
Kecerdasan Buatan
Tiga Tantangan ke Depan untuk Difusi yang Stabil

Grafik melepaskan Stabilitas Difusi Stabilitas.ai difusi laten model sintesis gambar beberapa minggu yang lalu mungkin merupakan salah satu pengungkapan teknologi yang paling signifikan sejak DeCSS pada tahun 1999; ini tentu saja merupakan peristiwa terbesar dalam citra yang dihasilkan AI sejak 2017 kode deepfake disalin ke GitHub dan bercabang menjadi apa yang akan terjadi Lab Wajah Dalam dan Tukar Muka, serta perangkat lunak deepfake streaming waktu nyata DeepFaceLive.
Pada stroke, frustrasi pengguna atas pembatasan konten di API sintesis gambar DALL-E 2 disingkirkan, karena terungkap bahwa filter NSFW Stable Diffusion dapat dinonaktifkan dengan mengubah a satu-satunya baris kode. Reddit Difusi Stabil yang berpusat pada pornografi bermunculan hampir seketika, dan dengan cepat ditebang, sementara kubu pengembang dan pengguna terbagi di Discord menjadi komunitas resmi dan NSFW, dan Twitter mulai dipenuhi dengan kreasi Stable Diffusion yang fantastis.
Saat ini, setiap hari tampaknya membawa beberapa inovasi luar biasa dari para pengembang yang telah mengadopsi sistem, dengan plugin dan tambahan pihak ketiga yang ditulis dengan tergesa-gesa untuk Krita, Photoshop, Cinema4D, Pencampur, dan banyak platform aplikasi lainnya.

Sementara itu, kerajinan cepat – seni profesional 'bisikan AI', yang mungkin menjadi pilihan karir terpendek sejak 'pengikat Filofax' – sudah menjadi dikomersialkan, sementara monetisasi awal Stable Diffusion berlangsung di Tingkat patreon, dengan kepastian akan datangnya penawaran yang lebih canggih, bagi mereka yang tidak mau menavigasi Berbasis konda penginstalan kode sumber, atau filter NSFW proskriptif dari implementasi berbasis web.
Laju pengembangan dan eksplorasi bebas dari pengguna berjalan dengan kecepatan yang memusingkan sehingga sulit untuk melihat jauh ke depan. Pada dasarnya, kita belum tahu persis apa yang sedang kita hadapi, atau apa saja batasan atau kemungkinannya.
Meskipun demikian, mari kita lihat tiga rintangan yang mungkin paling menarik dan menantang untuk dihadapi dan, mudah-mudahan, diatasi oleh komunitas Stable Diffusion yang terbentuk dengan cepat dan berkembang pesat.
1: Mengoptimalkan Jaringan Pipa Berbasis Ubin
Disajikan dengan sumber daya perangkat keras yang terbatas dan batasan keras pada resolusi gambar pelatihan, tampaknya pengembang akan menemukan solusi untuk meningkatkan kualitas dan resolusi output Difusi Stabil. Banyak dari proyek ini diatur untuk mengeksploitasi keterbatasan sistem, seperti resolusi aslinya yang hanya 512×512 piksel.
Seperti yang selalu terjadi pada visi komputer dan inisiatif sintesis gambar, Difusi Stabil dilatih pada gambar rasio persegi, dalam hal ini diambil sampelnya ulang menjadi 512x512, sehingga gambar sumber dapat diatur dan disesuaikan dengan batasan GPU yang ada. melatih modelnya.
Oleh karena itu Difusi Stabil 'berpikir' (jika memang berpikir) dalam istilah 512×512, dan tentu saja dalam bentuk kuadrat. Banyak pengguna yang saat ini menyelidiki batasan sistem melaporkan bahwa Difusi Stabil menghasilkan hasil yang paling andal dan paling tidak bermasalah pada rasio aspek yang agak terbatas ini (lihat 'mengatasi ekstremitas' di bawah).
Meskipun berbagai implementasi menampilkan peningkatan melalui ESRGAN nyata (dan dapat memperbaiki wajah yang dirender dengan buruk melalui GFPGAN) beberapa pengguna saat ini sedang mengembangkan metode untuk membagi gambar menjadi beberapa bagian berukuran 512x512px dan menyatukan gambar untuk membentuk karya komposit yang lebih besar.

Render 1024×576 ini, resolusi yang biasanya tidak mungkin dilakukan dalam satu render Difusi Stabil, dibuat dengan menyalin dan menempelkan file Python attention.py dari DoggettX fork of Stable Diffusion (versi yang mengimplementasikan upscaling berbasis petak) ke fork lain. Sumber: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Meskipun beberapa inisiatif semacam ini menggunakan kode asli atau pustaka lain, port txt2imghd dari GOBIG (mode dalam ProgRockDiffusion yang haus akan VRAM) akan segera menyediakan fungsionalitas ini ke cabang utama. Sementara txt2imghd adalah port khusus GOBIG, upaya lain dari pengembang komunitas melibatkan penerapan GOBIG yang berbeda.

