
कृत्रिम बुद्धिमत्ता
मैजिकडांस: यथार्थवादी मानव नृत्य वीडियो पीढ़ी

कंप्यूटर दृष्टि एआई उद्योग में सबसे अधिक चर्चा वाले क्षेत्रों में से एक है, वास्तविक समय के कार्यों की एक विस्तृत श्रृंखला में इसके संभावित अनुप्रयोगों के लिए धन्यवाद। हाल के वर्षों में, कंप्यूटर विज़न फ्रेमवर्क तेजी से उन्नत हुआ है, आधुनिक मॉडल अब वास्तविक समय के परिदृश्यों में चेहरे की विशेषताओं, वस्तुओं और बहुत कुछ का विश्लेषण करने में सक्षम हैं। इन क्षमताओं के बावजूद, मानव गति हस्तांतरण कंप्यूटर विज़न मॉडल के लिए एक विकट चुनौती बनी हुई है। इस कार्य में स्रोत छवि या वीडियो से लक्ष्य छवि या वीडियो पर चेहरे और शरीर की गतिविधियों को पुनः लक्षित करना शामिल है। छवियों या वीडियो को स्टाइल करने, मल्टीमीडिया सामग्री को संपादित करने, डिजिटल मानव संश्लेषण और यहां तक कि धारणा-आधारित ढांचे के लिए डेटा उत्पन्न करने के लिए कंप्यूटर विज़न मॉडल में मानव गति हस्तांतरण का व्यापक रूप से उपयोग किया जाता है।
इस लेख में, हम मैजिकडांस पर ध्यान केंद्रित करते हैं, जो मानव गति हस्तांतरण में क्रांति लाने के लिए डिज़ाइन किया गया एक प्रसार-आधारित मॉडल है। मैजिकडांस फ्रेमवर्क का लक्ष्य विशेष रूप से 2डी मानव चेहरे के भाव और गति को चुनौतीपूर्ण मानव नृत्य वीडियो में स्थानांतरित करना है। इसका लक्ष्य मूल पहचान को बनाए रखते हुए विशिष्ट लक्ष्य पहचान के लिए नवीन मुद्रा अनुक्रम-संचालित नृत्य वीडियो तैयार करना है। मैजिकडांस ढांचा दो-चरणीय प्रशिक्षण रणनीति को नियोजित करता है, जो मानव गति के विघटन और त्वचा की टोन, चेहरे के भाव और कपड़ों जैसे उपस्थिति कारकों पर ध्यान केंद्रित करता है। हम मैजिकडांस ढांचे में गहराई से उतरेंगे, अन्य अत्याधुनिक मानव गति हस्तांतरण ढांचे की तुलना में इसकी वास्तुकला, कार्यक्षमता और प्रदर्शन की खोज करेंगे। आइए गोता लगाएँ।
मैजिकडांस: यथार्थवादी मानव गति स्थानांतरण
जैसा कि पहले उल्लेख किया गया है, मानव गति स्थानांतरण सबसे जटिल कंप्यूटर विज़न कार्यों में से एक है क्योंकि मानव गति और अभिव्यक्तियों को स्रोत छवि या वीडियो से लक्ष्य छवि या वीडियो में स्थानांतरित करने में अत्यधिक जटिलता शामिल है। परंपरागत रूप से, कंप्यूटर विज़न फ्रेमवर्क ने GAN या सहित कार्य-विशिष्ट जेनरेटर मॉडल को प्रशिक्षित करके मानव गति हस्तांतरण हासिल किया है जनरेटिव एडवरसियर नेटवर्क चेहरे के भावों और शारीरिक मुद्राओं के लिए लक्षित डेटासेट पर। हालाँकि प्रशिक्षण और जनरेटिव मॉडल का उपयोग कुछ मामलों में संतोषजनक परिणाम देते हैं, लेकिन वे आमतौर पर दो प्रमुख सीमाओं से ग्रस्त होते हैं।
