
Artificial Intelligence
EfficientViT: उच्च-रिज़ॉल्यूशन कंप्यूटर विज़न के लिए मेमोरी कुशल विज़न ट्रांसफार्मर

अपनी उच्च मॉडल क्षमता के कारण, विज़न ट्रांसफार्मर मॉडल को हाल के दिनों में काफी सफलता मिली है। उनके प्रदर्शन के बावजूद, विज़न ट्रांसफार्मर मॉडल में एक बड़ी खामी है: उनकी उल्लेखनीय गणना क्षमता उच्च गणना लागत पर आती है, और यही कारण है कि विज़न ट्रांसफार्मर वास्तविक समय के अनुप्रयोगों के लिए पहली पसंद नहीं हैं। इस समस्या से निपटने के लिए, डेवलपर्स के एक समूह ने हाई-स्पीड विज़न ट्रांसफार्मर का एक परिवार, EfficientViT लॉन्च किया।
EfficientViT पर काम करते समय, डेवलपर्स ने देखा कि वर्तमान ट्रांसफार्मर मॉडल की गति अक्सर अकुशल मेमोरी ऑपरेशंस, विशेष रूप से तत्व-वार फ़ंक्शन और एमएचएसए या मल्टी-हेड सेल्फ अटेंशन नेटवर्क में टेंसर रीशेपिंग द्वारा सीमित होती है। इन अकुशल मेमोरी ऑपरेशंस से निपटने के लिए, EfficientViT डेवलपर्स ने सैंडविच लेआउट का उपयोग करके एक नए बिल्डिंग ब्लॉक पर काम किया है, यानी EfficientViT मॉडल कुशल FFN परतों के बीच एकल मेमोरी-बाउंड मल्टी-हेड सेल्फ अटेंशन नेटवर्क का उपयोग करता है जो मेमोरी दक्षता में सुधार करने में मदद करता है, और समग्र चैनल संचार को भी बढ़ाना। इसके अलावा, मॉडल यह भी पता लगाता है कि ध्यान मानचित्रों में अक्सर शीर्षों में उच्च समानताएं होती हैं जो कम्प्यूटेशनल अतिरेक की ओर ले जाती हैं। अतिरेक समस्या से निपटने के लिए, EfficientViT मॉडल एक कैस्केड समूह ध्यान मॉड्यूल प्रस्तुत करता है जो पूर्ण सुविधा के विभिन्न विभाजनों के साथ ध्यान प्रमुखों को फीड करता है। यह विधि न केवल कम्प्यूटेशनल लागत बचाने में मदद करती है, बल्कि मॉडल की ध्यान विविधता में भी सुधार करती है।
विभिन्न परिदृश्यों में EfficientViT मॉडल पर किए गए व्यापक प्रयोगों से संकेत मिलता है कि EfficientViT मौजूदा कुशल मॉडल से बेहतर प्रदर्शन करता है। कंप्यूटर दृष्टि सटीकता और गति के बीच एक अच्छा समझौता करते हुए। तो आइए गहराई से देखें, और EfficientViT मॉडल को थोड़ा और गहराई से देखें।
विज़न ट्रांसफॉर्मर और कुशलViT का परिचय