Gambar abstrak yang nyaman dalam render 512x512px asli (kiri dan kedua dari kiri); ditingkatkan oleh ESGRAN, yang sekarang kurang lebih asli di semua distribusi Difusi Stabil; dan diberi 'perhatian khusus' melalui penerapan GOBIG, menghasilkan detail yang, setidaknya dalam batas-batas bagian gambar, tampak ditingkatkan dengan lebih baik. Ssumber: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Jenis contoh abstrak yang ditampilkan di atas memiliki banyak detail 'kerajaan kecil' yang sesuai dengan pendekatan solipsistik untuk peningkatan ini, tetapi yang mungkin memerlukan solusi berbasis kode yang lebih menantang untuk menghasilkan peningkatan yang tidak berulang dan kohesif yang tidak melihat seperti itu dirakit dari banyak bagian. Paling tidak, dalam kasus wajah manusia, di mana kita secara tidak biasa terbiasa dengan penyimpangan atau artefak yang 'menggemuruh'. Oleh karena itu, wajah pada akhirnya mungkin membutuhkan solusi khusus.
Difusi Stabil saat ini tidak memiliki mekanisme untuk memfokuskan perhatian pada wajah selama render dengan cara yang sama seperti manusia memprioritaskan informasi wajah. Meskipun beberapa pengembang di komunitas Discord sedang mempertimbangkan metode untuk mengimplementasikan 'perhatian yang ditingkatkan' semacam ini, saat ini jauh lebih mudah untuk secara manual (dan, akhirnya, secara otomatis) menyempurnakan wajah setelah render awal dilakukan.
Wajah manusia memiliki logika semantik internal dan lengkap yang tidak akan ditemukan di 'ubin' sudut bawah (misalnya) bangunan, dan oleh karena itu saat ini mungkin untuk 'memperbesar' dan merender ulang secara efektif wajah 'samar' dalam output Difusi Stabil.

Kiri, Upaya awal Stable Diffusion dengan prompt 'Foto berwarna lengkap Christina Hendricks memasuki tempat ramai, mengenakan jas hujan; Canon50, kontak mata, detail tinggi, detail wajah tinggi'. Benar, wajah yang ditingkatkan diperoleh dengan memberi makan wajah buram dan sketsa dari render pertama kembali ke perhatian penuh Difusi Stabil menggunakan Img2Img (lihat gambar animasi di bawah).
Dengan tidak adanya solusi Pembalikan Tekstual khusus (lihat di bawah), ini hanya akan berfungsi untuk gambar selebritas di mana orang tersebut sudah terwakili dengan baik dalam subkumpulan data LAION yang melatih Difusi Stabil. Oleh karena itu, ini akan bekerja pada orang-orang seperti Tom Cruise, Brad Pitt, Jennifer Lawrence, dan sejumlah tokoh media asli yang hadir dalam jumlah besar gambar dalam data sumber.
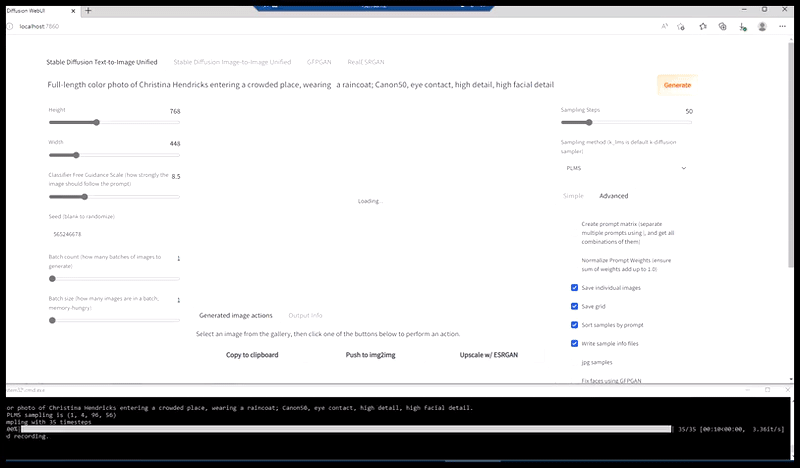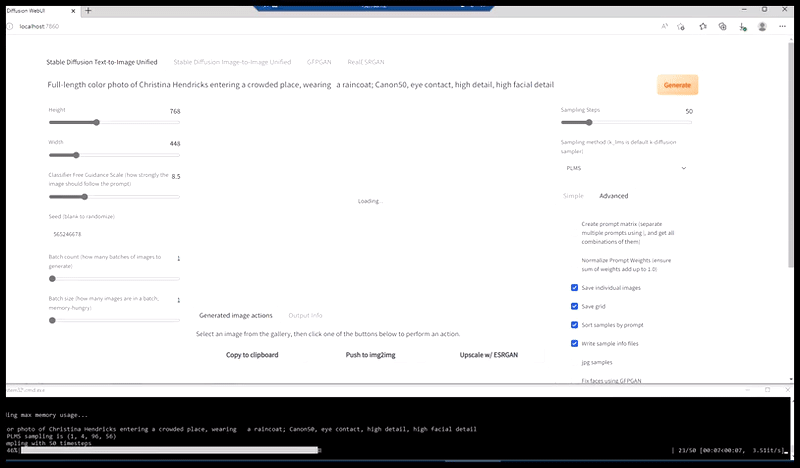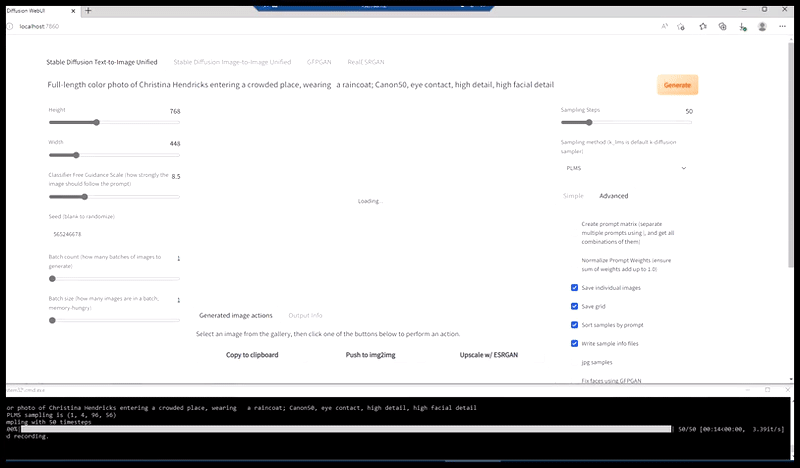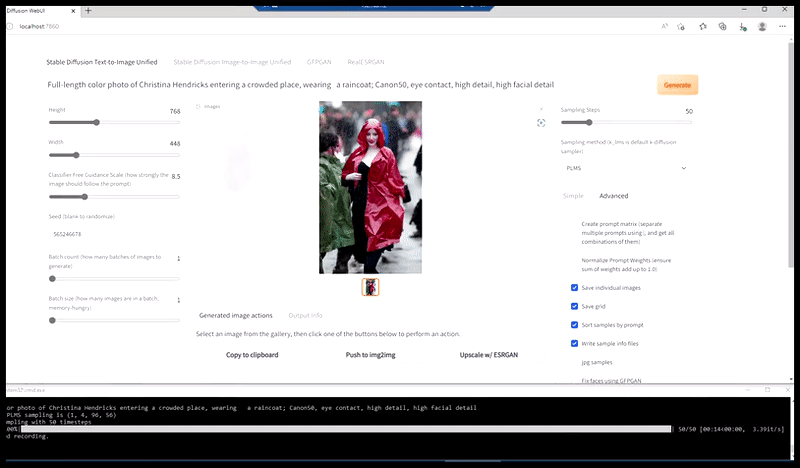
Menghasilkan gambar pers yang masuk akal dengan prompt 'Foto berwarna lengkap Christina Hendricks memasuki tempat ramai, mengenakan jas hujan; Canon50, kontak mata, detail tinggi, detail wajah tinggi'.
Untuk selebritas dengan karir yang panjang dan bertahan lama, Difusi Stabil biasanya akan menghasilkan citra orang tersebut pada usia yang baru (yaitu lebih tua), dan akan diperlukan untuk menambahkan tambahan yang cepat seperti 'muda' or 'pada tahun [TAHUN]' untuk menghasilkan gambar yang terlihat lebih muda.

