
Intelligence artificielle
Conseils d'auto-attention : améliorer la qualité des échantillons des modèles de diffusion

Les modèles de diffusion de débruitage sont des cadres d'IA génératifs qui synthétisent des images à partir du bruit via un processus de débruitage itératif. Ils sont célébrés pour leurs capacités et leur diversité exceptionnelles de génération d’images, largement attribuées aux méthodes de guidage conditionnel au texte ou à la classe, notamment le guidage par classificateur et le guidage sans classificateur. Ces modèles ont notamment réussi à créer des images diversifiées et de haute qualité. Des études récentes ont montré que les techniques de guidage telles que les légendes et les étiquettes de classe jouent un rôle crucial dans l'amélioration de la qualité des images générées par ces modèles.
Cependant, les modèles de diffusion et les méthodes de guidage sont confrontés à des limites dans certaines conditions externes. La méthode Classifier-Free Guidance (CFG), qui utilise la suppression d'étiquettes, ajoute de la complexité au processus de formation, tandis que la méthode Classifier Guidance (CG) nécessite une formation supplémentaire du classificateur. Les deux méthodes sont quelque peu contraintes par leur dépendance à des conditions externes durement acquises, ce qui limite leur potentiel et les confine à des paramètres conditionnels.
Pour remédier à ces limitations, les développeurs ont formulé une approche plus générale du guidage par diffusion, connue sous le nom de guidage par l'autoattention (SAG). Cette méthode exploite les informations provenant d’échantillons intermédiaires de modèles de diffusion pour générer des images. Nous explorerons SAG dans cet article, en discutant de son fonctionnement, de sa méthodologie et de ses résultats par rapport aux frameworks et pipelines de pointe actuels.
Guidage d'auto-attention : améliorer la qualité des échantillons des modèles de diffusion
Les modèles de diffusion de débruitage (DDM) ont gagné en popularité grâce à leur capacité à créer des images à partir du bruit via un processus de débruitage itératif. Les prouesses de ces modèles en matière de synthèse d’images sont largement dues aux méthodes de guidage par diffusion utilisées. Malgré leurs atouts, les modèles de diffusion et les méthodes basées sur le guidage sont confrontés à des défis tels qu'une complexité accrue et des coûts de calcul accrus.
Pour surmonter les limitations actuelles, les développeurs ont introduit la méthode Self-Attention Guidance, une formulation plus générale du guidage de diffusion qui ne repose pas sur les informations externes du guidage de diffusion, facilitant ainsi une approche flexible et sans condition pour guider cadres de diffusion. L'approche choisie par Self-Attention Guidance contribue en fin de compte à améliorer l'applicabilité des méthodes traditionnelles de guidage par diffusion à des cas avec ou sans exigences externes.
L’auto-attention guidée repose sur le principe simple d’une formulation généralisée et sur l’hypothèse selon laquelle les informations internes contenues dans des échantillons intermédiaires peuvent également servir de guide. Sur la base de ce principe, la méthode SAG introduit d’abord Blur Guidance, une solution simple et directe pour améliorer la qualité des échantillons. Le guidage du flou vise à exploiter les propriétés bénignes du flou gaussien pour supprimer naturellement les détails à petite échelle en guidant les échantillons intermédiaires en utilisant les informations éliminées grâce au flou gaussien. Bien que la méthode de guidage Blur améliore la qualité de l’échantillon avec une échelle de guidage modérée, elle ne parvient pas à reproduire les résultats sur une grande échelle de guidage car elle introduit souvent une ambiguïté structurelle dans des régions entières. En conséquence, la méthode de guidage Blur a du mal à aligner l’entrée d’origine avec la prédiction de l’entrée dégradée. Pour améliorer la stabilité et l'efficacité de la méthode de guidage Blur à une plus grande échelle de guidage, le Self-Attention Guidance tente d'exploiter le mécanisme d'auto-attention des modèles de diffusion, car les modèles de diffusion modernes contiennent déjà un mécanisme d'auto-attention dans leur architecture.
Partant de l’hypothèse que l’auto-attention est essentielle pour capturer les informations saillantes, la méthode Self-Attention Guidance utilise des cartes d’auto-attention des modèles de diffusion pour brouiller de manière contradictoire les régions contenant des informations saillantes et, ce faisant, guider l’attention personnelle. modèles de diffusion avec les informations résiduelles requises. La méthode exploite ensuite les cartes d’attention lors du processus inverse des modèles de diffusion, pour améliorer la qualité des images et utilise l’autoconditionnement pour réduire les artefacts sans nécessiter de formation supplémentaire ou d’informations externes.

