
Artificial Intelligence
जीरो123++: लगातार मल्टी-व्यू डिफ्यूजन बेस मॉडल के लिए एक एकल छवि

पिछले कुछ वर्षों में उभरते उपन्यास के प्रदर्शन, दक्षता और उत्पादक क्षमताओं में तेजी से प्रगति देखी गई है एआई जनरेटिव मॉडल जो व्यापक डेटासेट और 2डी प्रसार पीढ़ी प्रथाओं का लाभ उठाता है। आज, जेनरेटिव एआई मॉडल 2डी के विभिन्न रूपों और कुछ हद तक टेक्स्ट, इमेज, वीडियो, जीआईएफ और बहुत कुछ सहित 3डी मीडिया सामग्री तैयार करने में बेहद सक्षम हैं।
इस लेख में, हम जीरो123++ फ्रेमवर्क के बारे में बात करेंगे, जो एक छवि-वातानुकूलित प्रसार जनरेटिव एआई मॉडल है जिसका उद्देश्य एकल दृश्य इनपुट का उपयोग करके 3डी-संगत एकाधिक-दृश्य छवियां उत्पन्न करना है। पूर्व-प्रशिक्षित जेनरेटिव मॉडल से प्राप्त लाभ को अधिकतम करने के लिए, ज़ीरो123++ फ्रेमवर्क ऑफ-द-शेल्फ प्रसार छवि मॉडल से फाइनट्यून करने के लिए किए जाने वाले प्रयास की मात्रा को कम करने के लिए कई प्रशिक्षण और कंडीशनिंग योजनाओं को कार्यान्वित करता है। हम Zero123++ फ्रेमवर्क की वास्तुकला, कार्यप्रणाली और परिणामों के बारे में गहराई से जानकारी लेंगे और एक ही छवि से उच्च गुणवत्ता की लगातार एकाधिक-दृश्य छवियां उत्पन्न करने की इसकी क्षमताओं का विश्लेषण करेंगे। तो चलो शुरू हो जाओ।
जीरो123 और जीरो123++: एक परिचय
Zero123++ फ्रेमवर्क एक छवि-वातानुकूलित प्रसार जनरेटिव AI मॉडल है जिसका उद्देश्य एकल दृश्य इनपुट का उपयोग करके 3D-संगत मल्टीपल-व्यू छवियां उत्पन्न करना है। ज़ीरो123++ फ्रेमवर्क ज़ीरो123 या ज़ीरो-1-टू-3 फ्रेमवर्क की निरंतरता है जो ओपन-सोर्स सिंगल-इमेज-टू-3डी रूपांतरणों को आगे बढ़ाने के लिए ज़ीरो-शॉट नॉवेल व्यू इमेज सिंथेसिस तकनीक का लाभ उठाता है। हालाँकि Zero123++ फ्रेमवर्क आशाजनक प्रदर्शन प्रदान करता है, फ्रेमवर्क द्वारा उत्पन्न छवियों में दृश्यमान ज्यामितीय विसंगतियाँ होती हैं, और यही मुख्य कारण है कि 3D दृश्यों और मल्टी-व्यू छवियों के बीच अंतर अभी भी मौजूद है।
जीरो-1-टू-3 फ्रेमवर्क सिंकड्रीमर, वन-2-3-45, कंसिस्टेंट123 और कई अन्य फ्रेमवर्क के लिए आधार के रूप में कार्य करता है, जो 123डी इमेज बनाते समय अधिक सुसंगत परिणाम प्राप्त करने के लिए जीरो3 फ्रेमवर्क में अतिरिक्त परतें जोड़ते हैं। प्रोलिफिकड्रीमर, ड्रीमफ्यूजन, ड्रीमगॉसियन जैसे अन्य फ्रेमवर्क विभिन्न असंगत मॉडलों से 3डी इमेज को डिस्टिल करके 3डी इमेज प्राप्त करने के लिए अनुकूलन-आधारित दृष्टिकोण का पालन करते हैं। यद्यपि ये तकनीकें प्रभावी हैं, और वे संतोषजनक 3डी छवियां उत्पन्न करती हैं, लगातार बहु-दृश्य छवियां उत्पन्न करने में सक्षम आधार प्रसार मॉडल के कार्यान्वयन से परिणामों में सुधार किया जा सकता है। तदनुसार, Zero123++ फ्रेमवर्क जीरो-1 से 3 तक ले जाता है, और स्टेबल डिफ्यूजन से एक नए मल्टी-व्यू बेस डिफ्यूजन मॉडल को परिष्कृत करता है।