Dengan karir yang menonjol, banyak difoto, dan konsisten selama hampir 40 tahun, aktris Jennifer Connelly adalah salah satu dari segelintir selebritas di LAION yang memungkinkan Stable Diffusion mewakili rentang usia. Sumber: Difusi Stabil prepack, lokal, pos pemeriksaan v1.4; petunjuk terkait usia.
Ini sebagian besar karena proliferasi fotografi pers digital (daripada mahal, berbasis emulsi) sejak pertengahan 2000-an, dan pertumbuhan volume output gambar selanjutnya karena peningkatan kecepatan broadband.
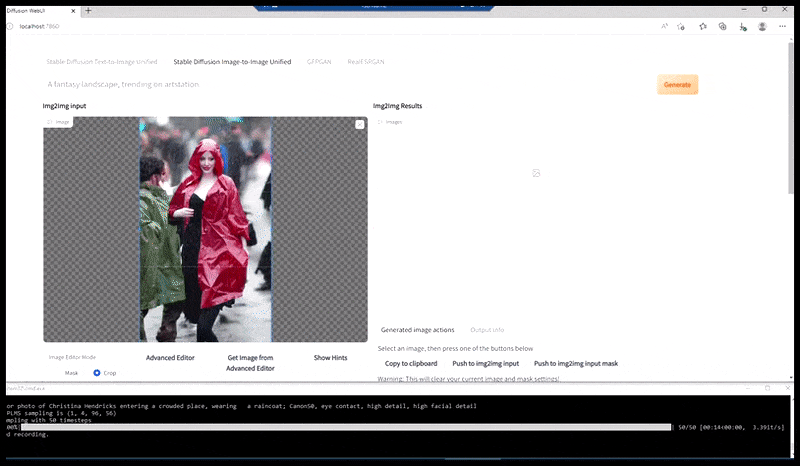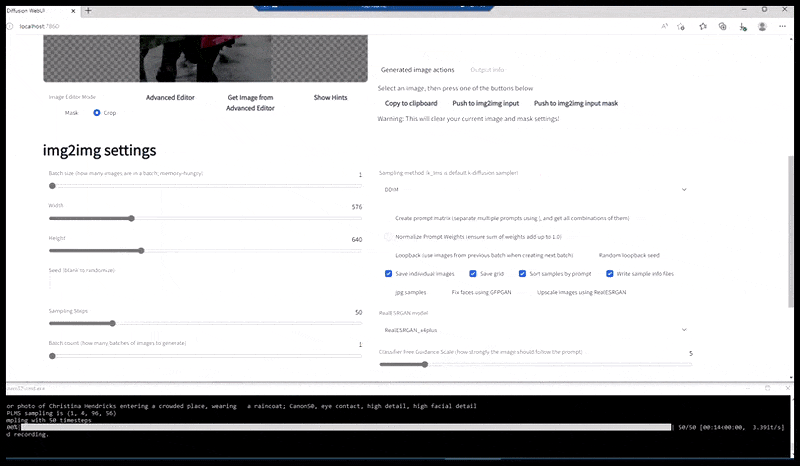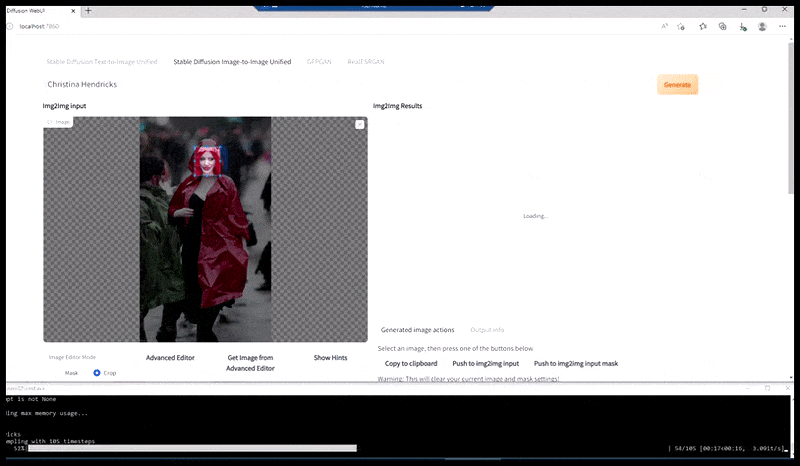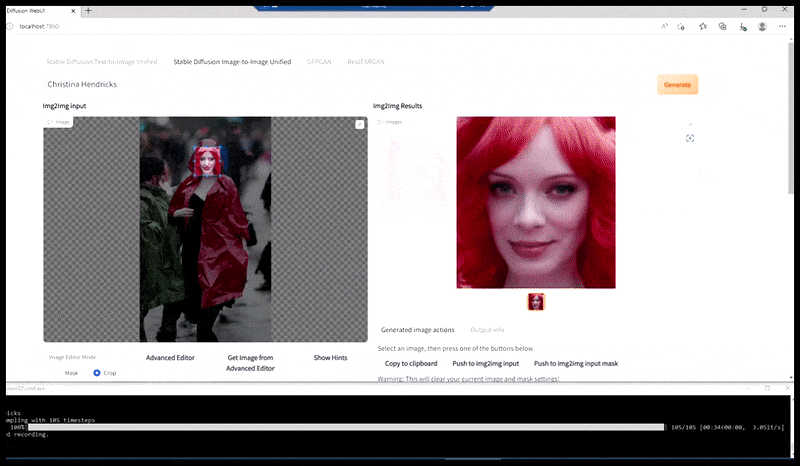
Gambar yang dirender diteruskan ke Img2Img dalam Stable Diffusion, di mana 'area fokus' dipilih, dan render ukuran maksimum baru dibuat hanya dari area tersebut, memungkinkan Stable Diffusion memusatkan semua sumber daya yang tersedia untuk membuat ulang wajah.
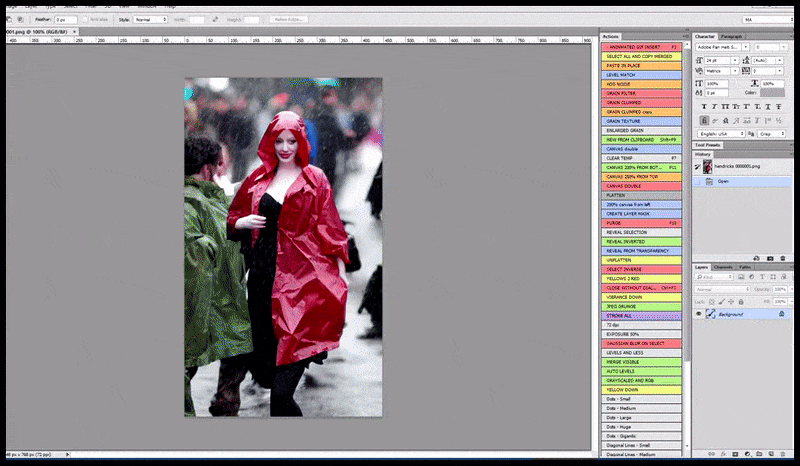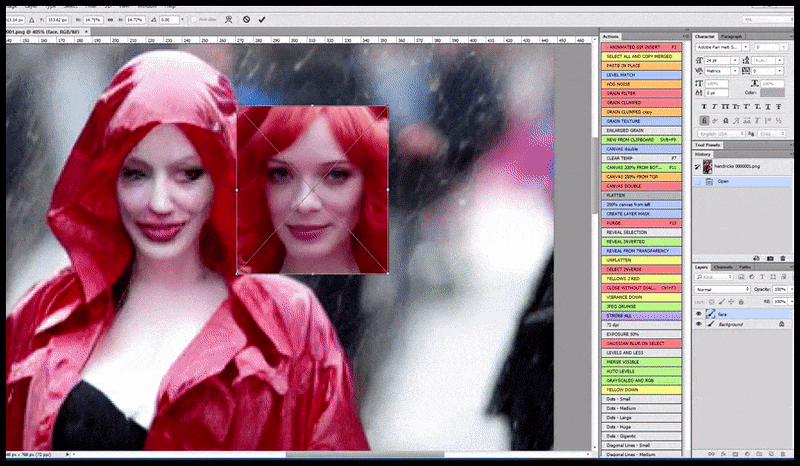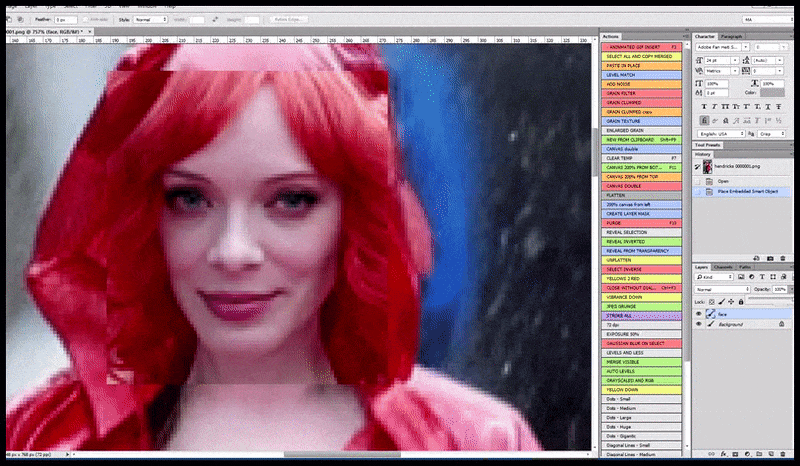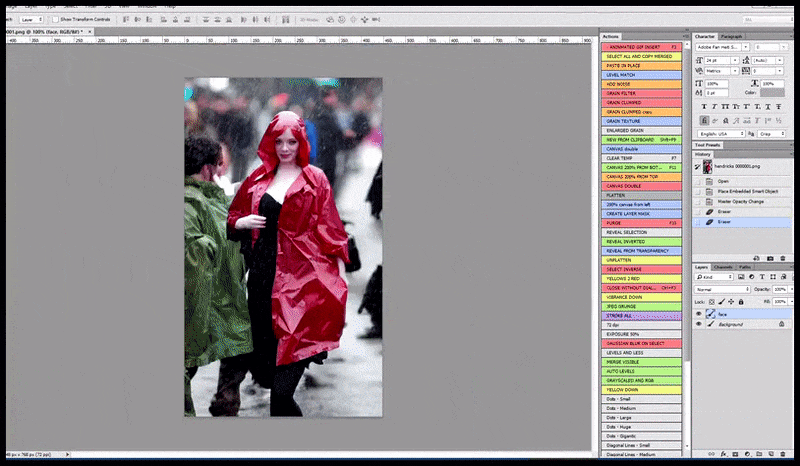