विज़न ट्रांसफ़ॉर्मर्स कंप्यूटर विज़न उद्योग में सबसे लोकप्रिय ढांचों में से एक बने हुए हैं क्योंकि वे बेहतर प्रदर्शन और उच्च कम्प्यूटेशनल क्षमताएं प्रदान करते हैं। हालाँकि, विज़न ट्रांसफार्मर मॉडल की सटीकता और प्रदर्शन में लगातार सुधार के साथ, परिचालन लागत और कम्प्यूटेशनल ओवरहेड में भी वृद्धि होती है। उदाहरण के लिए, SwinV2 और V-MoE जैसे ImageNet डेटासेट पर अत्याधुनिक प्रदर्शन प्रदान करने के लिए जाने जाने वाले वर्तमान मॉडल क्रमशः 3B और 14.7B मापदंडों का उपयोग करते हैं। कम्प्यूटेशनल लागत और आवश्यकताओं के साथ इन मॉडलों का विशाल आकार उन्हें वास्तविक समय के उपकरणों और अनुप्रयोगों के लिए व्यावहारिक रूप से अनुपयुक्त बनाता है।
एफिशिएंटनेट मॉडल का लक्ष्य यह पता लगाना है कि प्रदर्शन को कैसे बढ़ावा दिया जाए दृष्टि ट्रांसफार्मर मॉडल, और कुशल और प्रभावी ट्रांसफार्मर-आधारित फ्रेमवर्क आर्किटेक्चर को डिजाइन करने के पीछे शामिल सिद्धांतों को खोजना। EfficientViT मॉडल स्विम और DeiT जैसे मौजूदा विज़न ट्रांसफॉर्मर फ्रेमवर्क पर आधारित है, और यह तीन आवश्यक कारकों का विश्लेषण करता है जो गणना अतिरेक, मेमोरी एक्सेस और पैरामीटर उपयोग सहित मॉडल हस्तक्षेप गति को प्रभावित करते हैं। इसके अलावा, मॉडल का मानना है कि मेमोरी-बाउंड में विज़न ट्रांसफार्मर मॉडल की गति, जिसका अर्थ है कि सीपीयू/जीपीयू में कंप्यूटिंग शक्ति का पूर्ण उपयोग मेमोरी एक्सेसिंग देरी से प्रतिबंधित या प्रतिबंधित है, जिसके परिणामस्वरूप ट्रांसफार्मर की रनटाइम गति पर नकारात्मक प्रभाव पड़ता है। . एमएचएसए या मल्टी-हेड सेल्फ अटेंशन नेटवर्क में एलिमेंट-वार फ़ंक्शन और टेंसर रीशेपिंग सबसे मेमोरी-अक्षम ऑपरेशन हैं। मॉडल आगे देखता है कि एफएफएन (फीड फॉरवर्ड नेटवर्क) और एमएचएसए के बीच अनुपात को इष्टतम रूप से समायोजित करने से प्रदर्शन को प्रभावित किए बिना मेमोरी एक्सेस समय को काफी कम करने में मदद मिल सकती है। हालाँकि, मॉडल समान रैखिक अनुमानों को सीखने के लिए ध्यान प्रमुख की प्रवृत्ति के परिणामस्वरूप ध्यान मानचित्रों में कुछ अतिरेक भी देखता है।
यह मॉडल EfficientViT के शोध कार्य के दौरान निष्कर्षों की अंतिम खेती है। मॉडल में सैंडविच लेआउट के साथ एक नया ब्लैक फीचर है जो फीड फॉरवर्ड नेटवर्क या एफएफएन परतों के बीच एकल मेमोरी-बाउंड एमएचएसए परत लागू करता है। यह दृष्टिकोण न केवल एमएचएसए में मेमोरी-बाउंड संचालन को निष्पादित करने में लगने वाले समय को कम करता है, बल्कि यह विभिन्न चैनलों के बीच संचार को सुविधाजनक बनाने के लिए अधिक एफएफएन परतों की अनुमति देकर पूरी प्रक्रिया को अधिक मेमोरी कुशल बनाता है। मॉडल एक नए सीजीए या कैस्केड ग्रुप अटेंशन मॉड्यूल का भी उपयोग करता है जिसका उद्देश्य न केवल ध्यान