Intelligence artificielle
Trois défis à venir pour Stable Diffusion

La sortie du modèle de synthèse d’images de diffusion latente Stable Diffusion de stability.ai il y a quelques semaines peut être l’une des divulgations technologiques les plus significatives depuis DeCSS en 1999 ; c’est certainement l’événement le plus important dans l’imagerie générée par l’IA depuis le code de deepfakes en 2017 a été copié sur GitHub et forké dans ce qui allait devenir DeepFaceLab et FaceSwap, ainsi que le logiciel de diffusion de deepfakes en temps réel DeepFaceLive.
À un moment donné, la frustration des utilisateurs face aux restrictions de contenu dans l’API de synthèse d’images DALL-E 2 ont été balayées, car il s’est avéré que le filtre NSFW de Stable Diffusion pouvait être désactivé en modifiant une seule ligne de code. Les Reddits de Stable Diffusion axés sur la pornographie ont surgi presque immédiatement, et ont été rapidement supprimés, tandis que le camp des développeurs et des utilisateurs s’est divisé sur Discord en communautés officielles et NSFW, et Twitter a commencé à se remplir de créations fantastiques de Stable Diffusion.
Actuellement, chaque jour semble apporter une innovation incroyable des développeurs qui ont adopté le système, avec des plug-ins et des ajouts tiers écrits à la hâte pour Krita, Photoshop, Cinema4D, Blender, et de nombreuses autres plateformes d’applications.
https://www.youtube.com/watch?v=MVPu2L88jIw
Entre-temps, promptcraft – l’art professionnel actuel de ‘chuchotement IA’, qui risque de devenir l’option de carrière la plus courte depuis ‘Filofax binder’ – est déjà en train de se commercialiser, tandis que la monétisation précoce de Stable Diffusion a lieu au niveau Patreon, avec la certitude de propositions plus sophistiquées à venir, pour ceux qui ne veulent pas naviguer dans des installations basées sur Conda du code source, ou les filtres NSFW prescrits des implémentations basées sur le Web.
Le rythme de développement et le sentiment de liberté d’exploration des utilisateurs se déroulent à une vitesse vertigineuse, il est difficile de voir très loin à l’avance. Essentiellement, nous ne savons pas exactement à quoi nous avons affaire pour le moment, ou quelles sont toutes les limites ou possibilités.
Néanmoins, essayons de jeter un coup d’œil à trois des défis les plus intéressants et les plus stimulants pour la communauté Stable Diffusion, qui se forme et grandit rapidement, pour affronter et, espérons-le, surmonter.
1 : Optimiser les pipelines basés sur des tuiles
Présentés avec des ressources matérielles limitées et des limites strictes sur la résolution des images d’entraînement, il semble probable que les développeurs trouveront des solutions pour améliorer à la fois la qualité et la résolution de la sortie de Stable Diffusion. Beaucoup de ces projets sont sur le point d’exploiter les limites du système, comme sa résolution native de seulement 512×512 pixels.
Comme c’est toujours le cas avec les initiatives de vision par ordinateur et de synthèse d’images, Stable Diffusion a été formé sur des images à ratio carré, dans ce cas échantillonné à 512×512, afin que les images sources puissent être régularisées et puissent tenir dans les contraintes des GPU qui ont formé le modèle.
Par conséquent, Stable Diffusion ‘pense’ (si cela pense du tout) en termes de 512×512, et certainement en termes carrés. De nombreux utilisateurs qui testent actuellement les limites du système rapportent que Stable Diffusion produit les résultats les plus fiables et les moins buggés à ce ratio d’aspect plutôt contraint (voir ‘adresser les extrémités’ ci-dessous).
Bien que diverses implémentations présentent un upscale via RealESRGAN (et peuvent corriger les visages mal rendus via GFPGAN) plusieurs utilisateurs développent actuellement des méthodes pour diviser les images en sections de 512x512px et les coudre ensemble pour former des œuvres composites plus grandes.

Cette image 1024×576, une résolution habituellement impossible dans un seul rendu de Stable Diffusion, a été créée en copiant et en collant le fichier attention.py Python à partir de la fourche DoggettX de Stable Diffusion (une version qui met en œuvre le upscale basé sur des tuiles) dans une autre fourche. Source : https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Bien que certaines initiatives de ce type utilisent du code original ou d’autres bibliothèques, le port txt2imghd de GOBIG (un mode dans la diffusion ProgRockDiffusion gourmande en VRAM) devrait fournir cette fonctionnalité à la branche principale bientôt. Alors que txt2imghd est un port dédié de GOBIG, d’autres efforts des développeurs de la communauté impliquent différentes implémentations de GOBIG.