Mengomposisi wajah 'perhatian tinggi' kembali ke render asli. Selain wajah, proses ini hanya akan bekerja dengan entitas yang memiliki potensi penampilan yang diketahui, kohesif, dan integral, seperti sebagian dari foto asli yang memiliki objek berbeda, seperti jam tangan atau mobil. Meningkatkan bagian dari – misalnya – dinding akan mengarah ke dinding yang dipasang kembali yang tampak sangat aneh, karena render ubin tidak memiliki konteks yang lebih luas untuk 'potongan jigsaw' ini saat mereka merender.
Beberapa selebritas dalam database datang 'dibekukan' dalam waktu, baik karena mereka meninggal lebih awal (seperti Marilyn Monroe), atau naik menjadi hanya sekilas arus utama, menghasilkan volume gambar yang tinggi dalam jangka waktu terbatas. Polling Stable Diffusion bisa dibilang memberikan semacam indeks popularitas 'terkini' untuk bintang modern dan tua. Untuk beberapa selebritas yang lebih tua dan saat ini, tidak ada cukup gambar dalam data sumber untuk mendapatkan kemiripan yang sangat baik, sementara popularitas abadi dari bintang-bintang tertentu yang telah lama mati atau memudar memastikan bahwa kemiripan wajar mereka dapat diperoleh dari sistem.