प्रमुखों में कम्प्यूटेशनल अतिरेक को कम करके गणनाओं को अधिक प्रभावी बनाना है, बल्कि नेटवर्क की गहराई को भी बढ़ाना है जिसके परिणामस्वरूप मॉडल क्षमता में वृद्धि होती है। अंत में, मॉडल मूल्य अनुमानों सहित आवश्यक नेटवर्क घटकों की चैनल चौड़ाई का विस्तार करता है, जबकि फ्रेमवर्क में मापदंडों को पुनर्वितरित करने के लिए फीड फॉरवर्ड नेटवर्क में छिपे आयामों जैसे कम मूल्य वाले नेटवर्क घटकों को सिकोड़ता है।

जैसा कि उपरोक्त छवि में देखा जा सकता है, कुशलViT ढांचा सटीकता और गति दोनों के मामले में वर्तमान अत्याधुनिक CNN और ViT मॉडल से बेहतर प्रदर्शन करता है। लेकिन EfficientViT ढाँचे ने कुछ मौजूदा अत्याधुनिक ढाँचों से बेहतर प्रदर्शन करने का प्रबंधन कैसे किया? आइए इसका पता लगाएं।
EfficientViT: विज़न ट्रांसफार्मर की दक्षता में सुधार
EfficientViT मॉडल का लक्ष्य तीन दृष्टिकोणों का उपयोग करके मौजूदा विज़न ट्रांसफार्मर मॉडल की दक्षता में सुधार करना है,
- कम्प्यूटेशनल अतिरेक.
- मेमोरी एक्सेस.
- पैरामीटर उपयोग.
मॉडल का लक्ष्य यह पता लगाना है कि उपरोक्त पैरामीटर दृष्टि ट्रांसफार्मर मॉडल की दक्षता को कैसे प्रभावित करते हैं, और बेहतर दक्षता के साथ बेहतर परिणाम प्राप्त करने के लिए उन्हें कैसे हल किया जाए। आइए उनके बारे में थोड़ा और गहराई से बात करें।
मेमोरी पहुंच और दक्षता
किसी मॉडल की गति को प्रभावित करने वाले आवश्यक कारकों में से एक है मेमोरी एक्सेस ओवरहेड या एमएओ. जैसा कि नीचे दी गई छवि में देखा जा सकता है, ट्रांसफॉर्मर में तत्व-वार जोड़, सामान्यीकरण और बार-बार रीशेपिंग सहित कई ऑपरेटर मेमोरी-अक्षम संचालन हैं, क्योंकि उन्हें विभिन्न मेमोरी इकाइयों तक पहुंच की आवश्यकता होती है जो एक समय लेने वाली प्रक्रिया है।
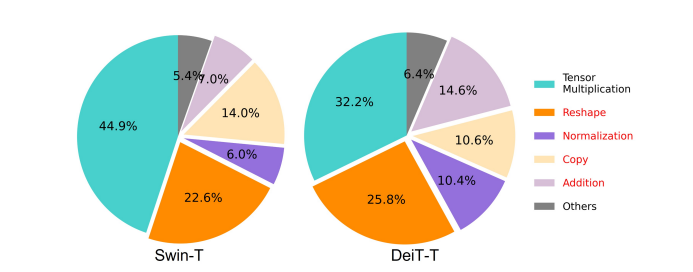
हालाँकि कुछ मौजूदा विधियाँ हैं जो निम्न-रैंक सन्निकटन और विरल ध्यान जैसी मानक सॉफ्टमैक्स स्व-ध्यान गणनाओं को सरल बना सकती हैं, वे अक्सर सीमित त्वरण प्रदान करते हैं, और सटीकता को कम करते हैं।
दूसरी ओर, EfficientViT फ्रेमवर्क का लक्ष्य फ्रेमवर्क में मेमोरी-अक्षम परतों की मात्रा को कम करके मेमोरी एक्सेस लागत में कटौती करना है। मॉडल 1.25X और 1.5X के उच्च हस्तक्षेप थ्रूपुट के साथ DeiT-T और Swin-T को छोटे सबनेटवर्क में स्केल करता है, और MHSA परतों के अनुपात के साथ इन सबनेटवर्क के प्रदर्शन की तुलना करता है। जैसा कि नीचे दी गई छवि में देखा जा सकता है, लागू होने पर, दृष्टिकोण एमएचएसए परतों की सटीकता को लगभग 20 से 40% तक बढ़ा देता है।