Une image abstraite commode dans le rendu original 512x512px (à gauche et deuxième à gauche) ; mis à l’échelle par ESGRAN, qui est maintenant plus ou moins natif dans toutes les distributions de Stable Diffusion ; et donné ‘une attention spéciale’ via une implémentation de GOBIG, produisant des détails qui, au moins dans les limites de la section d’image, semblent mieux mis à l’échelle. Source : https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Le type d’exemple abstrait présenté ci-dessus comporte de nombreux ‘petits royaumes’ de détails qui conviennent à cette approche solipsiste de mise à l’échelle, mais qui peuvent nécessiter des solutions de code plus complexes pour produire une mise à l’échelle non répétitive et cohérente qui ne semble pas avoir été assemblée à partir de nombreuses parties. Pas moins, dans le cas des visages humains, où nous sommes inhabituellement sensibles aux aberrations ou aux artefacts ‘choquants’. Par conséquent, les visages peuvent finalement nécessiter une solution dédiée.
Stable Diffusion n’a actuellement aucun mécanisme pour se concentrer sur le visage pendant un rendu de la même manière que les humains priorisent les informations faciales. Bien que certains développeurs dans les communautés Discord envisagent des méthodes pour mettre en œuvre ce type d’ ‘attention améliorée’, il est actuellement beaucoup plus facile d’améliorer manuellement (et, éventuellement, automatiquement) le visage après que le rendu initial ait eu lieu.
Un visage humain a une logique sémantique interne et complète qui ne sera pas trouvée dans une ‘tuile’ de l’angle inférieur d’un bâtiment, par exemple, et il est donc actuellement possible de ‘zoomer’ et de rendre à nouveau un visage ‘esquissé’ dans la sortie de Stable Diffusion.