Render Difusi Stabil dengan cepat mengungkapkan wajah terkenal mana yang terwakili dengan baik dalam data pelatihan. Terlepas dari popularitasnya yang luar biasa sebagai remaja yang lebih tua pada saat penulisan, Millie Bobby Brown lebih muda dan kurang terkenal ketika kumpulan data sumber LAION dihapus dari web, membuat kemiripan berkualitas tinggi dengan Difusi Stabil bermasalah saat ini.
Jika data tersedia, solusi up-res berbasis petak di Stable Diffusion dapat melangkah lebih jauh daripada hanya berfokus pada wajah: mereka berpotensi mengaktifkan wajah yang lebih akurat dan mendetail dengan memecah fitur wajah dan mematikan seluruh kekuatan GPU lokal sumber daya pada fitur yang menonjol satu per satu, sebelum perakitan ulang – sebuah proses yang saat ini, sekali lagi, manual.

Ini tidak terbatas pada wajah, tetapi terbatas pada bagian objek yang setidaknya dapat diprediksi ditempatkan dalam konteks yang lebih luas dari objek host, dan yang sesuai dengan penyematan tingkat tinggi yang dapat diharapkan secara wajar untuk ditemukan dalam hyperscale Himpunan data.
Batas sebenarnya adalah jumlah data referensi yang tersedia dalam kumpulan data, karena, pada akhirnya, detail yang berulang secara mendalam akan menjadi benar-benar 'berhalusinasi' (yaitu fiktif) dan kurang autentik.
Pembesaran butiran tingkat tinggi berhasil dalam kasus Jennifer Connelly, karena dia terwakili dengan baik di berbagai usia di LAION-estetika (bagian utama dari LAION 5B yang digunakan Difusi Stabil), dan umumnya di seluruh LAION; dalam banyak kasus lain, akurasi akan berkurang karena kekurangan data, sehingga memerlukan penyetelan halus (pelatihan tambahan, lihat 'Penyesuaian' di bawah) atau Pembalikan Tekstual (lihat di bawah).
Ubin adalah cara yang andal dan relatif murah agar Difusi Stabil diaktifkan untuk menghasilkan output beresolusi tinggi, tetapi peningkatan ubin algoritmik semacam ini, jika tidak memiliki semacam mekanisme perhatian yang lebih luas dan tingkat lebih tinggi, mungkin tidak sesuai harapan- untuk standar di berbagai jenis konten.
2: Mengatasi Masalah dengan Anggota Tubuh Manusia
Difusi Stabil tidak sesuai dengan namanya saat menggambarkan kompleksitas ekstremitas manusia. Tangan dapat berlipat ganda secara acak, jari menyatu, kaki ketiga muncul tanpa diminta, dan anggota tubuh yang ada menghilang tanpa jejak. Dalam pembelaannya, Stable Diffusion berbagi masalah dengan stablemate-nya, dan pastinya dengan DALL-E 2.