संगणना दक्षता
एमएचएसए परतें इनपुट अनुक्रम को कई उप-स्थानों या शीर्षों में एम्बेड करती हैं, और व्यक्तिगत रूप से ध्यान मानचित्रों की गणना करती हैं, एक दृष्टिकोण जो प्रदर्शन को बढ़ावा देने के लिए जाना जाता है। हालाँकि, ध्यान मानचित्र कम्प्यूटेशनल रूप से सस्ते नहीं हैं, और कम्प्यूटेशनल लागतों का पता लगाने के लिए, EfficientViT मॉडल यह पता लगाता है कि छोटे ViT मॉडल में अनावश्यक ध्यान को कैसे कम किया जाए। मॉडल 1.25× अनुमान गति-अप के साथ चौड़ाई कम किए गए डीईआईटी-टी और स्विम-टी मॉडल को प्रशिक्षित करके प्रत्येक ब्लॉक के भीतर प्रत्येक हेड और शेष हेड की अधिकतम कोसाइन समानता को मापता है। जैसा कि नीचे दी गई छवि में देखा जा सकता है, ध्यान शीर्षों के बीच समानता की एक उच्च संख्या है जो बताती है कि मॉडल में गणना अतिरेक होती है क्योंकि कई शीर्ष सटीक पूर्ण सुविधा के समान अनुमान सीखते हैं।

विभिन्न पैटर्न सीखने के लिए प्रमुखों को प्रोत्साहित करने के लिए, मॉडल स्पष्ट रूप से एक सहज ज्ञान युक्त समाधान लागू करता है जिसमें प्रत्येक प्रमुख को पूर्ण सुविधा का केवल एक हिस्सा खिलाया जाता है, एक तकनीक जो समूह कनवल्शन के विचार से मिलती जुलती है। मॉडल डाउनस्केल्ड मॉडल के विभिन्न पहलुओं को प्रशिक्षित करता है जिसमें संशोधित एमएचएसए परतें होती हैं।
पैरामीटर दक्षता
औसत वीआईटी मॉडल को अपनी डिज़ाइन रणनीतियाँ विरासत में मिलती हैं जैसे अनुमानों के लिए समतुल्य चौड़ाई का उपयोग करना, एफएफएन में विस्तार अनुपात को 4 पर सेट करना, और एनएलपी ट्रांसफार्मर से चरणों पर हेड बढ़ाना। हल्के मॉड्यूल के लिए इन घटकों के कॉन्फ़िगरेशन को सावधानीपूर्वक फिर से डिज़ाइन करने की आवश्यकता है। एफिशिएंटवीआईटी मॉडल स्विम-टी और डीईआईटी-टी परतों में आवश्यक घटकों को स्वचालित रूप से खोजने के लिए टेलर संरचित प्रूनिंग को तैनात करता है, और अंतर्निहित पैरामीटर आवंटन सिद्धांतों का पता लगाता है। कुछ संसाधन बाधाओं के तहत, छंटाई विधियां महत्वहीन चैनलों को हटा देती हैं, और उच्चतम संभव सटीकता सुनिश्चित करने के लिए महत्वपूर्ण चैनलों को बनाए रखती हैं। नीचे दिया गया आंकड़ा स्वाइन-टी फ्रेमवर्क पर प्रूनिंग से पहले और बाद में इनपुट एम्बेडिंग के चैनलों के अनुपात की तुलना करता है। यह देखा गया कि: बेसलाइन सटीकता: 79.1%; काट-छाँट सटीकता: 76.5%