Pour résumer, la méthode Self-Attention Guidance
- Il s'agit d'une nouvelle approche qui utilise des cartes d'auto-attention internes des cadres de diffusion pour améliorer la qualité de l'image de l'échantillon généré sans nécessiter de formation supplémentaire ni dépendre de conditions externes.
- La méthode SAG tente de généraliser les méthodes de guidage conditionnel en une méthode sans condition qui peut être intégrée à n'importe quel modèle de diffusion sans nécessiter de ressources supplémentaires ou de conditions externes, améliorant ainsi l'applicabilité des cadres basés sur le guidage.
- La méthode SAG tente également de démontrer ses capacités orthogonales aux méthodes et cadres conditionnels existants, facilitant ainsi une augmentation des performances en facilitant une intégration flexible avec d'autres méthodes et modèles.
En progressant, la méthode de guidage de l'auto-attention apprend des résultats de cadres connexes, notamment les modèles de diffusion de débruitage, le guidage d'échantillonnage, les méthodes d'auto-attention générative de l'IA et les représentations internes des modèles de diffusion. Cependant, à la base, la méthode de guidage d'auto-attention met en œuvre les apprentissages des modèles probabilistes de diffusion DDPM ou de débruitage, de guidage de classificateur, de guidage sans classificateur et d'auto-attention dans les cadres de diffusion. Nous en parlerons en profondeur dans la section suivante.
Guide d'auto-attention : préliminaires, méthodologie et architecture
Modèle probabiliste de diffusion de débruitage ou DDPM
DDPM ou Modèle probabiliste de diffusion de débruitage est un modèle qui utilise un processus de débruitage itératif pour récupérer une image à partir du bruit blanc. Traditionnellement, un modèle DDPM reçoit une image d'entrée et un programme de variance à un pas de temps pour obtenir l'image à l'aide d'un processus direct appelé processus markovien.
Guide sur les classificateurs et sans classificateur avec la mise en œuvre du GAN
Le GAN ou Generative Adversarial Networks possède une diversité commerciale unique pour la fidélité, et pour apporter cette capacité des frameworks GAN aux modèles de diffusion, le framework Self-Attention Guidance propose d'utiliser une méthode de guidage de classificateur qui utilise un classificateur supplémentaire. A l’inverse, une méthode de guidage sans classificateur peut également être mise en œuvre sans utiliser de classificateur supplémentaire pour obtenir les mêmes résultats. Bien que la méthode fournisse les résultats souhaités, elle n'est toujours pas viable sur le plan informatique car elle nécessite des étiquettes supplémentaires et limite également le cadre à des modèles de diffusion conditionnelle qui nécessitent des conditions supplémentaires comme un texte ou une classe ainsi que des détails de formation supplémentaires qui ajoutent à la complexité de l'apprentissage. le modèle.
Généralisation des conseils de diffusion
Bien que les méthodes Classifier et Classifier-free Guidance fournissent les résultats souhaités et facilitent la génération conditionnelle dans les modèles de diffusion, elles dépendent d'entrées supplémentaires. Pour tout pas de temps donné, l'entrée d'un modèle de diffusion comprend une condition généralisée et un échantillon perturbé sans la condition généralisée. De plus, la condition généralisée englobe des informations internes à l'échantillon perturbé ou une condition externe, voire les deux. Les conseils qui en résultent sont formulés à l’aide d’un régresseur imaginaire en supposant qu’il peut prédire la condition généralisée.
Améliorer la qualité de l'image à l'aide des cartes d'auto-attention
Le guide de diffusion généralisée implique qu'il est possible de guider le processus inverse des modèles de diffusion en extrayant des informations saillantes dans la condition généralisée contenue dans l'échantillon perturbé. S'appuyant sur la même chose, la méthode Self-Attention Guidance capture efficacement les informations importantes pour les processus inverses tout en limitant les risques résultant de problèmes de non-distribution dans les modèles de diffusion pré-entraînés.
Guide de flou
Le guidage du flou dans le guidage de l'attention personnelle est basé sur le flou gaussien, une méthode de filtrage linéaire dans laquelle le signal d'entrée est convolué avec un filtre gaussien pour générer une sortie. Avec une augmentation de l'écart type, le flou gaussien réduit les détails à échelle fine dans les signaux d'entrée et aboutit à des signaux d'entrée localement indiscernables en les lissant vers la constante. De plus, des expériences ont indiqué un déséquilibre d'informations entre le signal d'entrée et le signal de sortie de flou gaussien, le signal de sortie contenant des informations à plus petite échelle.
Sur la base de cet apprentissage, le cadre Self-Attention Guidance introduit le guidage par flou, une technique qui exclut intentionnellement les informations des reconstructions intermédiaires pendant le processus de diffusion, et utilise à la place ces informations pour guider ses prédictions vers une augmentation de la pertinence des images pour le public. saisir des informations. Le guidage par flou amène essentiellement la prédiction d'origine à s'écarter davantage de la prédiction d'entrée floue. De plus, la propriété bénigne du flou gaussien empêche les signaux de sortie de s'écarter de manière significative du signal d'origine avec un écart modéré. En termes simples, le flou se produit naturellement dans les images, ce qui fait du flou gaussien une méthode plus appropriée à appliquer aux modèles de diffusion pré-entraînés.
Dans le pipeline Self-Attention Guidance, le signal d’entrée est d’abord flou à l’aide d’un filtre gaussien, puis diffusé avec un bruit supplémentaire pour produire le signal de sortie. Ce faisant, le pipeline SAG atténue l'effet secondaire du flou résultant qui réduit le bruit gaussien et fait en sorte que le guidage s'appuie sur le contenu plutôt que sur un bruit aléatoire. Bien que le guidage par flou donne des résultats satisfaisants sur les frameworks avec une échelle de guidage modérée, il ne parvient pas à reproduire les résultats sur les modèles existants avec une grande échelle de guidage car il a tendance à produire des résultats bruyants, comme le démontre l'image suivante.

