
Artificial Intelligence
मशीन लर्निंग बनाम डेटा साइंस: मुख्य अंतर

मशीन लर्निंग (एमएल) और डेटा साइंस दो अलग-अलग अवधारणाएं हैं जो कृत्रिम बुद्धिमत्ता (एआई) के क्षेत्र से संबंधित हैं। दोनों अवधारणाएँ उत्पादों, सेवाओं, प्रणालियों, निर्णय लेने की प्रक्रियाओं और बहुत कुछ को बेहतर बनाने के लिए डेटा पर निर्भर करती हैं। हमारी वर्तमान डेटा-संचालित दुनिया में मशीन लर्निंग और डेटा साइंस दोनों की करियर के लिए अत्यधिक मांग है।
एमएल और डेटा साइंस दोनों का उपयोग डेटा वैज्ञानिकों द्वारा अपने कार्य क्षेत्र में किया जाता है, और इन्हें लगभग हर उद्योग में अपनाया जा रहा है। इन क्षेत्रों में शामिल होने के इच्छुक किसी भी व्यक्ति के लिए, या किसी भी बिजनेस लीडर के लिए जो अपने संगठन में एआई-संचालित दृष्टिकोण अपनाना चाहता है, इन दो अवधारणाओं को समझना महत्वपूर्ण है।
मशीन लर्निंग क्या है?
मशीन लर्निंग का उपयोग अक्सर कृत्रिम बुद्धिमत्ता के साथ किया जाता है, लेकिन यह गलत है। यह एआई की एक अलग तकनीक और शाखा है जो डेटा निकालने और भविष्य के रुझानों की भविष्यवाणी करने के लिए एल्गोरिदम पर निर्भर करती है। मॉडलों के साथ प्रोग्राम किया गया सॉफ्टवेयर इंजीनियरों को डेटा सेट के भीतर पैटर्न को बेहतर ढंग से समझने में मदद करने के लिए सांख्यिकीय विश्लेषण जैसी तकनीकों का संचालन करने में मदद करता है।
मशीन लर्निंग वह है जो मशीनों को स्पष्ट रूप से प्रोग्राम किए बिना सीखने की क्षमता देती है, यही कारण है कि फेसबुक, ट्विटर, इंस्टाग्राम और यूट्यूब जैसी प्रमुख कंपनियां और सोशल मीडिया प्लेटफॉर्म इसका उपयोग रुचियों की भविष्यवाणी करने और सेवाओं, उत्पादों आदि की सिफारिश करने के लिए करते हैं।
उपकरण और अवधारणाओं के एक सेट के रूप में, मशीन लर्निंग डेटा विज्ञान का एक हिस्सा है। जैसा कि कहा गया है, इसकी पहुंच क्षेत्र से कहीं आगे तक है। डेटा वैज्ञानिक आमतौर पर जानकारी जल्दी से इकट्ठा करने और प्रवृत्ति विश्लेषण में सुधार करने के लिए मशीन लर्निंग पर भरोसा करते हैं।
जब मशीन लर्निंग इंजीनियरों की बात आती है, तो इन पेशेवरों को कई प्रकार के कौशल की आवश्यकता होती है, जैसे:
सांख्यिकी और संभाव्यता की गहरी समझ
कंप्यूटर विज्ञान में विशेषज्ञता
सॉफ्टवेयर इंजीनियरिंग और सिस्टम डिजाइन
प्रोग्रामिंग ज्ञान
डेटा मॉडलिंग और विश्लेषण

डेटा साइंस क्या है?