उपरोक्त छवि इंगित करती है कि ढांचे के पहले दो चरण अधिक आयामों को संरक्षित करते हैं, जबकि अंतिम दो चरण बहुत कम आयामों को संरक्षित करते हैं। इसका मतलब यह हो सकता है कि एक विशिष्ट चैनल कॉन्फ़िगरेशन जो प्रत्येक चरण के बाद चैनल को दोगुना कर देता है या सभी ब्लॉकों के लिए समतुल्य चैनलों का उपयोग करता है, जिसके परिणामस्वरूप अंतिम कुछ ब्लॉकों में पर्याप्त अतिरेक हो सकता है।
कुशल दृष्टि ट्रांसफार्मर: वास्तुकला
उपरोक्त विश्लेषण के दौरान प्राप्त सीखों के आधार पर, डेवलपर्स ने एक नया पदानुक्रमित मॉडल बनाने पर काम किया जो तेज़ हस्तक्षेप गति प्रदान करता है, कुशलViT नमूना। आइए EfficientViT ढांचे की संरचना पर एक विस्तृत नज़र डालें। नीचे दिया गया चित्र आपको EfficientViT ढाँचे का एक सामान्य विचार देता है।
कुशलViT फ्रेमवर्क के बिल्डिंग ब्लॉक्स
अधिक कुशल विज़न ट्रांसफार्मर नेटवर्क के लिए बिल्डिंग ब्लॉक को नीचे दिए गए चित्र में दिखाया गया है।

फ्रेमवर्क में एक कैस्केड समूह ध्यान मॉड्यूल, मेमोरी-कुशल सैंडविच लेआउट और एक पैरामीटर रीलोकेशन रणनीति शामिल है जो क्रमशः गणना, मेमोरी और पैरामीटर के संदर्भ में मॉडल की दक्षता में सुधार करने पर ध्यान केंद्रित करती है। आइए उनके बारे में अधिक विस्तार से बात करें।
सैंडविच लेआउट
फ्रेमवर्क के लिए अधिक प्रभावी और कुशल मेमोरी ब्लॉक बनाने के लिए मॉडल एक नए सैंडविच लेआउट का उपयोग करता है। सैंडविच लेआउट कम मेमोरी-बाउंड स्व-ध्यान परतों का उपयोग करता है, और चैनल संचार के लिए अधिक मेमोरी-कुशल फ़ीड फ़ॉरवर्ड नेटवर्क का उपयोग करता है। अधिक विशिष्ट होने के लिए, मॉडल स्थानिक मिश्रण के लिए एकल आत्म-ध्यान परत लागू करता है जो एफएफएन परतों के बीच सैंडविच होता है। डिज़ाइन न केवल आत्म-ध्यान परतों के कारण मेमोरी समय की खपत को कम करने में मदद करता है, बल्कि एफएफएन परतों के उपयोग के लिए नेटवर्क के भीतर विभिन्न चैनलों के बीच प्रभावी संचार की अनुमति भी देता है। मॉडल DWConv या डिसेप्टिव कन्वोल्यूशन का उपयोग करके प्रत्येक फ़ीड फ़ॉरवर्ड नेटवर्क परत से पहले एक अतिरिक्त इंटरेक्शन टोकन परत भी लागू करता है, और स्थानीय संरचनात्मक जानकारी के आगमनात्मक पूर्वाग्रह को पेश करके मॉडल क्षमता को बढ़ाता है।
कैस्केड समूह का ध्यान
