
Kecerdasan Buatan
LipSync3D Google Menawarkan Peningkatan Sinkronisasi Gerakan Mulut 'Deepfaked'

A kolaborasi antara peneliti AI Google dan Institut Teknologi India Kharagpur menawarkan kerangka kerja baru untuk mensintesis pembicaraan dari konten audio. Proyek ini bertujuan untuk menghasilkan cara-cara yang dioptimalkan dan sumber daya yang masuk akal untuk membuat konten video 'bicara kepala' dari audio, untuk tujuan menyelaraskan gerakan bibir ke audio yang disulihsuarakan atau diterjemahkan mesin, dan untuk digunakan dalam avatar, dalam aplikasi interaktif, dan lainnya. lingkungan waktu nyata.

Sumber: https://www.youtube.com/watch?v=L1StbX9OznY
Model pembelajaran mesin yang dilatih dalam proses tersebut – disebut LipSync3D – hanya memerlukan satu video identitas wajah target sebagai data masukan. Jalur persiapan data memisahkan ekstraksi geometri wajah dari evaluasi pencahayaan dan aspek lain dari video masukan, sehingga memungkinkan pelatihan yang lebih ekonomis dan terfokus.
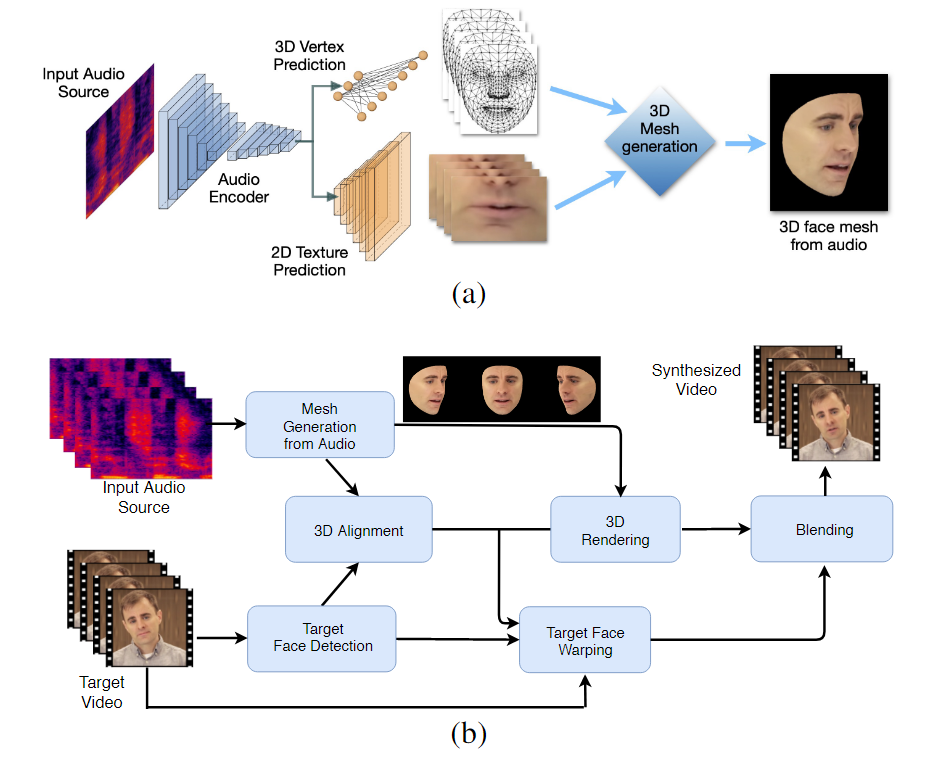
Alur kerja dua tahap LipSync3D. Di atas, pembuatan wajah 3D bertekstur dinamis dari audio 'target'; di bawah ini, penyisipan jaring yang dihasilkan ke dalam video target.
Nyatanya, kontribusi LipSync3D yang paling menonjol pada badan penelitian di bidang ini mungkin adalah algoritme normalisasi pencahayaannya, yang memisahkan iluminasi pelatihan dan inferensi.

Pemisahan data iluminasi dari geometri umum membantu LipSync3D menghasilkan keluaran gerakan bibir yang lebih realistis dalam kondisi yang menantang. Pendekatan lain dalam beberapa tahun terakhir telah membatasi diri pada kondisi pencahayaan 'tetap' yang tidak akan mengungkapkan kapasitasnya yang lebih terbatas dalam hal ini.
Selama pra-pemrosesan kerangka data input, sistem harus mengidentifikasi dan menghilangkan titik-titik specular, karena ini khusus untuk kondisi pencahayaan di mana video diambil, dan sebaliknya akan mengganggu proses penyalaan ulang.

