Intelligence Artificielle
Restructuration des visages dans les vidéos avec l'apprentissage automatique

Une collaboration de recherche entre la Chine et le Royaume-Uni a mis au point une nouvelle méthode pour remodeler les visages en vidéo. La technique permet un élargissement et un rétrécissement convaincants de la structure faciale, avec une grande cohérence et une absence d'artefacts.
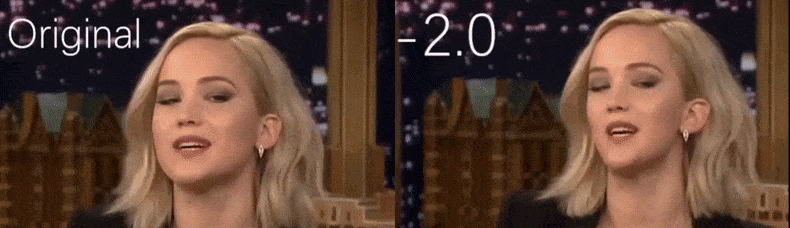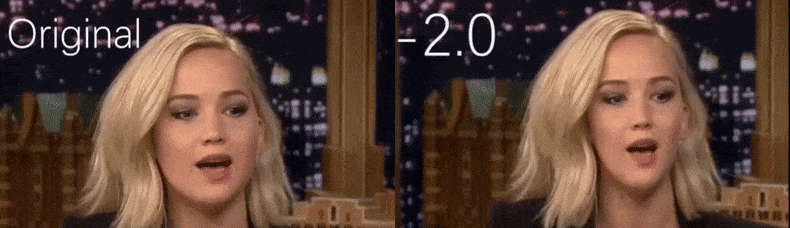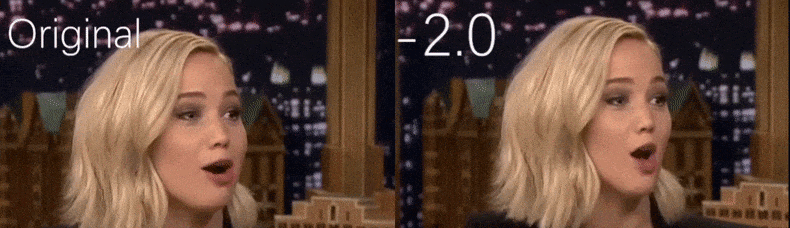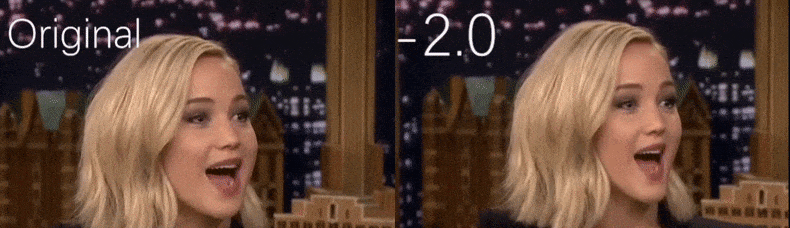
À partir d'une vidéo YouTube utilisée comme source par les chercheurs, l'actrice Jennifer Lawrence apparaît comme une personnalité plus maigre (à droite). Voir la vidéo d'accompagnement intégrée au bas de l'article pour de nombreux autres exemples avec une meilleure résolution. Source : https://www.youtube.com/watch?v=tA2BxvrKvjE
Ce type de transformation n'est généralement possible que par le biais de méthodes CGI traditionnelles qui nécessiteraient de recréer entièrement le visage via des procédures détaillées et coûteuses de capsulage de mouvement, de gréement et de texturation.
Au lieu de cela, les images de synthèse présentes dans la technique sont intégrées dans un pipeline neuronal sous forme d'informations faciales 3D paramétriques qui sont ensuite utilisées comme base pour un flux de travail d'apprentissage automatique.

Les visages paramétriques traditionnels sont de plus en plus utilisés comme lignes directrices pour les processus de transformation qui utilisent l'IA au lieu de CGI. Source : https://arxiv.org/pdf/2205.02538.pdf
Les auteurs déclarent:
Notre objectif est de générer des résultats de remodelage vidéo de portraits de haute qualité en modifiant la forme générale des visages selon leur déformation naturelle. Cela peut être utilisé pour des applications telles que la création de visages galbés pour la béatification et l'exagération faciale pour des effets visuels.
Bien que la déformation et la distorsion 2D du visage soient disponibles pour les consommateurs depuis l'avènement de Photoshop (et aient conduit à des images étranges et souvent inacceptables sous-cultures autour de la distorsion du visage et de la dysmorphie corporelle), c'est un truc difficile à réaliser en vidéo sans utiliser CGI.

Les dimensions du visage de Mark Zuckerberg se sont élargies et rétrécies grâce à la nouvelle technique sino-britannique.
Le remodelage corporel est actuellement un domaine de Intérêt intense dans le secteur de la vision par ordinateur, principalement en raison de son potentiel dans le commerce électronique de mode, même si faire paraître quelqu'un plus grand ou présentant une diversité squelettique est actuellement un problème. défi notable.
De même, changer la forme d'une tête dans des séquences vidéo de manière cohérente et convaincante a fait l'objet de travail prioritaire Les chercheurs de la nouvelle étude ont toutefois constaté des artefacts et d'autres limitations dans cette implémentation. Cette nouvelle offre étend les capacités de cette recherche antérieure, de la sortie statique à la sortie vidéo.
Le nouveau système a été formé sur un PC de bureau avec un AMD Ryzen 9 3950X avec 32 Go de mémoire et utilise un algorithme de flux optique de OpenCV pour les motion maps, lissées par le StructureFlux cadre; le réseau d'alignement facial (FAN) composant pour l'estimation des points de repère, qui est également utilisé dans les packages deepfakes populaires ; et le Solveur Cérès pour résoudre les problèmes d'optimisation.