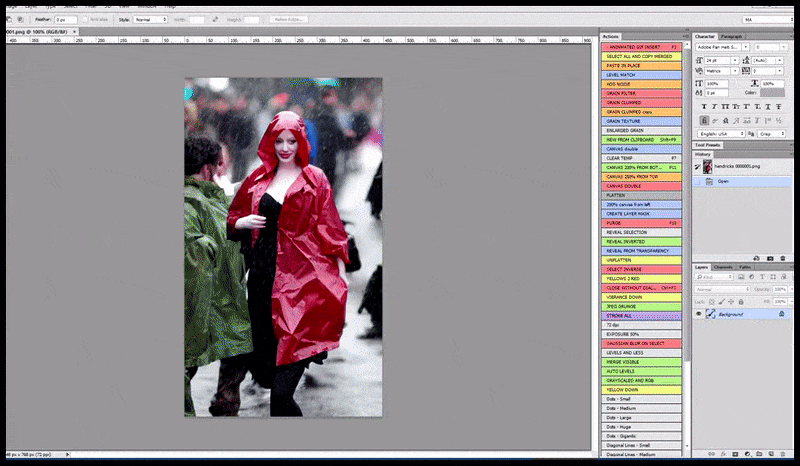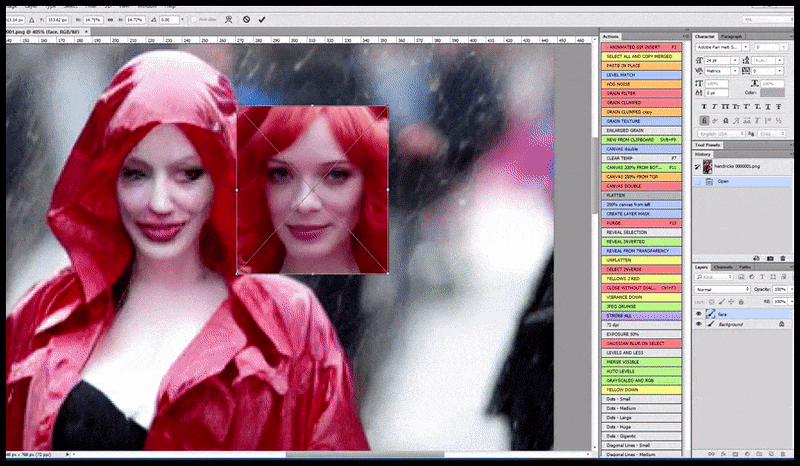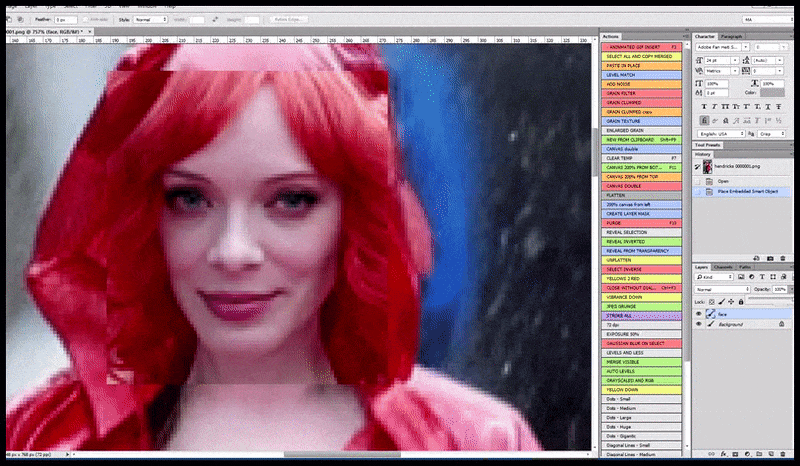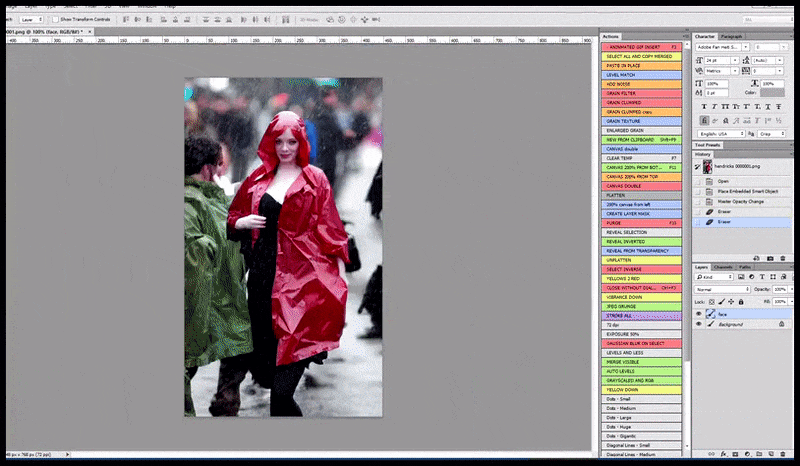
À gauche, la première tentative de Stable Diffusion avec la invite ‘Photo couleur à plein corps de Christina Hendricks entrant dans un endroit bondé, portant un imperméable ; Canon50, contact visuel, détails élevés, détails faciaux élevés’. À droite, un visage amélioré obtenu en alimentant le visage flou et esquissé du premier rendu dans l’attention complète de Stable Diffusion à l’aide d’Img2Img (voir les images animées ci-dessous).
Dans l’absence d’une solution d’inversion textuelle dédiée (voir ci-dessous), cela ne fonctionnera que pour les images de célébrités où la personne en question est déjà bien représentée dans les sous-ensembles de données LAION qui ont formé Stable Diffusion. Par conséquent, cela fonctionnera