Hasil yang tidak diedit dari DALL-E 2 dan Stable Diffusion (1.4) pada akhir Agustus 2022, keduanya menunjukkan masalah pada anggota tubuh. Prompt adalah 'Seorang wanita merangkul seorang pria'
Penggemar Difusi Stabil yang berharap bahwa pos pemeriksaan 1.5 yang akan datang (versi model yang lebih terlatih secara intensif, dengan parameter yang ditingkatkan) akan menyelesaikan kebingungan ekstremitas kemungkinan besar akan kecewa. Model baru yang akan dirilis pada waktu sekitar dua minggu, saat ini ditayangkan perdana di portal stable.ai komersial studio impian, yang menggunakan 1.5 secara default, dan di mana pengguna dapat membandingkan output baru dengan render dari sistem 1.4 lokal atau lainnya:

Sumber: Prepack 1.4 lokal dan https://beta.dreamstudio.ai/

Sumber: Prepack 1.4 lokal dan https://beta.dreamstudio.ai/

Sumber: Prepack 1.4 lokal dan https://beta.dreamstudio.ai/
Seperti yang sering terjadi, kualitas data bisa menjadi penyebab utama.
Database open source yang menjadi bahan bakar sistem sintesis citra seperti Stable Diffusion dan DALL-E 2 mampu memberikan banyak label untuk manusia individu dan tindakan antar manusia. Label ini dilatih secara simbiosis dengan gambar terkait, atau segmen gambar.

Pengguna Stable Diffusion dapat menjelajahi konsep yang dilatihkan ke dalam model dengan menanyakan set data estetika LAION, subset dari set data LAION 5B yang lebih besar, yang menggerakkan sistem. Gambar-gambar tersebut diurutkan bukan berdasarkan label abjadnya, tetapi berdasarkan 'skor estetika' mereka. Sumber: https://rom1504.github.io/clip-retrieval/
A hirarki yang baik label dan kelas individu yang berkontribusi pada penggambaran lengan manusia akan menjadi seperti itu badan>lengan>tangan>jari>[sub digit + ibu jari]> [segmen digit]>kuku.