- वे छवि विकृत करने वाले घटक पर बहुत अधिक भरोसा करते हैं जिसके परिणामस्वरूप वे अक्सर परिप्रेक्ष्य में बदलाव या आत्म-प्रकटीकरण के कारण स्रोत छवि में अदृश्य शरीर के हिस्सों को प्रक्षेपित करने के लिए संघर्ष करते हैं।
- वे बाहरी रूप से प्राप्त अन्य छवियों का सामान्यीकरण नहीं कर सकते हैं जो विशेष रूप से जंगली में वास्तविक समय के परिदृश्यों में उनके अनुप्रयोगों को सीमित करता है।

आधुनिक प्रसार मॉडल ने विभिन्न स्थितियों में असाधारण छवि निर्माण क्षमताओं का प्रदर्शन किया है, और प्रसार मॉडल अब वेब-स्केल छवि डेटासेट से सीखकर वीडियो निर्माण और छवि इनपेंटिंग जैसे डाउनस्ट्रीम कार्यों की एक श्रृंखला पर शक्तिशाली दृश्य प्रस्तुत करने में सक्षम हैं। अपनी क्षमताओं के कारण, प्रसार मॉडल मानव गति हस्तांतरण कार्यों के लिए एक आदर्श विकल्प हो सकते हैं। यद्यपि प्रसार मॉडल को मानव गति हस्तांतरण के लिए लागू किया जा सकता है, लेकिन इसमें उत्पन्न सामग्री की गुणवत्ता के संदर्भ में, या मॉडल डिजाइन और प्रशिक्षण रणनीति सीमाओं के परिणामस्वरूप पहचान संरक्षण या अस्थायी विसंगतियों से पीड़ित होने के संदर्भ में कुछ सीमाएं हैं। इसके अलावा, प्रसार-आधारित मॉडल कोई महत्वपूर्ण लाभ प्रदर्शित नहीं करते हैं जीएएन ढाँचे सामान्यीकरण की दृष्टि से.
मानव गति हस्तांतरण कार्यों पर प्रसार और जीएएन आधारित ढांचे के सामने आने वाली बाधाओं को दूर करने के लिए, डेवलपर्स ने मैजिकडांस पेश किया है, एक नया ढांचा जिसका उद्देश्य मानव गति हस्तांतरण के लिए प्रसार ढांचे की क्षमता का फायदा उठाना है, जो अभूतपूर्व स्तर की पहचान संरक्षण, बेहतर दृश्य गुणवत्ता का प्रदर्शन करता है। और डोमेन सामान्यीकरण। इसके मूल में, मैजिकडांस फ्रेमवर्क की मूल अवधारणा समस्या को दो चरणों में विभाजित करना है: उपस्थिति नियंत्रण और गति नियंत्रण, सटीक गति हस्तांतरण आउटपुट देने के लिए छवि प्रसार ढांचे के लिए आवश्यक दो क्षमताएं।