एमएचएसए परतों के साथ प्रमुख मुद्दों में से एक ध्यान प्रमुखों में अतिरेक है जो गणनाओं को और अधिक अक्षम बना देता है। समस्या को हल करने के लिए, मॉडल विज़न ट्रांसफार्मर के लिए सीजीए या कैस्केड ग्रुप अटेंशन का प्रस्ताव करता है, एक नया ध्यान मॉड्यूल जो कुशल सीएनएन में समूह संकल्पों से प्रेरणा लेता है। इस दृष्टिकोण में, मॉडल अलग-अलग शीर्षों को पूर्ण विशेषताओं के विभाजन के साथ फ़ीड करता है, और इसलिए ध्यान की गणना को सभी प्रमुखों में स्पष्ट रूप से विघटित करता है। प्रत्येक शीर्ष पर पूर्ण सुविधाओं को खिलाने के बजाय सुविधाओं को विभाजित करने से गणना की बचत होती है, और प्रक्रिया अधिक कुशल हो जाती है, और मॉडल उन सुविधाओं पर अनुमानों को सीखने के लिए परतों को प्रोत्साहित करके सटीकता और इसकी क्षमता में और भी सुधार करने पर काम करना जारी रखता है जिनमें समृद्ध जानकारी होती है।

पैरामीटर पुनर्आवंटन
मापदंडों की दक्षता में सुधार करने के लिए, मॉडल महत्वपूर्ण मॉड्यूल के चैनल की चौड़ाई का विस्तार करके नेटवर्क में मापदंडों को पुनः आवंटित करता है, जबकि इतने महत्वपूर्ण मॉड्यूल की चैनल चौड़ाई को कम नहीं करता है। टेलर विश्लेषण के आधार पर, मॉडल या तो प्रत्येक चरण के दौरान प्रत्येक सिर में अनुमानों के लिए छोटे चैनल आयाम निर्धारित करता है या मॉडल अनुमानों को इनपुट के समान आयाम रखने की अनुमति देता है। इसके पैरामीटर अतिरेक में सहायता के लिए फ़ीड फ़ॉरवर्ड नेटवर्क का विस्तार अनुपात भी 2 से घटाकर 4 कर दिया गया है। प्रस्तावित पुनर्आवंटन रणनीति जिसे EfficientViT फ्रेमवर्क लागू करता है, महत्वपूर्ण मॉड्यूल के लिए अधिक चैनल आवंटित करता है ताकि उन्हें उच्च आयामी स्थान में प्रतिनिधित्व को बेहतर ढंग से सीखने की अनुमति मिल सके जो फीचर जानकारी के नुकसान को कम करता है। इसके अलावा, हस्तक्षेप प्रक्रिया को तेज करने और मॉडल की दक्षता को और भी बढ़ाने के लिए, मॉडल स्वचालित रूप से महत्वहीन मॉड्यूल में अनावश्यक मापदंडों को हटा देता है।

EfficientViT ढांचे का अवलोकन उपरोक्त छवि में समझाया जा सकता है जहां भाग,
- कुशलViT की वास्तुकला,
- सैंडविच लेआउट ब्लॉक,
- कैस्केड समूह का ध्यान.
कुशलViT: नेटवर्क आर्किटेक्चर

उपरोक्त छवि EfficientViT फ्रेमवर्क के नेटवर्क आर्किटेक्चर का सारांश प्रस्तुत करती है। मॉडल एक ओवरलैपिंग पैच एम्बेडिंग [20,80] पेश करता है जो 16×16 पैच को सी1 आयाम टोकन में एम्बेड करता है जो निम्न-स्तरीय दृश्य प्रतिनिधित्व सीखने में बेहतर प्रदर्शन करने के लिए मॉडल की क्षमता को बढ़ाता है। मॉडल के आर्किटेक्चर में तीन चरण शामिल हैं, जहां प्रत्येक चरण EfficientViT