Angle d’Anderson
Vérification faciale ‘créative’ avec des réseaux antagonistes génératifs

Un nouvel article de l’Université de Stanford a proposé une méthode naissante pour tromper les systèmes d’authentification faciale sur des plateformes telles que les applications de rencontres, en utilisant un Réseau antagoniste génératif (GAN) pour créer des images de visage alternatives qui contiennent les mêmes informations d’identification essentielles qu’un visage réel.
La méthode a réussi à contourner les processus de vérification faciale sur les applications de rencontres Tinder et Bumble, dans un cas, en faisant même passer un visage de genre inversé (masculin) pour authentique par rapport à l’identité source (féminine).

Différentes identités générées qui présentent le codage spécifique de l’auteur de l’article (figuré dans la première image ci-dessus). Source: https://arxiv.org/pdf/2203.15068.pdf
Selon l’auteur, le travail représente la première tentative pour contourner la vérification faciale à l’aide d’images générées qui ont été imprégnées de traits d’identité spécifiques, mais qui tentent de représenter une identité alternative ou substantiellement modifiée.
La technique a été testée sur un système de vérification faciale local personnalisé, et a ensuite bien performé dans des tests en boîte noire contre deux applications de rencontres qui effectuent une vérification faciale sur les images téléchargées par les utilisateurs.
Le nouvel article est intitulé Contournement de la vérification faciale, et provient de Sanjana Sarda, une chercheuse au Département de génie électrique de l’Université de Stanford.
Contrôle de l’espace facial
Bien que « injecter » des fonctionnalités spécifiques à l’identité (c’est-à-dire à partir de visages, panneaux de signalisation routière, etc.) dans des images créées soit une spécialité des attaques adverses, la nouvelle étude suggère quelque chose de différent : que la capacité croissante du secteur de la recherche à contrôler l’espace latent des GAN va finalement permettre le développement d’architectures qui peuvent créer des identités alternatives cohérentes à celles d’un utilisateur – et, en effet, permettre l’extraction de fonctionnalités d’identité à partir d’images disponibles sur le web d’un utilisateur non averti pour les intégrer dans une identité « fantôme » créée.
La cohérence et la navigabilité ont été les principaux défis concernant l’espace latent du GAN depuis l’avènement des réseaux antagonistes génératifs. Un GAN qui a avec succès assimilé une collection d’images d’entraînement dans son espace latent ne fournit pas de carte facile pour « pousser » des fonctionnalités d’une classe à une autre.
Alors que des techniques et des outils tels que la carte d’activation de classe pondérée par gradient (Grad-CAM) peuvent aider à établir des directions latentes entre les classes établies, et permettre des transformations (voir l’image ci-dessous), le défi supplémentaire de entanglement fait généralement pour un « voyage approximatif », avec un contrôle fin limité de la transition.
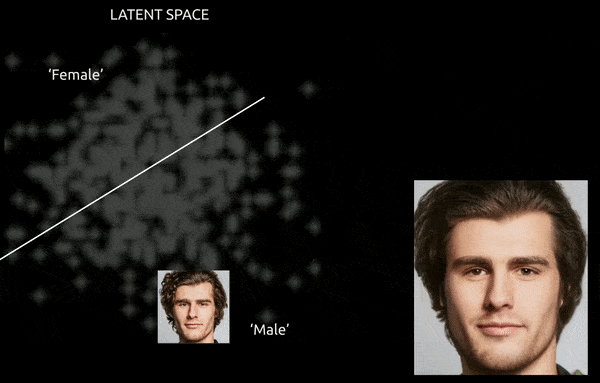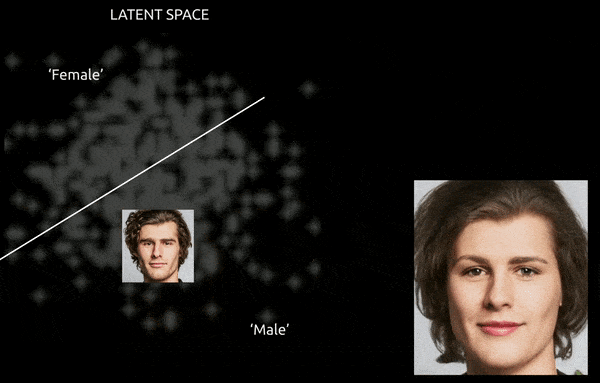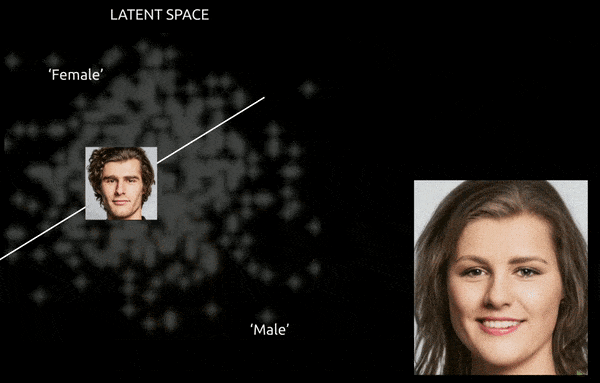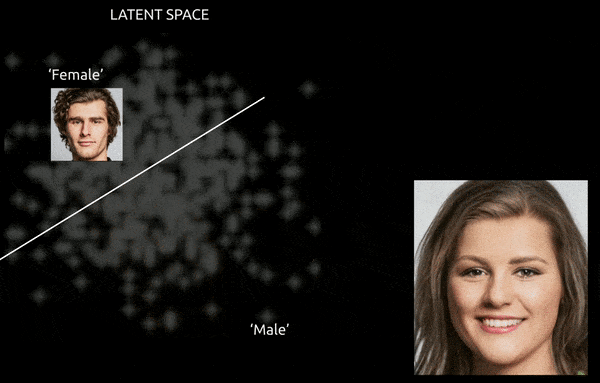
Un voyage approximatif entre des vecteurs codés dans l’espace latent d’un GAN, en poussant une identité masculine dérivée des données dans les « codages féminins » de l’autre côté d’un des nombreux hyperplans linéaires dans l’espace latent complexe et ésotérique. Image dérivée de matériel à https://www.youtube.com/watch?v=dCKbRCUyop8
La capacité de « geler » et de protéger des fonctionnalités spécifiques à l’identité tout en les déplaçant dans des codages transformés ailleurs dans l’espace latent rend potentiellement possible la création d’un individu cohérent (et même animable) dont l’identité est lue par les systèmes de machine comme quelqu’un d’autre.
Méthode
L’auteur a utilisé deux jeux de données comme base pour les expériences : un jeu de données d’utilisateurs humains composé de 310 images de son visage s’étalant sur une période de quatre ans, avec des éclairages, des âges et des angles de vue variables), avec des visages découpés via Caffe ; et le jeu de données FairFace équilibré sur le plan racial, composé de 108 501 images, également découpées et découpées.
Le modèle de vérification faciale local a été dérivé d’une implémentation de base de FaceNet et DeepFace, pré-entraîné sur ConvNet Inception, avec chaque image représentée par un vecteur de 128 dimensions.
L’approche utilise des images de visage d’un sous-ensemble formé à partir de FairFace. Pour passer la vérification faciale, la distance calculée causée par la norme de Frobenius d’une image est compensée par l’utilisateur cible dans la base de données. Toute image en dessous du seuil de 0,7 équivaut à la même identité, sinon la vérification est considérée comme ayant échoué.
Un modèle StyleGAN a été affiné sur le jeu de données personnel de l’auteur, produisant un modèle qui générerait des variations reconnaissables de son identité, bien que aucune de ces images générées ne soit identique aux données d’entraînement. Cela a été réalisé en figeant les quatre premières couches du discriminateur, pour éviter la suradaptation des données et produire une sortie variée.
Bien que des images diverses aient été obtenues avec le modèle StyleGAN de base, la faible résolution et la fidélité ont conduit à une deuxième tentative avec StarGAN V2, qui permet l’entraînement d’images de graines vers un visage cible.
Le modèle StarGAN V2 a été pré-entraîné pendant environ 10 heures en utilisant l’ensemble de validation de FairFace, avec une taille de lot de quatre et une taille de validation de huit. Dans l’approche la plus réussie, le jeu de données personnel de l’auteur a été utilisé comme source avec les données d’entraînement comme référence.
Expériences de vérification
Un modèle de vérification faciale a été construit sur la base d’un sous-ensemble de 1000 images, dans le but de vérifier une image arbitraire du jeu. Les images qui ont réussi la vérification ont ensuite été testées contre l’identité de l’auteur.