उपरोक्त आंकड़ा मैजिकडांस ढांचे का एक संक्षिप्त विवरण देता है, और जैसा कि देखा जा सकता है, ढांचा इसे नियोजित करता है स्थिर प्रसार मॉडल, और दो अतिरिक्त घटकों को भी तैनात करता है: उपस्थिति नियंत्रण मॉडल और पोज़ कंट्रोलनेट जहां पूर्व ध्यान के माध्यम से एक संदर्भ छवि से एसडी मॉडल को उपस्थिति मार्गदर्शन प्रदान करता है जबकि बाद वाला एक वातानुकूलित छवि या वीडियो से प्रसार मॉडल को अभिव्यक्ति/मुद्रा मार्गदर्शन प्रदान करता है। यह ढांचा मुद्रा नियंत्रण और उपस्थिति को सुलझाने के लिए इन उप-मॉड्यूल को प्रभावी ढंग से सीखने के लिए एक बहु-स्तरीय प्रशिक्षण रणनीति भी नियोजित करता है।
संक्षेप में, मैजिकडांस ढांचा एक है
- नवीन और प्रभावी रूपरेखा जिसमें उपस्थिति-विघटित मुद्रा नियंत्रण और उपस्थिति नियंत्रण पूर्व-प्रशिक्षण शामिल है।
- मैजिकडांस ढांचा मुद्रा स्थिति इनपुट और संदर्भ छवियों या वीडियो के नियंत्रण में यथार्थवादी मानव चेहरे के भाव और मानव गति उत्पन्न करने में सक्षम है।
- मैजिकडांस फ्रेमवर्क का लक्ष्य एक मल्टी-सोर्स अटेंशन मॉड्यूल पेश करके उपस्थिति-संगत मानव सामग्री उत्पन्न करना है जो स्थिर प्रसार यूनेट ढांचे के लिए सटीक मार्गदर्शन प्रदान करता है।
- मैजिकडांस फ्रेमवर्क का उपयोग स्टेबल डिफ्यूजन फ्रेमवर्क के लिए एक सुविधाजनक एक्सटेंशन या प्लग-इन के रूप में भी किया जा सकता है, और यह मौजूदा मॉडल वेट के साथ संगतता भी सुनिश्चित करता है क्योंकि इसमें मापदंडों की अतिरिक्त फाइन-ट्यूनिंग की आवश्यकता नहीं होती है।
इसके अतिरिक्त, मैजिकडांस ढांचा उपस्थिति और गति सामान्यीकरण दोनों के लिए असाधारण सामान्यीकरण क्षमताएं दिखाता है।
- उपस्थिति सामान्यीकरण: जब विविध उपस्थिति उत्पन्न करने की बात आती है तो मैजिकडांस ढांचा बेहतर क्षमताओं का प्रदर्शन करता है।
- मोशन सामान्यीकरण: मैजिकडांस फ्रेमवर्क में गति की एक विस्तृत श्रृंखला उत्पन्न करने की क्षमता भी है।
मैजिकडांस: उद्देश्य और वास्तुकला
किसी वास्तविक मानव या शैलीबद्ध छवि की दी गई संदर्भ छवि के लिए, मैजिकडांस फ्रेमवर्क का प्राथमिक उद्देश्य इनपुट और मुद्रा इनपुट {पी, एफ} पर वातानुकूलित आउटपुट छवि या आउटपुट वीडियो उत्पन्न करना है जहां पी मानव मुद्रा का प्रतिनिधित्व करता है कंकाल और एफ चेहरे के स्थलों का प्रतिनिधित्व करते हैं। उत्पन्न आउटपुट छवि या वीडियो को मुद्रा इनपुट द्वारा परिभाषित मुद्रा और अभिव्यक्तियों को बनाए रखते हुए संदर्भ छवि में मौजूद पृष्ठभूमि सामग्री के साथ-साथ शामिल मनुष्यों की उपस्थिति और पहचान को संरक्षित करने में सक्षम होना चाहिए।
आर्किटेक्चर