sur les personnes comme Tom Cruise, Brad Pitt, Jennifer Lawrence, et une gamme limitée de véritables personnalités médiatiques présentes en grand nombre d’images dans les données sources.
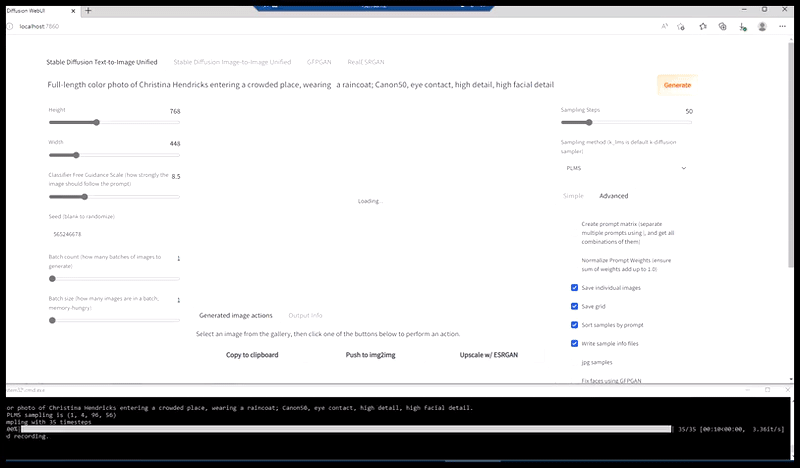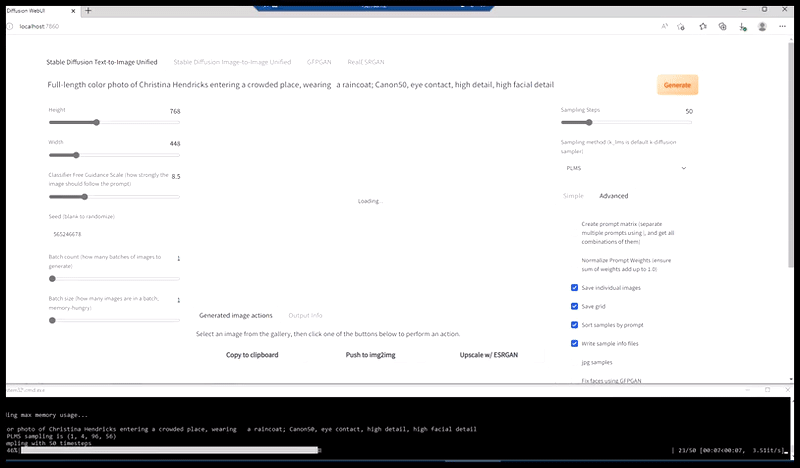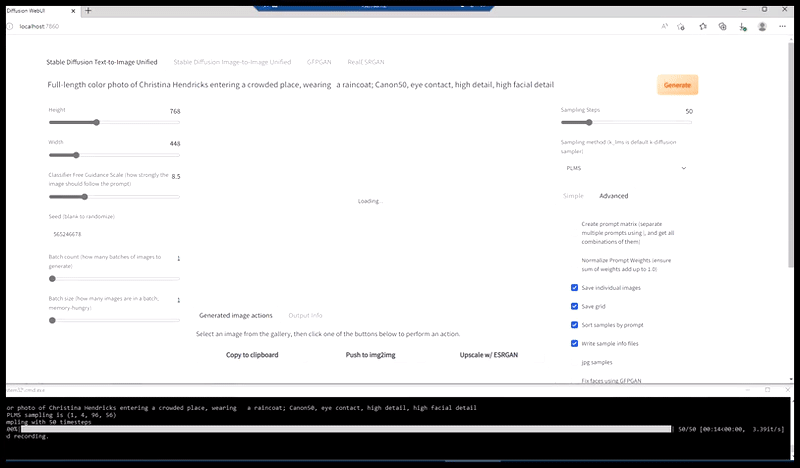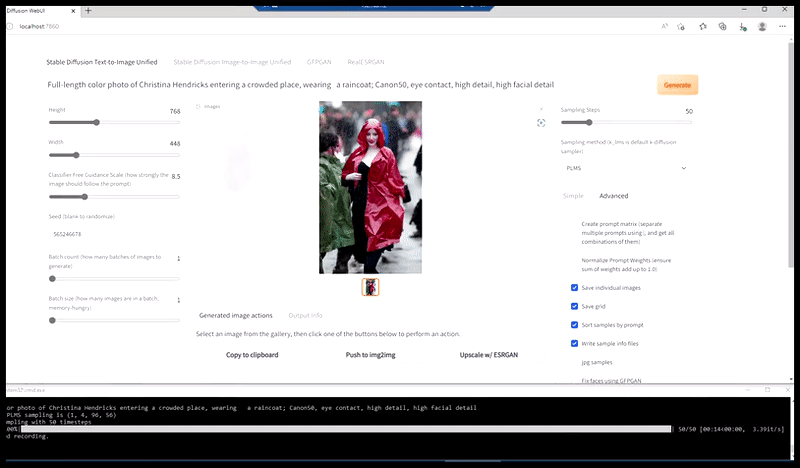
Génération d’une photo de presse plausible avec la invite ‘Photo couleur à plein corps de Christina Hendricks entrant dans un endroit bondé, portant un imperméable ; Canon50, contact visuel, détails élevés, détails faciaux élevés’.
Pour les célébrités ayant des carrières longues et durables, Stable Diffusion générera généralement une image de la personne à un âge récent (c’est-à-dire plus âgé), et il sera nécessaire d’ajouter des invites annexes telles que ‘jeune’ ou ‘dans l’année [YEAR]’ pour produire des images plus jeunes.

