する追加の保護手段であることがある程度証明される可能性があります。
NeRF をディープフェイクビデオに適応させる
NeRF は、さまざまな視点から撮影された少数のソース画像が探索可能な 3D 神経空間に組み立てられる、写真測量ベースの方法です。 このアプローチは、今年初めに NVIDIA が発表したときに注目を集めました。 インスタントNeRF NeRF の法外なトレーニング時間を数分、さらには数秒まで削減できるシステムです。

インスタントNeRF。 出典: https://www.youtube.com/watch?v=DJ2hcC1orc4
結果として得られる Neural Radiance Field シーンは、本質的には探索可能な静的な環境ですが、 編集が難しい。 研究者らは、これまでの XNUMX つの NeRF ベースの取り組みに注目しています。 HyperNeRF + E/P および ナーフェイス – 顔のビデオ合成に挑戦し、(明らかに完全性と勤勉さのため) テスト ラウンドで次の XNUMX つのフレームワークに対して RigNeRF を設定しました。


RigNeRF、HyperNeRF、NerFACE の定性的な比較。 高品質バージョンについては、リンクされたソースビデオと PDF を参照してください。 静的画像ソース: https://arxiv.org/pdf/2012.03065.pdf
ただし、この場合、RigNeRF に有利な結果は XNUMX つの理由からかなり異常です。第 XNUMX に、著者らは「同一対同一の比較に関する既存の研究が存在しない」と観察しています。 第二に、これにより、以前のシステムのより制限された機能に少なくとも部分的に一致するように、RigNeRF の機能を制限する必要がありました。
この結果は以前の作業に対する段階的な改善ではなく、むしろ NeRF の編集可能性とユーティリティにおける「画期的な」ものであるため、テスト ラウンドは脇に置いて、代わりに RigNeRF が前任者と何が違うのかを見てみましょう。
総合力
NeRF 環境でポーズ/表情制御を作成できる NerFACE の主な制限は、ソース映像が静的カメラでキャプチャされることを想定していることです。 これは事実上、キャプチャの制限を超える新しいビューを生成できないことを意味します。 これにより、「動くポートレート」を作成できるシステムが生成されますが、ディープフェイク スタイルのビデオには適していません。
一方、HyperNeRF は、斬新で超現実的なビューを生成できますが、頭のポーズや顔の表情を変更できる手段を備えていないため、やはりオートエンコーダベースのディープフェイクの競合相手にはなりません。
RigNeRF は、3DMM モジュールからの入力を介して逸脱と変形を実行できるデフォルトのベースラインである「標準空間」を作成することで、これら XNUMX つの独立した機能を組み合わせることができます。
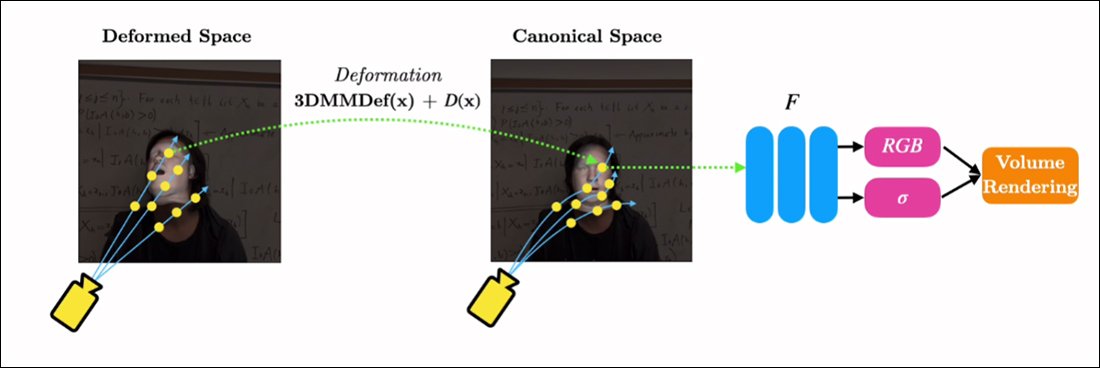
3DMM を介して生成された変形 (つまり、ポーズと表情) が作用できる「標準空間」(ポーズなし、表情なし) を作成します。
3DMM システムはキャプチャされた被写体と正確に一致しないため、プロセス中にこれを補正することが重要です。 RigNeRF は、事前に計算された変形フィールドを使用してこれを実現します。 多層パーセプトロン (MLP) ソース映像から派生。

変形の計算に必要なカメラ パラメータは、次の方法で取得されます。 コルマップ、各フレームの表現および形状パラメータは次から取得されます。 の.
ポジショニングはさらに最適化されます。 ランドマークフィッティング および COLMAP のカメラ パラメータ、およびコンピューティング リソースの制限により、ビデオ出力はトレーニング用に 256 × 256 の解像度にダウンサンプリングされます (ハードウェア制約のある縮小プロセスであり、オートエンコーダのディープフェイク シーンでも問題となる)。
この後、変形ネットワークは 100 つの VXNUMX でトレーニングされます。VXNUMX は、一般の愛好家には手の届かない恐るべきハードウェアです (ただし、機械学習のトレーニングに関しては、多くの場合、時間と引き換えにそのモデルを受け入れることが可能です)トレーニングには数日、場合によっては数週間かかります)。
結論として、研究者らは次のように述べています。
「他の方法とは対照的に、RigNeRF は 3DMM ガイド付き変形モジュールの使用により、頭のポーズ、顔の表情、および完全な 3D ポートレート シーンを高い忠実度でモデル化することができるため、鮮明な詳細を備えたより優れた再構築が可能になります。」
詳細と結果の映像については、以下の埋め込みビデオをご覧ください。


初版は15年2022月XNUMX日。