प्रशिक्षण के दौरान, मैजिकडांस फ्रेमवर्क को संदर्भ छवि और उसी संदर्भ वीडियो से प्राप्त इनपुट इनपुट के साथ जमीनी सच्चाई को फिर से बनाने के लिए एक फ्रेम पुनर्निर्माण कार्य के रूप में प्रशिक्षित किया जाता है। गति हस्तांतरण प्राप्त करने के लिए परीक्षण के दौरान, पोज़ इनपुट और संदर्भ छवि विभिन्न स्रोतों से प्राप्त की जाती है।
मैजिकडांस ढांचे की समग्र वास्तुकला को चार श्रेणियों में विभाजित किया जा सकता है: प्रारंभिक चरण, उपस्थिति नियंत्रण प्रीट्रेनिंग, उपस्थिति-विघटित मुद्रा नियंत्रण, और मोशन मॉड्यूल।
प्रारंभिक अवस्था
लेटेंट डिफ्यूजन मॉडल या एलडीएम एक ऑटोएनकोडर के उपयोग द्वारा सुविधाजनक अव्यक्त स्थान के भीतर संचालित करने के लिए विशिष्ट रूप से डिजाइन किए गए डिफ्यूजन मॉडल का प्रतिनिधित्व करता है, और स्टेबल डिफ्यूजन फ्रेमवर्क एलडीएम का एक उल्लेखनीय उदाहरण है जो एक वेक्टर क्वांटाइज्ड-वेरिएशनल को नियोजित करता है। ऑटोएन्कोडर और अस्थायी यू-नेट आर्किटेक्चर। स्थिर प्रसार मॉडल टेक्स्ट इनपुट को एम्बेडिंग में परिवर्तित करके टेक्स्ट इनपुट को संसाधित करने के लिए टेक्स्ट एनकोडर के रूप में एक सीएलआईपी-आधारित ट्रांसफार्मर को नियोजित करता है। स्टेबल डिफ्यूजन फ्रेमवर्क का प्रशिक्षण चरण मॉडल को एक टेक्स्ट स्थिति और एक इनपुट छवि के साथ उजागर करता है, जिसमें छवि के एन्कोडिंग को एक अव्यक्त प्रतिनिधित्व में शामिल करने की प्रक्रिया होती है, और इसे गॉसियन विधि द्वारा निर्देशित प्रसार चरणों के पूर्वनिर्धारित अनुक्रम के अधीन किया जाता है। परिणामी अनुक्रम एक शोर अव्यक्त प्रतिनिधित्व उत्पन्न करता है जो स्थिर प्रसार ढांचे के प्राथमिक सीखने के उद्देश्य के साथ एक मानक सामान्य वितरण प्रदान करता है जो शोर अव्यक्त अभ्यावेदन को अव्यक्त अभ्यावेदन में पुनरावृत्त रूप से दर्शाता है।
उपस्थिति नियंत्रण पूर्व प्रशिक्षण
मूल कंट्रोलनेट फ्रेमवर्क के साथ एक प्रमुख मुद्दा स्थानिक रूप से अलग-अलग गतियों के बीच उपस्थिति को नियंत्रित करने में इसकी असमर्थता है, हालांकि यह इनपुट छवि के समान पोज़ वाली छवियां उत्पन्न करता है, जिसमें समग्र उपस्थिति मुख्य रूप से पाठ्य इनपुट से प्रभावित होती है। यद्यपि यह विधि काम करती है, यह उन कार्यों से जुड़े गति हस्तांतरण के लिए उपयुक्त नहीं है जहां यह पाठ्य इनपुट नहीं है बल्कि संदर्भ छवि है जो उपस्थिति जानकारी के लिए प्राथमिक स्रोत के रूप में कार्य करती है।