शून्य-1-से-3 ढांचे में, प्रत्येक उपन्यास दृश्य स्वतंत्र रूप से उत्पन्न होता है, और यह दृष्टिकोण उत्पन्न विचारों के बीच विसंगतियों की ओर ले जाता है क्योंकि प्रसार मॉडल में एक नमूना प्रकृति होती है। इस समस्या से निपटने के लिए, Zero123++ फ्रेमवर्क एक टाइलिंग लेआउट दृष्टिकोण को अपनाता है, जिसमें ऑब्जेक्ट को एक ही छवि में छह दृश्यों से घिराया जाता है, और ऑब्जेक्ट की मल्टी-व्यू छवियों के संयुक्त वितरण के लिए सही मॉडलिंग सुनिश्चित करता है।
जीरो-1-टू-3 फ्रेमवर्क पर काम करने वाले डेवलपर्स के सामने एक और बड़ी चुनौती यह है कि यह प्रस्तावित क्षमताओं का कम उपयोग करता है। स्थिर प्रसार जो अंततः अकुशलता और अतिरिक्त लागत की ओर ले जाता है। दो प्रमुख कारण हैं कि जीरो-1-टू-3 ढांचा स्थिर प्रसार द्वारा प्रदान की जाने वाली क्षमताओं को अधिकतम नहीं कर सकता है
- छवि स्थितियों के साथ प्रशिक्षण करते समय, शून्य-1-से-3 ढांचा स्थिर प्रसार द्वारा पेश किए गए स्थानीय या वैश्विक कंडीशनिंग तंत्र को प्रभावी ढंग से शामिल नहीं करता है।
- प्रशिक्षण के दौरान, शून्य-1-से-3 ढांचा कम रिज़ॉल्यूशन का उपयोग करता है, एक दृष्टिकोण जिसमें आउटपुट रिज़ॉल्यूशन प्रशिक्षण रिज़ॉल्यूशन से कम हो जाता है जो स्थिर प्रसार मॉडल के लिए छवि निर्माण की गुणवत्ता को कम कर सकता है।
इन मुद्दों से निपटने के लिए, Zero123++ फ्रेमवर्क कंडीशनिंग तकनीकों की एक श्रृंखला को लागू करता है जो स्टेबल डिफ्यूजन द्वारा पेश किए गए संसाधनों के उपयोग को अधिकतम करता है, और स्टेबल डिफ्यूजन मॉडल के लिए छवि निर्माण की गुणवत्ता को बनाए रखता है।
कंडीशनिंग और संगति में सुधार
छवि कंडीशनिंग और मल्टी-व्यू छवि स्थिरता में सुधार करने के प्रयास में, Zero123++ फ्रेमवर्क ने विभिन्न तकनीकों को लागू किया, जिसका प्राथमिक उद्देश्य पूर्व-प्रशिक्षित स्थिर प्रसार मॉडल से प्राप्त पूर्व तकनीकों का पुन: उपयोग करना था।
मल्टी-व्यू जनरेशन
सुसंगत बहु-दृश्य छवियां उत्पन्न करने का अपरिहार्य गुण एकाधिक छवियों के संयुक्त वितरण को सही ढंग से मॉडलिंग करने में निहित है। शून्य-1-से-3 ढांचे में, बहु-दृश्य छवियों के बीच सहसंबंध को नजरअंदाज कर दिया जाता है क्योंकि प्रत्येक छवि के लिए, ढांचा स्वतंत्र रूप से और अलग से सशर्त सीमांत वितरण को मॉडल करता है। हालाँकि, Zero123++ फ्रेमवर्क में, डेवलपर्स ने एक टाइलिंग लेआउट दृष्टिकोण का विकल्प चुना है जो लगातार मल्टी-व्यू जेनरेशन के लिए 6 छवियों को एक फ्रेम/छवि में टाइल करता है, और प्रक्रिया को निम्नलिखित छवि में प्रदर्शित किया गया है।