Ces résultats pourraient être le résultat de l'ambiguïté structurelle introduite dans le cadre par le flou global qui rend difficile pour le pipeline SAG d'aligner les prédictions de l'entrée d'origine avec l'entrée dégradée, ce qui entraîne des sorties bruyantes.
Mécanisme d'auto-attention
Comme mentionné précédemment, les modèles de diffusion comportent généralement un composant d’auto-attention intégré, et c’est l’un des composants les plus essentiels du cadre d’un modèle de diffusion. Le mécanisme d'auto-attention est implémenté au cœur des modèles de diffusion et permet au modèle de prêter attention aux parties saillantes de l'entrée pendant le processus de génération, comme le démontre l'image suivante avec des masques haute fréquence dans la rangée supérieure, et des masques d'auto-attention dans la rangée inférieure des images finalement générées.

La méthode proposée de guidage de l’auto-attention s’appuie sur le même principe et exploite les capacités des cartes d’auto-attention dans les modèles de diffusion. Dans l'ensemble, la méthode Self-Attention Guidance brouille les patchs auto-assistés dans le signal d'entrée ou, en termes simples, masque les informations sur les patchs pris en charge par les modèles de diffusion. De plus, les signaux de sortie dans Self-Attention Guidance contiennent des régions intactes des signaux d'entrée, ce qui signifie qu'il n'en résulte pas d'ambiguïté structurelle des entrées et résout le problème du flou global. Le pipeline obtient ensuite les cartes d'auto-attention agrégées en effectuant un GAP ou Global Average Pooling pour agréger les cartes d'auto-attention à la dimension et en suréchantillonnant le voisin le plus proche pour correspondre à la résolution du signal d'entrée.
Guidage d'auto-attention : expériences et résultats
Pour évaluer ses performances, le pipeline Self-Attention Guidance est échantillonné à l'aide de 8 GPU Nvidia GeForce RTX 3090 et repose sur IDDPM, ADM et Cadres de diffusion stable.
Génération inconditionnelle avec guidage de l'attention personnelle
Pour mesurer l'efficacité du pipeline SAG sur des modèles inconditionnels et démontrer la propriété sans condition que ne possèdent pas l'approche Classifier Guidance et Classifier Free Guidance, le pipeline SAG est exécuté sur des cadres pré-entraînés inconditionnellement sur 50 XNUMX échantillons.