मैजिकडांस फ्रेमवर्क में उपस्थिति नियंत्रण पूर्व-प्रशिक्षण मॉड्यूल को परत-दर-परत दृष्टिकोण में उपस्थिति नियंत्रण के लिए मार्गदर्शन प्रदान करने के लिए एक सहायक शाखा के रूप में डिज़ाइन किया गया है। पाठ इनपुट पर भरोसा करने के बजाय, समग्र मॉड्यूल विशेष रूप से जटिल गति गतिशीलता वाले परिदृश्यों में उपस्थिति विशेषताओं को सटीक रूप से उत्पन्न करने के लिए ढांचे की क्षमता को बढ़ाने के उद्देश्य से संदर्भ छवि से उपस्थिति विशेषताओं का लाभ उठाने पर ध्यान केंद्रित करता है। इसके अलावा, यह केवल उपस्थिति नियंत्रण मॉडल है जो उपस्थिति नियंत्रण पूर्व-प्रशिक्षण के दौरान प्रशिक्षित किया जा सकता है।
उपस्थिति-विच्छेदित मुद्रा नियंत्रण
आउटपुट छवि में मुद्रा को नियंत्रित करने का एक सरल समाधान पूर्व-प्रशिक्षित कंट्रोलनेट मॉडल को पूर्व-प्रशिक्षित उपस्थिति नियंत्रण मॉडल के साथ बिना फाइन-ट्यूनिंग के सीधे एकीकृत करना है। हालाँकि, एकीकरण के परिणामस्वरूप ढाँचा उपस्थिति-स्वतंत्र पोज़ नियंत्रण के साथ संघर्ष कर सकता है जिससे इनपुट पोज़ और उत्पन्न पोज़ के बीच विसंगति हो सकती है। इस विसंगति से निपटने के लिए, मैजिकडांस फ्रेमवर्क पूर्व-प्रशिक्षित उपस्थिति नियंत्रण मॉडल के साथ संयुक्त रूप से पोज़ कंट्रोलनेट मॉडल को ठीक करता है।
मोशन मॉड्यूल
एक साथ काम करने पर, अपीयरेंस-असंबद्ध पोज़ कंट्रोलनेट और अपीयरेंस कंट्रोल मॉडल गति हस्तांतरण के लिए सटीक और प्रभावी छवि प्राप्त कर सकते हैं, हालांकि इसके परिणामस्वरूप अस्थायी असंगतता हो सकती है। अस्थायी स्थिरता सुनिश्चित करने के लिए, फ्रेमवर्क प्राथमिक स्थिर प्रसार यूनेट आर्किटेक्चर में एक अतिरिक्त गति मॉड्यूल को एकीकृत करता है।
मैजिकडांस: प्री-ट्रेनिंग और डेटासेट
प्री-ट्रेनिंग के लिए, मैजिकडांस फ्रेमवर्क एक टिकटॉक डेटासेट का उपयोग करता है जिसमें 350 से 10 सेकंड के बीच अलग-अलग लंबाई के 15 से अधिक नृत्य वीडियो होते हैं, जिनमें से अधिकांश वीडियो में नाचते हुए एक व्यक्ति का चेहरा और शरीर का ऊपरी हिस्सा शामिल होता है। इंसान। मैजिकडांस फ्रेमवर्क प्रत्येक व्यक्तिगत वीडियो को 30 एफपीएस पर निकालता है, और पोज़ कंकाल, हाथ पोज़ और चेहरे के स्थलों का अनुमान लगाने के लिए प्रत्येक फ्रेम पर व्यक्तिगत रूप से ओपनपोज़ चलाता है।