Un exemple extrême d'élargissement du visage avec le nouveau système.
Construction papier est intitulé Remodelage paramétrique des portraits dans les vidéos, et vient de trois chercheurs de l'Université du Zhejiang et un de l'Université de Bath.
A propos du visage
Dans le cadre du nouveau système, la vidéo est extraite dans une séquence d'images, et une pose rigide est d'abord estimée pour chaque visage. Ensuite, un nombre représentatif d'images suivantes est estimé conjointement pour construire des paramètres d'identité cohérents tout au long de la série d'images (c'est-à-dire les images de la vidéo).

Flux architectural du système de déformation du visage.
Ensuite, l'expression est évaluée, ce qui produit un paramètre de remodelage implémenté par régression linéaire. Ensuite, une nouvelle fonction de distance signée (SDF) construit une cartographie 2D dense des linéaments du visage avant et après le remodelage.
Enfin, une optimisation de déformation sensible au contenu est effectuée sur la vidéo de sortie.
Faces paramétriques
Le processus utilise un modèle de visage 3D morphable (3DMM), un modèle de plus en plus utilisé. complément populairet aux systèmes de synthèse de visage neuronaux et basés sur GAN, en plus d'être en vigueur pour les systèmes de détection de deepfake.

Pas du nouveau document, mais un exemple de modèle de visage morphable 3D (3DMM) - un prototype de visage paramétrique utilisé dans le nouveau projet. En haut à gauche, application repère sur un visage 3DMM. En haut à droite, les sommets du maillage 3D d'une isocarte. En bas à gauche, montre le raccord de point de repère ; en bas au milieu, une isocarte de la texture du visage extraite ; et en bas à droite, un raccord et une forme résultants. Source : http://www.ee.surrey.ac.uk/CVSSP/Publications/papers/Huber-VISAPP-2016.pdf
Le flux de travail du nouveau système doit prendre en compte les cas d'occlusion, comme un cas où le sujet détourne le regard. C'est l'un des plus grands défis des logiciels deepfake, car les points de repère FAN ont peu de capacité à rendre compte de ces cas et ont tendance à s'éroder en qualité lorsque le visage évite ou est occlus.
Le nouveau système est capable d'éviter ce piège en définissant un énergie de contour qui est capable de faire correspondre la limite entre la face 3D (3DMM) et la face 2D (telle que définie par les repères FAN).
Optimisation
Un déploiement utile pour un tel système consisterait à implémenter une déformation en temps réel, par exemple dans les filtres de chat vidéo. Le cadre actuel ne le permet pas, et les ressources informatiques nécessaires feraient de la déformation « en direct » un défi majeur.
Selon l'article, et en supposant une cible vidéo de 24 ips, les opérations par image dans le pipeline représentent une latence de 16.344 secondes pour chaque seconde de métrage, avec des coups uniques supplémentaires pour l'estimation de l'identité et la déformation du visage 3D (321 ms et 160 ms, respectivement) .
Par conséquent, l'optimisation est essentielle pour progresser vers la réduction de la latence. Étant donné qu'une optimisation conjointe sur toutes les images ajouterait une surcharge importante au processus et qu'une optimisation de type init (en supposant l'identité ultérieure cohérente du locuteur à partir de la première image) pourrait conduire à des anomalies, les auteurs ont adopté un schéma clairsemé pour calculer les coefficients de trames échantillonnées à des intervalles pratiques.
Une optimisation conjointe est ensuite effectuée sur ce sous-ensemble de trames, conduisant à un processus de reconstruction plus léger.
Visage
La technique de déformation utilisée dans le projet est une adaptation du travail des auteurs de 2020 Portraits profonds et galbés (DSP).

Deep Shapely Portraits, une soumission 2020 à ACM Multimedia. L'article est dirigé par des chercheurs du ZJU-Tencent Game and Intelligent Graphics Innovation Technology Joint Lab. Source : http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
Les auteurs observent « Nous étendons cette méthode du remodelage d'une image monoculaire au remodelage de la séquence d'images entière. »
Tests
Le document observe qu'il n'y avait pas de matériel antérieur comparable par rapport auquel évaluer la nouvelle méthode. Par conséquent, les auteurs ont comparé les images de leur sortie vidéo déformée avec la sortie DSP statique.

Test du nouveau système par rapport aux images statiques de Deep Shapely Portraits.
Les auteurs notent que les artefacts résultent de la méthode DSP, en raison de son utilisation d'un mappage clairsemé - un problème que le nouveau cadre résout avec un mappage dense. De plus, la vidéo produite par DSP, selon le journal, démontre manque de fluidité et de cohérence visuelle.
Les auteurs déclarent:
« Les résultats montrent que notre approche peut produire de manière robuste des vidéos de portraits remodelées cohérentes tandis que la méthode basée sur l'image peut facilement conduire à des artefacts de scintillement notables. »
Regardez la vidéo d'accompagnement ci-dessous, pour plus d'exemples :

Première publication le 9 mai 2022. Modifié à 6h EET, remplacement de « champ » par « fonction » pour SDF.