LipSync3D, seperti namanya, tidak hanya melakukan analisis piksel pada wajah yang dievaluasi, tetapi secara aktif menggunakan landmark wajah yang teridentifikasi untuk menghasilkan jaring gaya CGI yang bergerak, bersama dengan tekstur 'terbuka' yang membungkusnya dalam CGI tradisional saluran pipa.

Pose normalisasi di LipSync3D. Di sebelah kiri adalah bingkai input dan fitur yang terdeteksi; di tengah, simpul yang dinormalisasi dari evaluasi mesh yang dihasilkan; dan di sebelah kanan, atlas tekstur yang sesuai, yang menyediakan kebenaran dasar untuk prediksi tekstur. Sumber: https://arxiv.org/pdf/2106.04185.pdf
Selain metode relighting baru, para peneliti mengklaim bahwa LipSync3D menawarkan tiga inovasi utama pada pekerjaan sebelumnya: pemisahan geometri, pencahayaan, pose, dan tekstur menjadi aliran data diskrit dalam ruang yang dinormalisasi; model prediksi tekstur auto-regresif yang mudah dilatih yang menghasilkan sintesis video yang konsisten untuk sementara; dan peningkatan realisme, seperti yang dievaluasi oleh peringkat manusia dan metrik objektif.

Memisahkan berbagai aspek citra wajah video memungkinkan kontrol yang lebih besar dalam sintesis video.
LipSync3D dapat memperoleh gerakan geometri bibir yang sesuai secara langsung dari audio dengan menganalisis fonem dan faset ucapan lainnya, dan menerjemahkannya ke dalam pose otot yang sesuai di sekitar area mulut.

Proses ini menggunakan jalur pipa prediksi bersama, di mana geometri dan tekstur yang disimpulkan memiliki pembuat enkode khusus dalam pengaturan pembuat enkode otomatis, tetapi berbagi pembuat enkode audio dengan ucapan yang dimaksudkan untuk diterapkan pada model:

Sintesis gerakan labil LipSync3D juga dimaksudkan untuk memberdayakan avatar CGI yang bergaya, yang pada dasarnya hanyalah jenis informasi mesh dan tekstur yang sama seperti citra dunia nyata:
Avatar 3D yang bergaya memiliki gerakan bibirnya yang ditenagai secara real time oleh video pembicara sumber. Dalam skenario seperti itu, hasil terbaik akan diperoleh dengan pra-pelatihan yang dipersonalisasi.
Para peneliti juga mengantisipasi penggunaan avatar dengan nuansa yang sedikit lebih realistis:
![]()
Contoh waktu pelatihan untuk video berkisar antara 3-5 jam untuk video berdurasi 2-5 menit, dalam pipeline yang menggunakan TensorFlow, Python, dan C++ pada GeForce GTX 1080. Sesi pelatihan menggunakan ukuran batch 128 bingkai selama 500-1000 zaman, dengan masing-masing zaman mewakili evaluasi lengkap dari video.

Menuju Sinkronisasi Ulang Dinamis Gerakan Bibir
Bidang sinkronisasi ulang bibir untuk mengakomodasi trek audio baru telah mendapat banyak perhatian dalam penelitian visi komputer dalam beberapa tahun terakhir (lihat di bawah), paling tidak karena ini adalah produk sampingan dari kontroversi. teknologi deepfake.
Pada 2017 Universitas Washington penelitian yang disajikan mampu mempelajari sinkronisasi bibir dari audio, menggunakannya untuk mengubah gerakan bibir presiden Obama saat itu. Pada 2018; yang dipimpin Institut Max Planck untuk Informatika inisiatif penelitian lainnya untuk mengaktifkan identitas>transfer video identitas, dengan sinkronisasi bibir a produk sampingan dari proses tersebut; dan pada Mei 2021 startup AI FlawlessAI mengungkapkan teknologi lip-sync miliknya, TrueSync, secara luas diterima di media sebagai pengaktif teknologi sulih suara yang lebih baik untuk rilis film besar dalam berbagai bahasa.
Dan, tentu saja, pengembangan berkelanjutan dari repositori open source deepfake menyediakan cabang lain dari penelitian kontribusi pengguna aktif dalam bidang sintesis gambar wajah ini.