पूर्व-प्रशिक्षण के लिए, उपस्थिति नियंत्रण मॉडल को 64 x 8 के छवि आकार के साथ 100 हजार चरणों के लिए 10 एनवीडिया ए512 जीपीयू पर 512 के बैच आकार के साथ पूर्व-प्रशिक्षित किया जाता है, इसके बाद संयुक्त रूप से मुद्रा नियंत्रण और उपस्थिति नियंत्रण मॉडल को ठीक किया जाता है। 16 हजार चरणों के लिए 20 का एक बैच आकार। प्रशिक्षण के दौरान, मैजिकडांस फ्रेमवर्क बेतरतीब ढंग से लक्ष्य और संदर्भ के रूप में दो फ़्रेमों का नमूना लेता है, जिसमें छवियों को समान ऊंचाई पर समान स्थिति में क्रॉप किया जाता है। मूल्यांकन के दौरान, मॉडल छवि को बेतरतीब ढंग से क्रॉप करने के बजाय केंद्रीय रूप से क्रॉप करता है।
मैजिकडांस: परिणाम
मैजिकडांस फ्रेमवर्क पर किए गए प्रायोगिक परिणाम निम्नलिखित छवि में प्रदर्शित किए गए हैं, और जैसा कि देखा जा सकता है, मैजिकडांस फ्रेमवर्क सभी मेट्रिक्स में मानव गति हस्तांतरण के लिए डिस्को और ड्रीमपोज़ जैसे मौजूदा फ्रेमवर्क से बेहतर प्रदर्शन करता है। अपने नाम के आगे "*" वाले फ़्रेमवर्क सीधे इनपुट के रूप में लक्ष्य छवि का उपयोग करते हैं, और अन्य फ़्रेमवर्क की तुलना में अधिक जानकारी शामिल करते हैं।
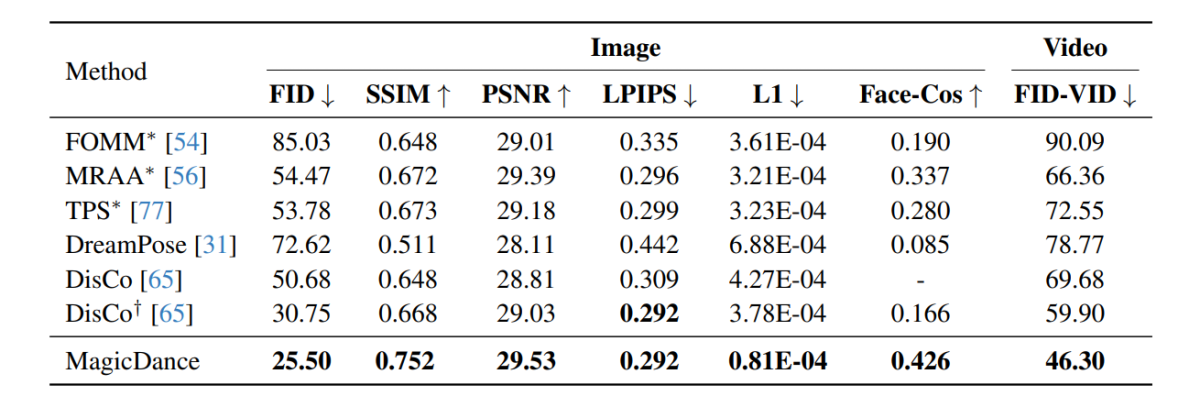
यह ध्यान रखना दिलचस्प है कि मैजिकडांस फ्रेमवर्क ने 0.426 का फेस-कॉस स्कोर प्राप्त किया है, जो डिस्को फ्रेमवर्क की तुलना में 156.62% का सुधार है, और ड्रीमपोज़ फ्रेमवर्क की तुलना में लगभग 400% की वृद्धि है। परिणाम पहचान की जानकारी को संरक्षित करने के लिए मैजिकडांस ढांचे की मजबूत क्षमता का संकेत देते हैं, और प्रदर्शन में दृश्यमान वृद्धि मौजूदा अत्याधुनिक तरीकों पर मैजिकडांस ढांचे की श्रेष्ठता को इंगित करती है।
निम्नलिखित आंकड़े मैजिकडांस, डिस्को और टीपीएस फ्रेमवर्क के बीच मानव वीडियो निर्माण की गुणवत्ता की तुलना करते हैं। जैसा कि देखा जा सकता है, जीटी, डिस्को और टीपीएस फ्रेमवर्क द्वारा उत्पन्न परिणाम असंगत मानव मुद्रा पहचान और चेहरे के भावों से ग्रस्त हैं।

इसके अलावा, निम्नलिखित छवि मैजिकडांस फ्रेमवर्क के साथ टिकटॉक डेटासेट पर चेहरे की अभिव्यक्ति और मानव मुद्रा हस्तांतरण के दृश्य को प्रदर्शित करती है, जो संदर्भ इनपुट से पहचान की जानकारी को सटीक रूप से संरक्षित करते हुए विविध चेहरे के स्थलों और मुद्रा कंकाल इनपुट के तहत यथार्थवादी और ज्वलंत अभिव्यक्ति और गति उत्पन्न करने में सक्षम है। छवि।

यह ध्यान देने योग्य है कि मैजिकडांस फ्रेमवर्क लक्ष्य डोमेन पर किसी भी अतिरिक्त फाइन-ट्यूनिंग के बिना भी प्रभावशाली उपस्थिति नियंत्रणीयता के साथ अनदेखी मुद्रा और शैलियों की आउट-ऑफ-डोमेन संदर्भ छवियों के लिए असाधारण सामान्यीकरण क्षमताओं का दावा करता है, जिसके परिणाम निम्नलिखित छवि में प्रदर्शित होते हैं। .