Segmentasi semantik terperinci dari bagian-bagian tangan. Bahkan dekonstruksi terperinci yang luar biasa ini meninggalkan setiap 'jari' sebagai entitas tunggal, tidak memperhitungkan tiga bagian jari dan dua bagian ibu jari. Sumber: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Pada kenyataannya, gambar sumber tidak mungkin dianotasi secara konsisten di seluruh kumpulan data, dan algoritme pelabelan tanpa pengawasan mungkin akan berhenti di lebih tinggi tingkat – misalnya – 'tangan', dan biarkan piksel interior (yang secara teknis berisi informasi 'jari') sebagai massa piksel yang tidak berlabel dari mana fitur akan diturunkan secara acak, dan yang mungkin terwujud dalam render selanjutnya sebagai elemen yang menggelegar.

Bagaimana seharusnya (kanan atas, jika bukan potongan atas), dan bagaimana kecenderungannya (kanan bawah), karena sumber daya yang terbatas untuk pelabelan, atau eksploitasi arsitektural dari label tersebut jika memang ada dalam kumpulan data.
Jadi, jika model difusi laten mencapai lengan, hampir pasti setidaknya akan mencoba memberikan tangan di ujung lengan itu, karena lengan> tangan adalah hierarki persyaratan minimal, cukup tinggi dalam apa yang diketahui arsitektur tentang 'anatomi manusia'.
Setelah itu, 'jari' mungkin merupakan pengelompokan terkecil, meskipun masih ada 14 sub-bagian jari/ibu jari yang harus dipertimbangkan saat menggambarkan tangan manusia.
Jika teori ini berlaku, tidak ada obat yang nyata, karena kurangnya anggaran untuk anotasi manual di seluruh sektor, dan kurangnya algoritme yang cukup efektif yang dapat mengotomatiskan pelabelan sambil menghasilkan tingkat kesalahan yang rendah. Akibatnya, model saat ini mungkin mengandalkan konsistensi anatomi manusia untuk menutupi kekurangan dari dataset yang dilatihnya.
Salah satu kemungkinan alasan mengapa itu tidak bisa mengandalkan ini, baru-baru ini diusulkan di Stable Diffusion Discord, apakah model dapat menjadi bingung tentang jumlah jari yang benar yang harus dimiliki tangan manusia (realistis) karena basis data turunan LAION yang mendukungnya menampilkan karakter kartun yang mungkin memiliki lebih sedikit jari (yang dengan sendirinya jalan pintas hemat tenaga kerja).

Dua penyebab potensial sindrom 'jari hilang' di Stable Diffusion dan model serupa. Di bawah, contoh tangan kartun dari kumpulan data estetika LAION yang mendukung Difusi Stabil. Sumber: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Jika ini benar, maka satu-satunya solusi yang jelas adalah melatih ulang model, mengecualikan konten berbasis manusia yang tidak realistis, memastikan bahwa kasus asli penghilangan (yaitu orang yang diamputasi) diberi label yang sesuai sebagai pengecualian. Dari titik kurasi data saja, ini akan menjadi tantangan yang cukup besar, terutama untuk upaya komunitas yang kekurangan sumber daya.
Pendekatan kedua adalah menerapkan filter yang mengecualikan konten semacam itu (yaitu 'tangan dengan tiga/lima jari') agar tidak terwujud pada waktu render, dengan cara yang sama seperti yang dimiliki OpenAI, sampai batas tertentu, tersaring GPT-3 dan DALL-E2, sehingga keluarannya dapat diatur tanpa perlu melatih ulang model sumber.