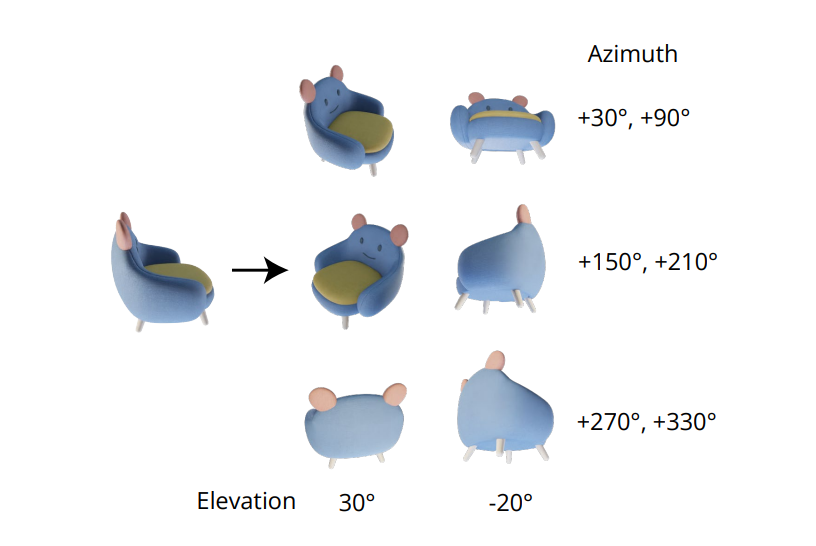
इसके अलावा, यह देखा गया है कि कैमरे के पोज़ पर मॉडल को प्रशिक्षित करते समय ऑब्जेक्ट ओरिएंटेशन अस्पष्ट हो जाते हैं, और इस असंबद्धता को रोकने के लिए, कैमरा पोज़ पर ज़ीरो-1-टू-3 फ़्रेमवर्क ट्रेन ऊंचाई के कोण और इनपुट के सापेक्ष अज़ीमुथ के साथ होती है। इस दृष्टिकोण को लागू करने के लिए, इनपुट के दृश्य के उन्नयन कोण को जानना आवश्यक है जिसका उपयोग नए इनपुट दृश्यों के बीच सापेक्ष स्थिति निर्धारित करने के लिए किया जाता है। इस उन्नयन कोण को जानने के प्रयास में, फ्रेमवर्क अक्सर एक उन्नयन अनुमान मॉड्यूल जोड़ते हैं, और यह दृष्टिकोण अक्सर पाइपलाइन में अतिरिक्त त्रुटियों की कीमत पर आता है।
शोर अनुसूची
स्केल्ड-लीनियर शेड्यूल, स्थिर प्रसार के लिए मूल शोर शेड्यूल मुख्य रूप से स्थानीय विवरणों पर केंद्रित है, लेकिन जैसा कि निम्नलिखित छवि में देखा जा सकता है, इसमें कम एसएनआर या सिग्नल टू शोर अनुपात के साथ बहुत कम चरण हैं।

कम सिग्नल से शोर अनुपात के ये चरण डीनोइज़िंग चरण के दौरान शुरू होते हैं, जो वैश्विक कम-आवृत्ति संरचना को निर्धारित करने के लिए महत्वपूर्ण चरण है। डीनोइज़िंग चरण के दौरान, हस्तक्षेप या प्रशिक्षण के दौरान चरणों की संख्या कम करने से अक्सर अधिक संरचनात्मक भिन्नता उत्पन्न होती है। यद्यपि यह सेटअप एकल-छवि निर्माण के लिए आदर्श है, लेकिन यह विभिन्न विचारों के बीच वैश्विक स्थिरता सुनिश्चित करने के लिए ढांचे की क्षमता को सीमित करता है। इस बाधा को दूर करने के लिए, Zero123++ फ्रेमवर्क एक खिलौना कार्य करने के लिए स्टेबल डिफ्यूजन 2 वी-प्रीडिक्शन फ्रेमवर्क पर एक LoRA मॉडल को परिष्कृत करता है, और परिणाम नीचे दिखाए गए हैं।

स्केल्ड-लीनियर शोर शेड्यूल के साथ, लोरा मॉडल ओवरफिट नहीं होता है, लेकिन केवल छवि को थोड़ा सफेद करता है। इसके विपरीत, जब रैखिक शोर शेड्यूल के साथ काम करते हैं, तो LoRA फ्रेमवर्क इनपुट प्रॉम्प्ट के बावजूद सफलतापूर्वक एक खाली छवि उत्पन्न करता है, इस प्रकार विश्व स्तर पर नई आवश्यकताओं के अनुकूल फ्रेमवर्क की क्षमता पर शोर शेड्यूल के प्रभाव को दर्शाता है।
स्थानीय स्थितियों के लिए स्केल्ड संदर्भ ध्यान
ज़ीरो-1-टू-3 फ्रेमवर्क में एकल दृश्य इनपुट या कंडीशनिंग छवियों को छवि कंडीशनिंग के लिए फीचर आयाम में शोर इनपुट के साथ जोड़ा जाता है।