Avec une carrière importante et photographiée de manière cohérente s’étendant sur près de 40 ans, l’actrice Jennifer Connelly est l’une des rares célébrités dans LAION qui permettent à Stable Diffusion de représenter une gamme d’âges. Source : prépack Stable Diffusion, local, point de contrôle v1.4 ; invites liées à l’âge.
Ceci est principalement dû à la prolifération de la photographie de presse numérique (plutôt qu’à la photographie sur émulsion coûteuse) à partir du milieu des années 2000, et à la croissance ultérieure du volume de production d’images due à l’augmentation des vitesses de bande passante.
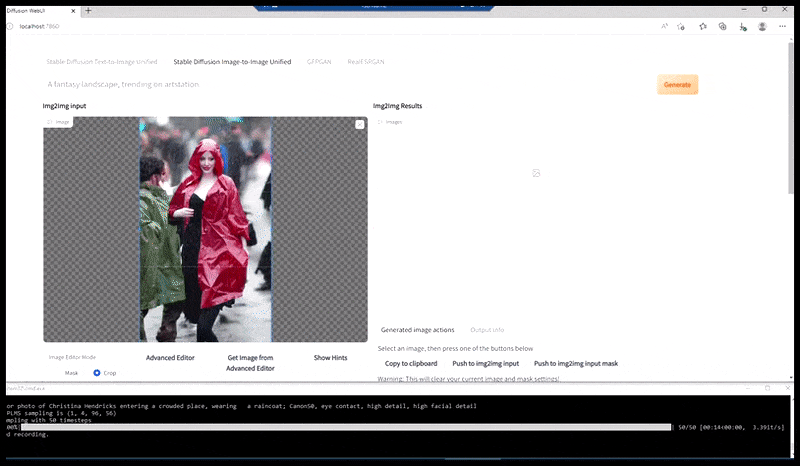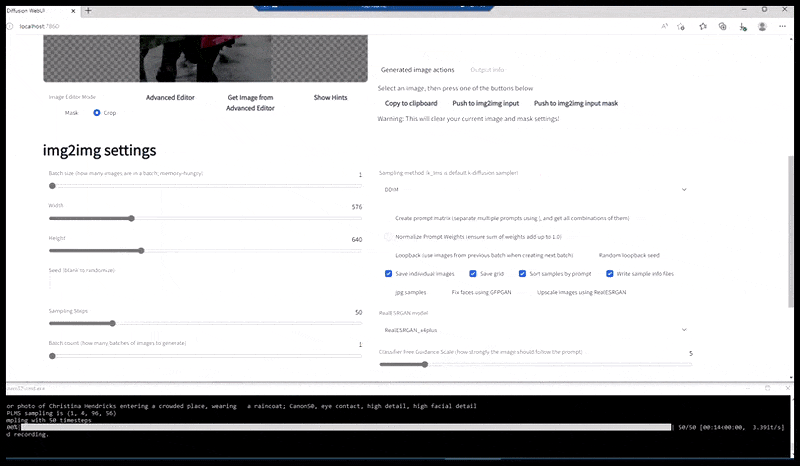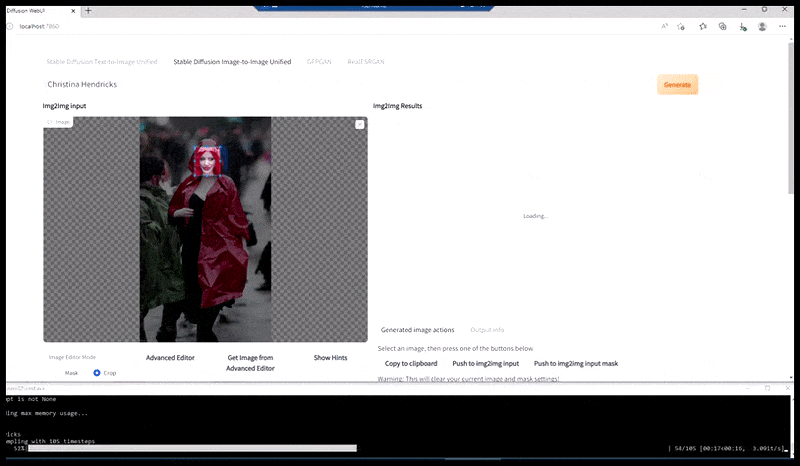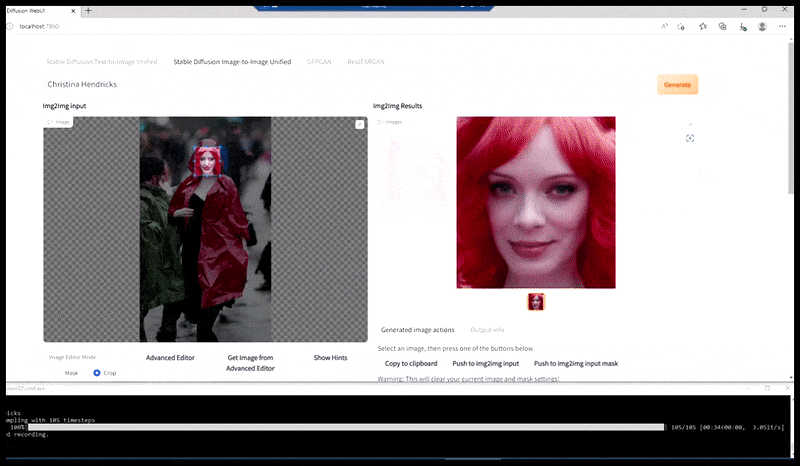
L’image rendue est passée à Img2Img dans Stable Diffusion, où une ‘zone de focus’ est sélectionnée, et un nouveau rendu de taille maximale n’est fait que pour cette zone, permettant à Stable Diffusion de concentrer toutes les ressources disponibles sur la recréation du visage.
Composition du visage ‘à haute attention’ dans le rendu d’origine. Outre les visages, ce processus ne fonctionnera qu’avec des entités qui ont une apparence cohérente et intégrale potentielle, telle qu’une partie de la photo d’origine qui a un objet distinct, tel qu’une montre ou une voiture. La mise à l’échelle d’une section d’un mur, par exemple, entraînera un mur réassemblé d’apparence très étrange, car les rendus de tuiles n’avaient pas de contexte plus large pour cette ‘pièce de puzzle’ lorsqu’ils les rendaient.
Certaines célébrités dans la base de données viennent ‘pré-glacées’ dans le temps, soit parce qu’elles sont mortes tôt (comme Marilyn Monroe), soit parce qu’elles ont connu une popularité mainstream éphémère, produisant un grand volume d’images pendant une période limitée. L’interrogation de Stable Diffusion fournit en quelque sorte un ‘indice de popularité actuel’ pour les stars modernes et anciennes. Pour certaines célébrités plus anciennes ou actuelles, il n’y a pas suffisamment d’images dans les données sources pour obtenir une ressemblance très bonne, tandis que la popularité durable de certaines stars disparues ou éclipsées garantit que leur ressemblance raisonnable peut être obtenue à partir du système.