À gauche, l’auteur de l’article, une photo réelle ; au milieu, une image arbitraire qui a échoué à la vérification ; à droite, une image non liée du jeu de données qui a passé la vérification en tant qu’auteur.
L’objectif des expériences était de créer un écart aussi large que possible entre l’identité visuelle perçue tout en conservant les traits définissants de l’identité cible. Cela a été évalué à l’aide de la distance de Mahalanobis, une mesure utilisée dans le traitement d’images pour la recherche de modèles et de gabarits.
Pour le modèle génératif de base, les résultats à basse résolution obtenus affichent une diversité limitée, malgré la réussite de la vérification faciale locale. StarGAN V2 s’est avéré plus capable de créer des images diverses qui ont pu s’authentifier.

Toutes les images représentées ont passé la vérification faciale locale. Au-dessus, les générations de base à basse résolution de StyleGAN, ci-dessous, les générations de StarGAN V2 à haute résolution et de meilleure qualité.
Les trois dernières images illustrées ci-dessus ont utilisé le jeu de données personnel de l’auteur à la fois comme source et comme référence, tandis que les images précédentes ont utilisé les données d’entraînement comme référence et le jeu de données de l’auteur comme source.
Les images générées ont été testées contre les systèmes de vérification faciale des applications de rencontres Bumble et Tinder, avec l’identité de l’auteur comme référence, et ont passé la vérification. Une « version masculine » de l’identité de l’auteur a également passé le processus de vérification de Bumble, bien que l’éclairage ait dû être ajusté dans l’image générée avant d’être accepté. Tinder n’a pas accepté la version masculine.

Versions « masculines » de l’identité (féminine) de l’auteur.
Conclusion
Ces expériences sont seminales en termes de projection d’identité, dans le contexte de la manipulation de l’espace latent des GAN, qui reste un défi extraordinaire dans la synthèse d’images et la recherche sur les deepfakes. Néanmoins, le travail ouvre la voie au concept d’intégration de fonctionnalités spécifiques et cohérentes à travers des identités diverses, et de création d’identités « alternatives » qui « lisent » comme quelqu’un d’autre.
Publié pour la première fois le 30 mars 2022.