निम्नलिखित छवियां चेहरे की अभिव्यक्ति हस्तांतरण और शून्य-शॉट मानव गति के संदर्भ में मैजिकडांस ढांचे की विज़ुअलाइज़ेशन क्षमताओं को प्रदर्शित करती हैं। जैसा कि देखा जा सकता है, मैजिकडांस ढांचा जंगली मानवीय गतिविधियों को पूरी तरह से सामान्यीकृत करता है।

मैजिकडांस: सीमाएं
ओपनपोज़ मैजिकडांस फ्रेमवर्क का एक अनिवार्य घटक है क्योंकि यह पोज़ नियंत्रण के लिए महत्वपूर्ण भूमिका निभाता है, जो उत्पन्न छवियों की गुणवत्ता और अस्थायी स्थिरता को महत्वपूर्ण रूप से प्रभावित करता है। हालाँकि, मैजिकडांस फ्रेमवर्क को अभी भी चेहरे के स्थलों का पता लगाना और कंकालों को सटीक रूप से चित्रित करना थोड़ा चुनौतीपूर्ण लगता है, खासकर जब छवियों में वस्तुएं आंशिक रूप से दिखाई देती हैं, या तेजी से गति दिखाती हैं। इन समस्याओं के परिणामस्वरूप उत्पन्न छवि में कलाकृतियाँ हो सकती हैं।
निष्कर्ष
इस लेख में, हमने मैजिकडांस के बारे में बात की है, जो एक प्रसार-आधारित मॉडल है जिसका उद्देश्य मानव गति हस्तांतरण में क्रांति लाना है। मैजिकडांस फ्रेमवर्क पहचान को स्थिर रखते हुए विशिष्ट लक्ष्य पहचान के लिए नवीन मुद्रा अनुक्रम संचालित मानव नृत्य वीडियो बनाने के विशिष्ट उद्देश्य के साथ चुनौतीपूर्ण मानव नृत्य वीडियो पर 2डी मानव चेहरे के भाव और गति को स्थानांतरित करने का प्रयास करता है। मैजिकडांस फ्रेमवर्क मानव गति के विघटन और त्वचा की टोन, चेहरे के भाव और कपड़ों जैसी उपस्थिति के लिए दो-चरणीय प्रशिक्षण रणनीति है।
मैजिकडांस चेहरे और गति अभिव्यक्ति हस्तांतरण को शामिल करके यथार्थवादी मानव वीडियो पीढ़ी की सुविधा प्रदान करने के लिए एक नया दृष्टिकोण है, और किसी भी अतिरिक्त फाइन-ट्यूनिंग की आवश्यकता के बिना जंगली एनीमेशन पीढ़ी में लगातार सक्षम करने में सक्षम है जो मौजूदा तरीकों पर महत्वपूर्ण प्रगति दर्शाता है। इसके अलावा, मैजिकडांस फ्रेमवर्क जटिल गति अनुक्रमों और विविध मानवीय पहचानों पर असाधारण सामान्यीकरण क्षमताओं को प्रदर्शित करता है, जिससे मैजिकडांस फ्रेमवर्क एआई सहायता प्राप्त गति हस्तांतरण और वीडियो पीढ़ी के क्षेत्र में अग्रणी धावक के रूप में स्थापित होता है।













 |