डेटा विज्ञान डेटा का अध्ययन है और तरीकों, एल्गोरिदम, टूल और सिस्टम की एक श्रृंखला का उपयोग करके इससे अर्थ कैसे निकालना है। ये सभी विशेषज्ञों को संरचित और असंरचित डेटा से अंतर्दृष्टि निकालने में सक्षम बनाते हैं। डेटा वैज्ञानिक आमतौर पर किसी संगठन के भंडार के भीतर बड़ी मात्रा में डेटा का अध्ययन करने के लिए जिम्मेदार होते हैं, और अध्ययन में अक्सर सामग्री मामले शामिल होते हैं और कंपनी द्वारा डेटा का लाभ कैसे उठाया जा सकता है।
संरचित या असंरचित डेटा का अध्ययन करके, डेटा वैज्ञानिक व्यवसाय या विपणन पैटर्न के बारे में मूल्यवान अंतर्दृष्टि प्राप्त कर सकते हैं, जिससे व्यवसाय प्रतिस्पर्धियों से बेहतर प्रदर्शन करने में सक्षम हो सकता है।
डेटा वैज्ञानिक अपने ज्ञान को व्यवसाय, सरकार और विभिन्न अन्य निकायों में लाभ बढ़ाने, उत्पादों को नया करने और बेहतर बुनियादी ढांचे और सार्वजनिक प्रणालियों के निर्माण के लिए लागू करते हैं।
स्मार्टफोन के प्रसार और दैनिक जीवन के कई हिस्सों के डिजिटलीकरण के कारण डेटा विज्ञान का क्षेत्र काफी उन्नत हो गया है, जिससे हमारे पास अविश्वसनीय मात्रा में डेटा उपलब्ध हो गया है। डेटा विज्ञान भी मूर के नियम से प्रभावित हुआ है, जो इस विचार को संदर्भित करता है कि कंप्यूटिंग की शक्ति में नाटकीय रूप से वृद्धि होती है जबकि समय के साथ सापेक्ष लागत में कमी आती है, जिससे सस्ती कंप्यूटिंग शक्ति की व्यापक पैमाने पर उपलब्धता होती है। डेटा विज्ञान इन दोनों नवाचारों को एक साथ जोड़ता है, और घटकों को मिलाकर, डेटा वैज्ञानिक डेटा से पहले से कहीं अधिक अंतर्दृष्टि प्राप्त कर सकते हैं।
डेटा विज्ञान के क्षेत्र में पेशेवरों को भी बहुत सारी प्रोग्रामिंग और डेटा एनालिटिक्स कौशल की आवश्यकता होती है, जैसे:
पायथन जैसी प्रोग्रामिंग भाषाओं की गहरी समझ
बड़ी मात्रा में संरचित और असंरचित डेटा के साथ काम करने की क्षमता
गणित, सांख्यिकी, संभाव्यता
डेटा विज़ुअलाइज़ेशन
व्यवसाय के लिए डेटा विश्लेषण और प्रसंस्करण
मशीन लर्निंग एल्गोरिदम और मॉडल
संचार और टीम सहयोग

मशीन लर्निंग और डेटा साइंस के बीच अंतर
प्रत्येक अवधारणा क्या है, इसे परिभाषित करने के बाद, मशीन लर्निंग और डेटा विज्ञान के बीच प्रमुख अंतरों पर ध्यान देना महत्वपूर्ण है। कृत्रिम बुद्धिमत्ता और गहन शिक्षा जैसी अन्य अवधारणाओं के साथ, इस तरह की अवधारणाएं कभी-कभी भ्रमित करने वाली और आसानी से मिश्रित हो सकती हैं।
डेटा विज्ञान डेटा के अध्ययन और उससे अर्थ निकालने पर केंद्रित है, जबकि मशीन लर्निंग में उन तरीकों को समझना और निर्माण करना शामिल है जो प्रदर्शन और भविष्यवाणियों को बेहतर बनाने के लिए डेटा का उपयोग करते हैं।
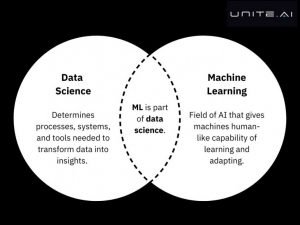
इसे रखने का दूसरा तरीका यह है कि डेटा विज्ञान का क्षेत्र उन प्रक्रियाओं, प्रणालियों और उपकरणों को निर्धारित करता है जो डेटा को अंतर्दृष्टि में बदलने के लिए आवश्यक हैं, जिन्हें बाद में विभिन्न उद्योगों में लागू किया जा सकता है। मशीन लर्निंग कृत्रिम बुद्धिमत्ता का एक क्षेत्र है जो मशीनों को सांख्यिकीय मॉडल और एल्गोरिदम के माध्यम से सीखने और अनुकूलन की मानव जैसी क्षमता प्राप्त करने में सक्षम बनाता है।