फ्रेमवर्क के प्रस्तावित बिल्डिंग ब्लॉक्स को ढेर करता है, और प्रत्येक सबसैंपलिंग परत (रिज़ॉल्यूशन के 2× सबसैंपलिंग) पर टोकन की संख्या 4X कम हो जाती है। उप-नमूनाकरण को अधिक कुशल बनाने के लिए, मॉडल एक उप-नमूना ब्लॉक का प्रस्ताव करता है जिसमें प्रस्तावित सैंडविच लेआउट भी होता है, इस अपवाद के साथ कि एक उलटा अवशिष्ट ब्लॉक नमूनाकरण के दौरान जानकारी के नुकसान को कम करने के लिए ध्यान परत को बदल देता है। इसके अलावा, पारंपरिक लेयरनॉर्म (एलएन) के बजाय, मॉडल बैचनॉर्म (बीएन) का उपयोग करता है क्योंकि बीएन को पूर्ववर्ती रैखिक या दृढ़ परतों में मोड़ा जा सकता है जो इसे एलएन पर रनटाइम लाभ देता है।
कुशलViT मॉडल परिवार
EfficientViT मॉडल परिवार में अलग-अलग गहराई और चौड़ाई के पैमाने के साथ 6 मॉडल होते हैं, और प्रत्येक चरण के लिए हेड्स की एक निर्धारित संख्या आवंटित की जाती है। अंतिम चरणों की तुलना में मॉडल शुरुआती चरणों में कम ब्लॉक का उपयोग करते हैं, यह प्रक्रिया MobileNetV3 फ्रेमवर्क के समान है क्योंकि बड़े रिज़ॉल्यूशन के साथ प्रारंभिक चरण प्रसंस्करण की प्रक्रिया में समय लगता है। बाद के चरणों में अतिरेक को कम करने के लिए एक छोटे कारक के साथ चरणों में चौड़ाई बढ़ाई जाती है। नीचे संलग्न तालिका EfficientViT मॉडल परिवार का वास्तुशिल्प विवरण प्रदान करती है जहां C, L, और H विशेष चरण में चौड़ाई, गहराई और सिरों की संख्या को संदर्भित करते हैं।

कुशलViT: मॉडल कार्यान्वयन और परिणाम
EfficientViT मॉडल का कुल बैच आकार 2,048 है, इसे टिम और पायटोरच के साथ बनाया गया है, 300 एनवीडिया वी8 जीपीयू का उपयोग करके 100 युगों के लिए स्क्रैच से प्रशिक्षित किया गया है, एक कोसाइन लर्निंग रेट शेड्यूलर, एक एडमडब्ल्यू ऑप्टिमाइज़र का उपयोग करता है, और इमेजनेट पर अपने छवि वर्गीकरण प्रयोग का संचालन करता है। -1K. इनपुट छवियों को बेतरतीब ढंग से क्रॉप किया जाता है और 224×224 के रिज़ॉल्यूशन में उनका आकार बदल दिया जाता है। उन प्रयोगों के लिए जिनमें डाउनस्ट्रीम छवि वर्गीकरण शामिल है, EfficientViT फ्रेमवर्क मॉडल को 300 युगों के लिए परिष्कृत करता है, और 256 के बैच आकार के साथ एडमडब्ल्यू ऑप्टिमाइज़र का उपयोग करता है। मॉडल COCO पर ऑब्जेक्ट डिटेक्शन के लिए रेटिननेट का उपयोग करता है, और आगे 12 के लिए मॉडल को प्रशिक्षित करने के लिए आगे बढ़ता है। समान सेटिंग्स वाले युग।
इमेजनेट पर परिणाम