यह संयोजन लक्ष्य छवि और इनपुट के बीच गलत पिक्सेल-वार स्थानिक पत्राचार की ओर ले जाता है। उचित स्थानीय कंडीशनिंग इनपुट प्रदान करने के लिए, ज़ीरो123++ फ्रेमवर्क एक स्केल्ड रेफरेंस अटेंशन का उपयोग करता है, एक ऐसा दृष्टिकोण जिसमें एक डीनोइज़िंग यूनेट मॉडल को चलाने के लिए एक अतिरिक्त संदर्भ छवि पर संदर्भित किया जाता है, इसके बाद संदर्भ से वैल्यू मैट्रिक्स और सेल्फ-अटेंशन कुंजी को जोड़ा जाता है। जब मॉडल इनपुट को निरूपित किया जाता है, तो संबंधित ध्यान परतों पर छवि प्रदर्शित की जाती है, और इसे निम्नलिखित चित्र में प्रदर्शित किया जाता है।

संदर्भ ध्यान दृष्टिकोण, संदर्भ छवि के साथ बनावट जैसी साझा करने वाली छवियों और बिना किसी फ़ाइनट्यूनिंग के सिमेंटिक सामग्री उत्पन्न करने के लिए प्रसार मॉडल का मार्गदर्शन करने में सक्षम है। बढ़िया ट्यूनिंग के साथ, संदर्भ ध्यान दृष्टिकोण अव्यक्त पैमाने के साथ बेहतर परिणाम देता है।

वैश्विक कंडीशनिंग: फ्लेक्सडिफ्यूज़
मूल स्थिर प्रसार दृष्टिकोण में, टेक्स्ट एम्बेडिंग वैश्विक एम्बेडिंग के लिए एकमात्र स्रोत है, और यह दृष्टिकोण टेक्स्ट एम्बेडिंग और मॉडल लेटेंट्स के बीच क्रॉस-परीक्षा करने के लिए सीएलआईपी फ्रेमवर्क को टेक्स्ट एनकोडर के रूप में नियोजित करता है। परिणामस्वरूप, डेवलपर्स वैश्विक छवि कंडीशनिंग के लिए इसका उपयोग करने के लिए टेक्स्ट रिक्त स्थान और परिणामी सीएलआईपी छवियों के बीच संरेखण का उपयोग करने के लिए स्वतंत्र हैं।
Zero123++ फ्रेमवर्क वैश्विक छवि कंडीशनिंग को न्यूनतम के साथ फ्रेमवर्क में शामिल करने के लिए रैखिक मार्गदर्शन तंत्र के एक प्रशिक्षण योग्य संस्करण का उपयोग करने का प्रस्ताव करता है। फ़ाइन ट्यूनिंग आवश्यकता है, और परिणाम निम्नलिखित छवि में प्रदर्शित किए गए हैं। जैसा कि देखा जा सकता है, वैश्विक छवि कंडीशनिंग की उपस्थिति के बिना, फ्रेमवर्क द्वारा उत्पन्न सामग्री की गुणवत्ता इनपुट छवि के अनुरूप दृश्यमान क्षेत्रों के लिए संतोषजनक है। हालाँकि, अदृश्य क्षेत्रों के लिए फ्रेमवर्क द्वारा उत्पन्न छवि की गुणवत्ता में महत्वपूर्ण गिरावट देखी गई है, जिसका मुख्य कारण ऑब्जेक्ट के वैश्विक शब्दार्थ का अनुमान लगाने में मॉडल की असमर्थता है।

मॉडल वास्तुकला
Zero123++ फ्रेमवर्क को लेख में उल्लिखित विभिन्न दृष्टिकोणों और तकनीकों का उपयोग करके आधार के रूप में स्टेबल डिफ्यूजन 2v-मॉडल के साथ प्रशिक्षित किया गया है। Zero123++ फ्रेमवर्क को ओब्जैवर्स डेटासेट पर पूर्व-प्रशिक्षित किया गया है जो यादृच्छिक एचडीआरआई प्रकाश व्यवस्था के साथ प्रस्तुत किया गया है। ढांचा आवश्यक फाइन-ट्यूनिंग की मात्रा को और कम करने और पूर्व स्थिर प्रसार में जितना संभव हो सके संरक्षित करने के प्रयास में स्थिर प्रसार छवि विविधता ढांचे में उपयोग किए जाने वाले चरणबद्ध प्रशिक्षण अनुसूची दृष्टिकोण को भी अपनाता है।