हालाँकि ये दो अलग-अलग अवधारणाएँ हैं, फिर भी इनमें कुछ ओवरलैप है। मशीन लर्निंग वास्तव में डेटा साइंस का हिस्सा है, और एल्गोरिदम डेटा साइंस द्वारा वितरित डेटा पर प्रशिक्षित होते हैं। उन दोनों में गणित, सांख्यिकी, संभाव्यता और प्रोग्रामिंग जैसे कुछ समान कौशल शामिल हैं।
डेटा साइंस और एमएल की चुनौतियाँ
डेटा साइंस और मशीन लर्निंग दोनों अपनी-अपनी चुनौतियाँ प्रस्तुत करते हैं, जो दोनों अवधारणाओं को अलग करने में भी मदद करती हैं।
मशीन लर्निंग की प्राथमिक चुनौतियों में डेटासेट में डेटा या विविधता की कमी शामिल है, जिससे मूल्यवान अंतर्दृष्टि निकालना मुश्किल हो जाता है। यदि कोई डेटा उपलब्ध नहीं है तो कोई मशीन सीख नहीं सकती है, जबकि डेटासेट की कमी से पैटर्न को समझना अधिक कठिन हो जाता है। मशीन लर्निंग की एक और चुनौती यह है कि यह संभावना नहीं है कि कोई एल्गोरिदम जानकारी निकाल सकता है जब कोई भिन्नता न हो या कम हो।
जब डेटा विज्ञान की बात आती है, तो इसकी मुख्य चुनौतियों में सटीक विश्लेषण के लिए विभिन्न प्रकार की जानकारी और डेटा की आवश्यकता शामिल है। दूसरा यह है कि डेटा विज्ञान के परिणाम कभी-कभी किसी व्यवसाय में निर्णय निर्माताओं द्वारा प्रभावी ढंग से उपयोग नहीं किए जाते हैं, और टीमों को अवधारणा समझाना कठिन हो सकता है। यह विभिन्न गोपनीयता और नैतिक मुद्दों को भी प्रस्तुत करता है।
प्रत्येक अवधारणा के अनुप्रयोग
जबकि जब अनुप्रयोगों की बात आती है तो डेटा विज्ञान और मशीन लर्निंग में कुछ ओवरलैप होते हैं, हम प्रत्येक को तोड़ सकते हैं।
यहां डेटा विज्ञान अनुप्रयोगों के कुछ उदाहरण दिए गए हैं:
- इंटरनेट खोज: Google खोज एक सेकंड के एक अंश में विशिष्ट परिणाम खोजने के लिए डेटा विज्ञान पर निर्भर करती है।
- सिफ़ारिश प्रणाली: डेटा विज्ञान अनुशंसा प्रणालियों के निर्माण की कुंजी है।
- छवि/वाक् पहचान: सिरी और एलेक्सा जैसी वाक् पहचान प्रणालियाँ, छवि पहचान प्रणालियों की तरह, डेटा विज्ञान पर निर्भर करती हैं।
- गेमिंग: गेमिंग की दुनिया गेमिंग अनुभव को बढ़ाने के लिए डेटा साइंस तकनीक का उपयोग करती है।
यहां मशीन लर्निंग के कुछ उदाहरण अनुप्रयोग दिए गए हैं:
- वित्त: पूरे वित्त उद्योग में मशीन लर्निंग का व्यापक रूप से उपयोग किया जाता है, बैंक डेटा के अंदर पैटर्न की पहचान करने और धोखाधड़ी को रोकने के लिए इस पर भरोसा करते हैं।
- स्वचालन: मशीन लर्निंग विभिन्न उद्योगों में कार्यों को स्वचालित करने में मदद करता है, जैसे विनिर्माण संयंत्रों में रोबोट।
- सरकार: मशीन लर्निंग का उपयोग सिर्फ निजी क्षेत्र में नहीं किया जाता है। सरकारी संगठन इसका उपयोग सार्वजनिक सुरक्षा और उपयोगिताओं के प्रबंधन के लिए करते हैं।
- स्वास्थ्य देखभाल: मशीन लर्निंग कई तरह से स्वास्थ्य सेवा उद्योग को बाधित कर रही है। यह इमेज डिटेक्शन के साथ मशीन लर्निंग को अपनाने वाले पहले उद्योगों में से एक था।
यदि आप इन क्षेत्रों में कुछ कौशल हासिल करना चाहते हैं, तो सर्वोत्तम प्रमाणपत्रों की हमारी सूची देखना सुनिश्चित करें डेटा विज्ञान और यंत्र अधिगम.