EfficientViT के प्रदर्शन का विश्लेषण करने के लिए, इसकी तुलना ImageNet डेटासेट पर वर्तमान ViT और CNN मॉडल से की जाती है। तुलना के परिणाम निम्नलिखित चित्र में दर्शाए गए हैं। जैसा कि देखा जा सकता है कि EfficientViT मॉडल परिवार ज्यादातर मामलों में मौजूदा ढांचे से बेहतर प्रदर्शन करता है, और गति और सटीकता के बीच एक आदर्श व्यापार-बंद प्राप्त करने का प्रबंधन करता है।

कुशल सीएनएन और कुशल वीआईटी के साथ तुलना
मॉडल सबसे पहले अपने प्रदर्शन की तुलना एफिशिएंटनेट जैसे कुशल सीएनएन और मोबाइलनेट्स जैसे वेनिला सीएनएन फ्रेमवर्क से करता है। जैसा कि देखा जा सकता है कि मोबाइलनेट फ्रेमवर्क की तुलना में, एफिशिएंटवीआईटी मॉडल बेहतर टॉप-1 सटीकता स्कोर प्राप्त करते हैं, जबकि इंटेल सीपीयू और वी3.0 जीपीयू पर क्रमशः 2.5X और 100X तेज चलते हैं।
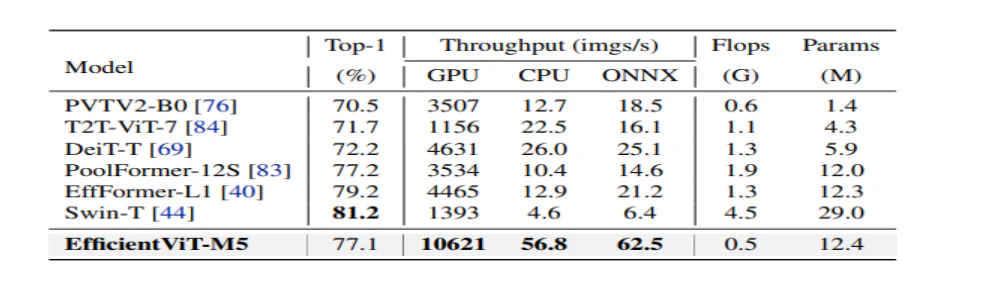
उपरोक्त चित्र कुशलViT मॉडल के प्रदर्शन की तुलना ImageNet-1K डेटासेट पर चलने वाले अत्याधुनिक बड़े पैमाने के ViT मॉडल से करता है।
डाउनस्ट्रीम छवि वर्गीकरण
मॉडल की स्थानांतरण सीखने की क्षमताओं का अध्ययन करने के लिए EfficientViT मॉडल को विभिन्न डाउनस्ट्रीम कार्यों पर लागू किया जाता है, और नीचे दी गई छवि प्रयोग के परिणामों को सारांशित करती है। जैसा कि देखा जा सकता है, EfficientViT-M5 मॉडल बहुत अधिक थ्रूपुट बनाए रखते हुए सभी डेटासेट में बेहतर या समान परिणाम प्राप्त करने का प्रबंधन करता है। एकमात्र अपवाद कार डेटासेट है, जहां EfficientViT मॉडल सटीकता प्रदान करने में विफल रहता है।

ऑब्जेक्ट डिटेक्शन
वस्तुओं का पता लगाने के लिए EfficientViT की क्षमता का विश्लेषण करने के लिए, इसकी तुलना COCO ऑब्जेक्ट डिटेक्शन कार्य पर कुशल मॉडलों से की जाती है, और नीचे दी गई छवि तुलना के परिणामों को सारांशित करती है।

निष्कर्ष
इस लेख में, हमने एफिशिएंटवीआईटी के बारे में बात की है, जो तेज दृष्टि ट्रांसफार्मर मॉडल का एक परिवार है जो कैस्केड समूह ध्यान का उपयोग करता है, और मेमोरी-कुशल संचालन प्रदान करता है। EfficientViT के प्रदर्शन का विश्लेषण करने के लिए किए गए व्यापक प्रयोगों ने आशाजनक परिणाम दिखाए हैं क्योंकि EfficientViT मॉडल ज्यादातर मामलों में वर्तमान CNN और विज़न ट्रांसफार्मर मॉडल से बेहतर प्रदर्शन करता है। हमने उन कारकों पर एक विश्लेषण प्रदान करने का भी प्रयास किया है जो दृष्टि ट्रांसफार्मर की हस्तक्षेप गति को प्रभावित करने में भूमिका निभाते हैं।