Les rendus de Stable Diffusion révèlent rapidement quels visages célèbres sont bien représentés dans les données d’entraînement. Malgré sa popularité énorme en tant qu’adolescente plus âgée au moment de l’écriture, Millie Bobby Brown était plus jeune et moins connue lorsque les jeux de données sources LAION ont été extraits du Web, ce qui rend difficile l’obtention d’une ressemblance de haute qualité avec Stable Diffusion pour le moment.
Lorsque les données sont disponibles, les solutions d’up-res basées sur des tuiles dans Stable Diffusion pourraient aller plus loin que la concentration sur le visage : elles pourraient potentiellement permettre des visages encore plus précis et détaillés en décomposant les caractéristiques faciales et en dirigeant toutes les ressources locales de la GPU sur les caractéristiques individuelles avant de les réassembler – un processus qui est actuellement, encore une fois, manuel.

Ceci n’est pas limité aux visages, mais est limité aux parties d’objets qui sont au moins aussi prévisibles dans le contexte plus large de l’objet hôte, et qui se conforment à des embeddings de haut niveau que l’on pourrait raisonnablement s’attendre à trouver dans un jeu de données hyperscale.
La véritable limite est la quantité de données de référence disponibles dans le jeu de données, car, éventuellement, les détails fortement itérés deviendront complètement ‘hallucinés’ (c’est-à-dire fictifs) et moins authentiques.
De telles agrandissements granulaires de haut niveau fonctionnent dans le cas de Jennifer Connelly, car elle est bien représentée à travers une gamme d’âges dans LAION-aesthetics (le sous-ensemble principal de LAION 5B que Stable Diffusion utilise), et généralement à travers LAION ; dans de nombreux autres cas, la précision souffrirait d’un manque de données, nécessitant soit une fine-tuning (une formation supplémentaire, voir ‘Personnalisation’ ci-dessous), soit une inversion textuelle (voir ci-dessous).
Les tuiles sont un moyen puissant et relativement peu coûteux pour que Stable Diffusion puisse produire une sortie haute définition, mais la mise à l’échelle algorithmique de ce type, si elle manque d’un mécanisme d’attention plus large et de niveau supérieur, peut ne pas atteindre les normes espérées sur une gamme de types de contenu.
2 : Répondre aux problèmes avec les membres humains
Stable Diffusion ne correspond pas à son nom lorsqu’il s’agit de dépeindre la complexité des extrémités humaines. Les mains peuvent se multiplier aléatoirement, les doigts se confondent, un troisième membre apparaît sans prévenir, et les membres existants disparaissent sans trace. Pour sa défense, Stable Diffusion partage le problème avec ses compagnons de route, et la plupart certainement avec DALL-E 2.