Comme on peut l'observer, la mise en œuvre du pipeline SAG améliore les métriques FID, sFID et IS d'entrée inconditionnelle tout en réduisant la valeur de rappel en même temps. De plus, les améliorations qualitatives résultant de la mise en œuvre du pipeline SAG sont évidentes dans les images suivantes où les images du haut sont les résultats des frameworks ADM et Stable Diffusion tandis que les images du bas sont les résultats des frameworks ADM et Stable Diffusion avec le Pipeline SAG.


Génération conditionnelle avec SAG
L'intégration du pipeline SAG dans les cadres existants donne des résultats exceptionnels en matière de génération inconditionnelle, et le pipeline SAG est capable d'une agnosticité des conditions qui permet au pipeline SAG d'être également implémenté pour la génération conditionnelle.
Diffusion stable avec guidage d'auto-attention
Même si le cadre Stable Diffusion d'origine génère des images de haute qualité, l'intégration du cadre Stable Diffusion avec le pipeline Self-Attention Guidance peut améliorer considérablement les résultats. Pour évaluer son effet, les développeurs utilisent des invites vides pour une diffusion stable avec une graine aléatoire pour chaque paire d'images, et utilisent une évaluation humaine sur 500 paires d'images avec et sans guidage d'auto-attention. Les résultats sont démontrés dans l’image suivante.

De plus, la mise en œuvre de SAG peut améliorer les capacités du cadre de diffusion stable, car la fusion du guidage sans classificateur avec le guidage par auto-attention peut élargir la gamme de modèles de diffusion stable à la synthèse texte-image. De plus, les images générées à partir du modèle de diffusion stable avec guidage d'auto-attention sont de meilleure qualité avec moins d'artefacts grâce à l'effet d'auto-conditionnement du pipeline SAG, comme le démontre l'image suivante.

Limites actuelles
Bien que la mise en œuvre du pipeline Self-Attention Guidance puisse améliorer considérablement la qualité des images générées, elle présente certaines limites.
L’une des limitations majeures est l’orthogonalité avec le guidage par classificateur et le guidage sans classificateur. Comme on peut l'observer dans l'image suivante, la mise en œuvre de SAG améliore le score FID et le score de prédiction, ce qui signifie que le pipeline SAG contient un composant orthogonal qui peut être utilisé simultanément avec les méthodes de guidage traditionnelles.

Cependant, cela nécessite toujours que les modèles de diffusion soient formés d'une manière spécifique, ce qui ajoute à la complexité ainsi qu'aux coûts de calcul.
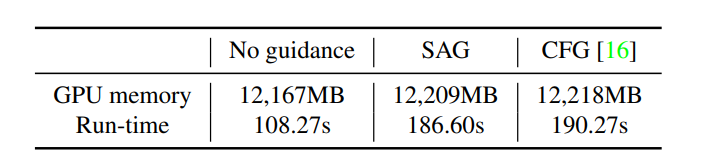
De plus, la mise en œuvre du guidage d'auto-attention n'augmente pas la consommation de mémoire ou de temps, ce qui indique que la surcharge résultant des opérations telles que le masquage et le flou dans SAG est négligeable. Cependant, cela ajoute encore aux coûts de calcul car il inclut une étape supplémentaire par rapport aux approches sans guidage.
Réflexions finales
Dans cet article, nous avons parlé de Self-Attention Guidance, une formulation nouvelle et générale de méthode de guidage qui utilise les informations internes disponibles dans les modèles de diffusion pour générer des images de haute qualité. L’auto-attention guidée repose sur le principe simple d’une formulation généralisée et sur l’hypothèse selon laquelle les informations internes contenues dans des échantillons intermédiaires peuvent également servir de guide. Le pipeline Self-Attention Guidance est une approche sans condition et sans formation qui peut être mise en œuvre dans divers modèles de diffusion et utilise l'autoconditionnement pour réduire les artefacts dans les images générées et améliorer la qualité globale.





 |