Zero123++ ढांचे की कार्यप्रणाली या वास्तुकला को अनुक्रमिक चरणों या चरणों में विभाजित किया जा सकता है। पहले चरण में फ्रेमवर्क क्रॉस-अटेंशन लेयर्स के केवी मैट्रिसेस को ठीक करता है, और एडमडब्लू के ऑप्टिमाइज़र के साथ स्टेबल डिफ्यूजन की सेल्फ-अटेंशन लेयर्स, 1000 वार्म-अप स्टेप्स और कोसाइन लर्निंग रेट शेड्यूल 7×10 पर अधिकतम होता है।-5. दूसरे चरण में, फ्रेमवर्क 2000 वार्म अप सेट के साथ अत्यधिक रूढ़िवादी निरंतर सीखने की दर को नियोजित करता है, और प्रशिक्षण के दौरान दक्षता को अधिकतम करने के लिए मिन-एसएनआर दृष्टिकोण को नियोजित करता है।
Zero123++: परिणाम और प्रदर्शन तुलना
गुणात्मक प्रदर्शन
उत्पन्न गुणवत्ता के आधार पर Zero123++ ढांचे के प्रदर्शन का आकलन करने के लिए, इसकी तुलना SyncDreamer और Zero-1-to-3- XL से की जाती है, जो सामग्री निर्माण के लिए अत्याधुनिक रूपरेखाओं में से दो हैं। फ्रेमवर्क की तुलना अलग-अलग दायरे वाली चार इनपुट छवियों से की जाती है। पहली छवि एक इलेक्ट्रिक खिलौना बिल्ली की है, जो सीधे ओब्जावर्स डेटासेट से ली गई है, और यह वस्तु के पीछे के छोर पर एक बड़ी अनिश्चितता का दावा करती है। दूसरी आग बुझाने वाले यंत्र की छवि है, और तीसरी रॉकेट पर बैठे कुत्ते की छवि है, जो एसडीएक्सएल मॉडल द्वारा बनाई गई है। अंतिम छवि एक एनीमे चित्रण है। फ्रेमवर्क के लिए आवश्यक उन्नयन चरण वन-2-3-4-5 फ्रेमवर्क की ऊंचाई अनुमान पद्धति का उपयोग करके प्राप्त किए जाते हैं, और एसएएम फ्रेमवर्क का उपयोग करके पृष्ठभूमि निष्कासन प्राप्त किया जाता है। जैसा कि देखा जा सकता है, Zero123++ फ्रेमवर्क लगातार उच्च गुणवत्ता वाली मल्टी-व्यू छवियां उत्पन्न करता है, और आउट-ऑफ-डोमेन 2D चित्रण और AI-जनरेटेड छवियों को समान रूप से अच्छी तरह से सामान्यीकृत करने में सक्षम है।


मात्रात्मक विश्लेषण
अत्याधुनिक ज़ीरो-123-टू-1 और ज़ीरो-3टू-1 एक्सएल फ्रेमवर्क के मुकाबले ज़ीरो3++ फ्रेमवर्क की मात्रात्मक तुलना करने के लिए, डेवलपर्स सत्यापन विभाजन डेटा, एक उपसमूह पर इन मॉडलों के सीखे हुए अवधारणात्मक छवि पैच समानता (एलपीआईपीएस) स्कोर का मूल्यांकन करते हैं। ओब्जावर्स डेटासेट का। मल्टी-व्यू छवि निर्माण पर मॉडल के प्रदर्शन का मूल्यांकन करने के लिए, डेवलपर्स क्रमशः जमीनी सच्चाई संदर्भ छवियों और 6 उत्पन्न छवियों को टाइल करते हैं, और फिर सीखे गए अवधारणात्मक छवि पैच समानता (एलपीआईपीएस) स्कोर की गणना करते हैं। परिणाम नीचे प्रदर्शित किए गए हैं और जैसा कि स्पष्ट रूप से देखा जा सकता है, Zero123++ फ्रेमवर्क सत्यापन विभाजन सेट पर सर्वोत्तम प्रदर्शन प्राप्त करता है।