Untuk Difusi Stabil, perbedaan semantik antara angka dan bahkan anggota badan dapat menjadi kabur secara mengerikan, mengingatkan pada untaian film horor 'horor tubuh' tahun 1980-an dari orang-orang seperti David Cronenberg. Sumber: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Namun, sekali lagi, ini memerlukan label yang mungkin tidak ada di semua gambar yang terpengaruh, membuat kami menghadapi tantangan logistik dan anggaran yang sama.
Dapat dikatakan bahwa ada dua jalan yang tersisa ke depan: membuang lebih banyak data pada masalah, dan menerapkan sistem interpretatif pihak ketiga yang dapat mengintervensi ketika kesalahan fisik dari jenis yang dijelaskan di sini disajikan kepada pengguna akhir (setidaknya, yang terakhir akan memberi OpenAI metode untuk memberikan pengembalian uang untuk render 'horor tubuh', jika perusahaan termotivasi untuk melakukannya).
3: Kustomisasi
Salah satu kemungkinan paling menarik untuk masa depan Difusi Stabil adalah prospek pengguna atau organisasi yang mengembangkan sistem yang telah direvisi; modifikasi yang memungkinkan konten di luar bidang LAION yang telah dilatih sebelumnya untuk diintegrasikan ke dalam sistem – idealnya tanpa biaya yang tidak dapat diatur untuk melatih kembali seluruh model, atau risiko yang ditimbulkan saat melatih gambar baru dalam volume besar ke gambar baru yang sudah ada, matang, dan mampu model.
Dengan analogi: jika dua siswa kurang berbakat bergabung dengan kelas lanjutan yang terdiri dari tiga puluh siswa, mereka akan berasimilasi dan mengejar ketinggalan, atau gagal sebagai outlier; dalam kedua kasus tersebut, kinerja rata-rata kelas mungkin tidak akan terpengaruh. Namun, jika 15 siswa yang kurang berbakat bergabung, kurva nilai untuk seluruh kelas kemungkinan besar akan menurun.
Demikian pula, jaringan hubungan yang sinergis dan cukup halus yang dibangun melalui pelatihan model yang berkelanjutan dan mahal dapat dikompromikan, dalam beberapa kasus dihancurkan secara efektif, oleh data baru yang berlebihan, menurunkan kualitas keluaran untuk model secara keseluruhan.
Kasus untuk melakukan ini terutama di mana minat Anda terletak pada pembajakan sepenuhnya pemahaman konseptual model tentang hubungan dan hal-hal, dan menyesuaikannya untuk produksi konten eksklusif yang mirip dengan materi tambahan yang Anda tambahkan.
Jadi, pelatihan 500,000 Simpsons bingkai ke pos pemeriksaan Difusi Stabil yang ada kemungkinan besar, pada akhirnya, akan membuat Anda menjadi lebih baik Simpsons simulator daripada yang bisa ditawarkan oleh bangunan asli, dengan anggapan bahwa hubungan semantik yang cukup luas bertahan dalam proses (mis Homer Simpson makan hotdog, yang mungkin memerlukan materi tentang hot-dog yang tidak ada dalam materi tambahan Anda, tetapi sudah ada di pos pemeriksaan), dan dengan anggapan Anda tidak ingin tiba-tiba beralih dari Simpsons konten untuk membuat lanskap menakjubkan oleh Greg Rutkowski – karena model pasca-pelatihan Anda telah mengalihkan perhatiannya secara besar-besaran, dan tidak akan sebaik dulu dalam melakukan hal semacam itu.
Salah satu contoh penting dari hal ini adalah waifu-difusi, yang telah berhasil 56,000 gambar anime pasca-pelatihan ke pos pemeriksaan Difusi Stabil yang lengkap dan terlatih. Ini adalah prospek yang sulit bagi seorang penghobi, karena model ini membutuhkan VRAM minimum 30GB yang menarik, jauh melampaui apa yang mungkin tersedia di tingkat konsumen dalam rilis seri 40XX NVIDIA yang akan datang.

Pelatihan konten khusus ke dalam Difusi Stabil melalui difusi-waifu: model membutuhkan dua minggu pasca pelatihan untuk menghasilkan tingkat ilustrasi ini. Keenam gambar di sebelah kiri menunjukkan kemajuan model, saat pelatihan berlangsung, dalam membuat output subjek-koheren berdasarkan data pelatihan baru. Sumber: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Banyak upaya dapat dikeluarkan untuk 'percabangan' pos pemeriksaan Difusi Stabil seperti itu, hanya untuk dihalangi oleh hutang teknis. Pengembang di Discord resmi telah menunjukkan bahwa rilis pos pemeriksaan selanjutnya tidak harus kompatibel dengan mundur, bahkan dengan logika cepat yang mungkin telah bekerja dengan versi sebelumnya, karena minat utama mereka adalah mendapatkan model terbaik, daripada mendukung aplikasi dan proses lama.
Oleh karena itu, perusahaan atau individu yang memutuskan untuk mencabangkan pos pemeriksaan menjadi produk komersial secara efektif tidak memiliki jalan kembali; versi model mereka, pada saat itu, adalah 'hard fork', dan tidak akan dapat menarik keuntungan upstream dari rilis selanjutnya dari stability.ai – yang merupakan komitmen yang cukup.
Harapan saat ini, dan lebih besar untuk kustomisasi Stable Diffusion adalah Pembalikan Tekstual, di mana pengguna berlatih dalam segelintir kecil CLIPgambar -sejajar.

Kolaborasi antara Universitas Tel Aviv dan NVIDIA, inversi tekstual memungkinkan pelatihan entitas diskrit dan baru, tanpa merusak kemampuan model sumber. Sumber: https://textual-inversion.github.io/
Keterbatasan utama dari inversi tekstual adalah jumlah gambar yang direkomendasikan sangat sedikit – sedikitnya lima. Ini secara efektif menghasilkan entitas terbatas yang mungkin lebih berguna untuk tugas transfer gaya daripada penyisipan objek fotorealistik.
Meskipun demikian, eksperimen saat ini sedang berlangsung dalam berbagai Discord Difusi Stabil yang menggunakan gambar pelatihan dalam jumlah yang jauh lebih tinggi, dan masih harus dilihat seberapa produktif metode tersebut terbukti. Sekali lagi, teknik ini membutuhkan banyak VRAM, waktu, dan kesabaran.
Karena faktor-faktor pembatas ini, kita mungkin harus menunggu beberapa saat untuk melihat beberapa eksperimen inversi tekstual yang lebih canggih dari para penggemar Difusi Stabil – dan apakah pendekatan ini dapat 'memasukkan Anda ke dalam gambar' atau tidak dengan cara yang terlihat lebih baik daripada pendekatan Photoshop cut-and-paste, sambil tetap mempertahankan fungsionalitas luar biasa dari pos pemeriksaan resmi.
Pertama kali diterbitkan 6 September 2022.