Résultats non édités de DALL-E 2 et Stable Diffusion (1.4) à la fin août 2022, tous deux montrant des problèmes avec les membres. Invite est ‘Une femme embrassant un homme’
Les fans de Stable Diffusion qui espèrent que le point de contrôle 1.5 à venir (une version plus intensément formée du modèle, avec des paramètres améliorés) résoudra la confusion des membres sont susceptibles d’être déçus. Le nouveau modèle, qui sera publié dans environ deux semaines, est actuellement présenté sur le portail commercial stability.ai DreamStudio, qui utilise 1.5 par défaut, et où les utilisateurs peuvent comparer la nouvelle sortie avec les rendus de leurs systèmes locaux ou d’autres systèmes 1.4 :

Source : Prépack local 1.4 et https://beta.dreamstudio.ai/

Source : Prépack local 1.4 et https://beta.dreamstudio.ai/

Source : Prépack local 1.4 et https://beta.dreamstudio.ai/
Comme c’est souvent le cas, la qualité des données pourrait bien être la cause principale.
Les bases de données open source qui alimentent les systèmes de synthèse d’images tels que Stable Diffusion et DALL-E 2 sont capables de fournir de nombreuses étiquettes pour les humains individuels et l’action inter-humaine. Ces étiquettes sont formées en symbiose avec leurs images associées, ou des segments d’images.

Les utilisateurs de Stable Diffusion peuvent explorer les concepts formés dans le modèle en interrogeant le jeu de données LAION-aesthetics, un sous-ensemble du plus grand jeu de données LAION 5B, qui alimente le système. Les images sont classées non par leurs étiquettes alphabétiques, mais par leur ‘score esthétique’. Source : https://rom1504.github.io/clip-retrieval/
Une bonne hiérarchie d’étiquettes individuelles et de classes contribuant à la représentation d’un bras humain serait quelque chose comme corps>bras>main>doigts>[sous-doigts + pouce]> [segments de doigts]>Ongles.

Segmentation sémantique granulaire des parties d’une main. Même cette déconstruction inhabituellement détaillée laisse chaque ‘doigt’ comme une entité unique, sans tenir compte des trois sections d’un doigt et des deux sections d’un pouce. Source : https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Dans la réalité, les images sources sont peu susceptibles d’être étiquetées de manière cohérente dans l’ensemble du jeu de données, et les algorithmes d’étiquetage non supervisés s’arrêteront probablement au niveau supérieur de – par exemple – ‘main’, et laisseront les pixels intérieurs (qui contiennent techniquement des informations sur les doigts) comme une masse non étiquetée de pixels dont les caractéristiques seront dérivées de manière arbitraire, et qui peuvent se manifester plus tard dans les rendus comme un élément choquant.