मल्टी-व्यू मूल्यांकन के लिए पाठ
टेक्स्ट से मल्टी-व्यू सामग्री निर्माण में Zero123++ फ्रेमवर्क की क्षमता का मूल्यांकन करने के लिए, डेवलपर्स पहले एक छवि उत्पन्न करने के लिए टेक्स्ट संकेतों के साथ SDXL फ्रेमवर्क का उपयोग करते हैं, और फिर उत्पन्न छवि के लिए Zero123++ फ्रेमवर्क को नियोजित करते हैं। परिणाम निम्नलिखित छवि में प्रदर्शित किए गए हैं, और जैसा कि देखा जा सकता है, जब ज़ीरो-1-टू-3 फ्रेमवर्क की तुलना की जाती है जो लगातार मल्टी-व्यू पीढ़ी की गारंटी नहीं दे सकता है, तो ज़ीरो123++ फ्रेमवर्क सुसंगत, यथार्थवादी और अत्यधिक विस्तृत मल्टी- देता है। को क्रियान्वित करके छवियाँ देखें पाठ-से-छवि-से-बहु-दृश्य दृष्टिकोण या पाइपलाइन.

जीरो123++ डेप्थ कंट्रोलनेट
बेस जीरो123++ फ्रेमवर्क के अलावा, डेवलपर्स ने डेप्थ कंट्रोलनेट जीरो123++ भी जारी किया है, जो कंट्रोलनेट आर्किटेक्चर का उपयोग करके निर्मित मूल फ्रेमवर्क का गहराई-नियंत्रित संस्करण है। सामान्यीकृत रैखिक छवियों को बाद की RGB छवियों के संबंध में प्रस्तुत किया जाता है, और एक कंट्रोलनेट फ्रेमवर्क को गहराई की धारणा का उपयोग करके Zero123++ फ्रेमवर्क की ज्यामिति को नियंत्रित करने के लिए प्रशिक्षित किया जाता है।

निष्कर्ष
इस लेख में, हमने Zero123++ के बारे में बात की है, जो एक छवि-वातानुकूलित प्रसार जनरेटिव AI मॉडल है जिसका उद्देश्य एकल दृश्य इनपुट का उपयोग करके 3D-संगत मल्टीपल-व्यू छवियां उत्पन्न करना है। पूर्व-प्रशिक्षित जेनरेटिव मॉडल से प्राप्त लाभ को अधिकतम करने के लिए, ज़ीरो123++ फ्रेमवर्क ऑफ-द-शेल्फ प्रसार छवि मॉडल से फाइनट्यून करने के लिए किए जाने वाले प्रयास की मात्रा को कम करने के लिए कई प्रशिक्षण और कंडीशनिंग योजनाओं को कार्यान्वित करता है। हमने ज़ीरो123++ फ्रेमवर्क द्वारा कार्यान्वित विभिन्न दृष्टिकोणों और संवर्द्धन पर भी चर्चा की है जो इसे वर्तमान अत्याधुनिक फ्रेमवर्क द्वारा प्राप्त किए गए परिणामों के बराबर और यहां तक कि उससे भी अधिक परिणाम प्राप्त करने में मदद करता है।
हालाँकि, इसकी दक्षता और लगातार उच्च-गुणवत्ता वाली बहु-दृश्य छवियां उत्पन्न करने की क्षमता के बावजूद, Zero123++ ढांचे में अभी भी सुधार की कुछ गुंजाइश है, जिसमें अनुसंधान के संभावित क्षेत्र शामिल हैं।
- दो-चरणीय रिफाइनर मॉडल जो स्थिरता के लिए वैश्विक आवश्यकताओं को पूरा करने में Zero123++ की असमर्थता को हल कर सकता है।
- अतिरिक्त स्केल-अप इससे भी उच्च गुणवत्ता की छवियां उत्पन्न करने की Zero123++ की क्षमता को और बढ़ाने के लिए।