Ce que cela devrait être (en haut à droite, si ce n’est en haut-coup), et ce que cela tend à être (en bas à droite), en raison de ressources limitées pour l’étiquetage, ou d’exploitation architecturale de ces étiquettes si elles existent dans le jeu de données.
Ainsi, si un modèle de diffusion latente parvient à rendre un bras, il est presque certain qu’il essayera de rendre une main à l’extrémité de ce bras, car bras>main est la hiérarchie minimale requise, assez haut dans ce que l’architecture sait sur ‘l’anatomie humaine’.
Après cela, les ‘doigts’ peuvent être le plus petit regroupement, même s’il y a 14 sous-parties de doigts/pouces supplémentaires à considérer lors de la représentation des mains humaines.
Si cette théorie tient, il n’y a pas de véritable remède, en raison du manque de budget sectoriel pour l’étiquetage manuel, et du manque d’algorithmes suffisamment efficaces qui pourraient automatiser l’étiquetage tout en produisant des taux d’erreur faibles. En effet, le modèle peut actuellement s’appuyer sur la cohérence anatomique humaine pour masquer les lacunes du jeu de données sur lequel il a été formé.
Une raison possible pour laquelle il ne peut pas s’appuyer sur cela, récemment proposée sur le Discord de Stable Diffusion, est que le modèle pourrait être confus quant au nombre correct de doigts qu’une main humaine (réaliste) devrait avoir, car la base de données LAION qui le fait fonctionner comporte des personnages de dessins animés qui peuvent avoir moins de doigts (ce qui est en soi une raccourci pour économiser du travail).

Deux des coupables potentiels du ‘syndrome du doigt manquant’ dans Stable Diffusion et des modèles similaires. En bas, des exemples de mains de dessin animé à partir du jeu de données LAION-aesthetics qui alimente Stable Diffusion. Source : https://www.youtube.com/watch?v=0QZFQ3gbd6I
Si cela est vrai, alors la seule solution évidente est de reformer le modèle, en excluant le contenu non réaliste basé sur des humains, en s’assurant que les cas réels d’omission (c’est-à-dire les amputés) sont étiquetés comme des exceptions. D’un point de vue de curation de données, cela serait toutefois un défi considérable, en particulier pour les efforts de la communauté à ressources limitées.
La deuxième approche serait d’appliquer des filtres qui excluent un tel contenu (c’est-à-dire ‘main avec trois/cinq doigts’) de se manifester au moment du rendu, de la même manière que OpenAI a, dans une certaine mesure, filtré GPT-3 et DALL-E 2, afin que leur sortie puisse être réglementée sans avoir besoin de reformer les modèles sources.

Pour Stable Diffusion, la distinction sémantique entre les doigts et même les membres peut devenir horriblement floue, évoquant le filon ‘body horror’ des films d’horreur des années 80 de la part de réalisateurs comme David Cronenberg. Source : https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Cependant, à nouveau, cela nécessiterait des étiquettes qui peuvent ne pas exister sur toutes les images affectées, nous laissant avec le même défi logistique et budgétaire.
Il pourrait être argumenté qu’il y a deux routes à suivre : jeter plus de données dans le problème, et appliquer des systèmes interprétatifs tiers qui peuvent intervenir lorsque des erreurs physiques de ce type sont présentées à l’utilisateur final (à tout le moins, le dernier donnerait à OpenAI un moyen de fournir des remboursements pour les ‘rendus d’horreur corporelle’, si l’entreprise était motivée pour le faire).
3 : Personnalisation
L’une des possibilités les plus passionnantes pour l’avenir de Stable Diffusion est la perspective pour les utilisateurs ou les organisations de développer des systèmes révisés ; des modifications qui permettent un contenu en dehors de la sphère LAION préformée d’être intégré dans le système – idéalement sans les dépenses incontrôlables de la formation du modèle entier à nouveau, ou le risque encouru lors de la formation d’un grand volume de nouvelles images à un modèle mature et capable.













{kind=link}
{kind=link}
{kind=link}