Intelligence Artificielle
Guide complet sur Gemma 2 : le nouveau modèle de langage ouvert de Google

Gem 2 S'appuyant sur son prédécesseur, Gemma 2 offre des performances et une efficacité accrues, ainsi qu'une suite de fonctionnalités innovantes qui le rendent particulièrement attractif pour la recherche et les applications pratiques. Ce qui distingue Gemma XNUMX, c'est sa capacité à offrir des performances comparables à celles de modèles propriétaires beaucoup plus imposants, mais dans un format conçu pour une plus grande accessibilité et une utilisation sur des configurations matérielles plus modestes.
En approfondissant les spécifications techniques et l'architecture de Gemma 2, je me suis retrouvé de plus en plus impressionné par l'ingéniosité de sa conception. Le modèle intègre plusieurs techniques avancées, notamment de nouveaux mécanismes d'attention et des approches innovantes de la stabilité de l'entraînement, qui contribuent à ses capacités remarquables.

LLM Google Open Source Gemma
Dans ce guide complet, nous explorerons en profondeur Gemma 2, en examinant son architecture, ses fonctionnalités clés et ses applications pratiques. Que vous soyez un praticien chevronné de l'IA ou un novice enthousiaste, cet article vise à vous fournir des informations précieuses sur le fonctionnement de Gemma 2 et sur la manière dont vous pouvez exploiter sa puissance dans vos propres projets.
Qu’est-ce que Gemma 2 ?
Gemma 2 est le tout nouveau modèle de langage open source de Google, conçu pour être léger et puissant. Il s'appuie sur les mêmes recherches et technologies que celles utilisées pour créer les modèles Gemini de Google, offrant des performances de pointe dans un format plus accessible. Gemma 2 est disponible en deux tailles :
Gemma 2 9B: Un modèle à 9 milliards de paramètres
Gemma 2 27B: Un modèle plus grand de 27 milliards de paramètres
Chaque taille est disponible en deux variantes :
Modèles de base: Pré-entraîné sur un vaste corpus de données textuelles
Modèles optimisés pour les instructions (IT): Affiné pour de meilleures performances sur des tâches spécifiques
Accédez aux modèles dans Google AI Studio: Google AI Studio-Gemma 2
Lisez l'article ici: Rapport technique Gemma 2
Principales fonctionnalités et améliorations
Gemma 2 introduit plusieurs avancées significatives par rapport à son prédécesseur :
1. Augmentation des données de formation
Les modèles ont été formés sur beaucoup plus de données :
Gemma 2 27B: Formé sur 13 XNUMX milliards de jetons
Gemma 2 9B: Formé sur 8 XNUMX milliards de jetons
Cet ensemble de données étendu, composé principalement de données Web (principalement en anglais), de code et de mathématiques, contribue à l'amélioration des performances et de la polyvalence des modèles.
2. Attention à la fenêtre coulissante
Gemma 2 met en œuvre une nouvelle approche des mécanismes d'attention :
Toutes les autres couches utilisent une attention de fenêtre glissante avec un contexte local de 4096 jetons
Les couches alternées emploient une attention globale quadratique complète sur l'ensemble du contexte du jeton 8192.
Cette approche hybride vise à équilibrer l’efficacité avec la capacité de capturer les dépendances à long terme dans l’entrée.
3. Coiffage souple
Pour améliorer la stabilité et les performances de l'entraînement, Gemma 2 introduit un mécanisme de soft-capping :
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Applied to attention logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Applied to final layer logits
final_logits = soft_cap(final_logits, cap=30.0)
Cette technique empêche les logits de croître excessivement sans troncature dure, conservant ainsi plus d'informations tout en stabilisant le processus de formation.
- Gemma 2 9B: Un modèle à 9 milliards de paramètres
- Gemma 2 27B: Un modèle plus grand de 27 milliards de paramètres
Chaque taille est disponible en deux variantes :
- Modèles de base : pré-entraînés sur un vaste corpus de données textuelles
- Modèles optimisés par les instructions (IT) : optimisés pour de meilleures performances sur des tâches spécifiques
4. Distillation des connaissances
Pour le modèle 9B, Gemma 2 utilise des techniques de distillation des connaissances :
- Pré-formation : le modèle 9B apprend d'un modèle d'enseignant plus large lors de la formation initiale
- Post-formation : les modèles 9B et 27B utilisent la distillation conforme aux politiques pour affiner leurs performances.
Ce processus aide le modèle plus petit à capturer plus efficacement les capacités des modèles plus grands.
5. Fusion de modèles
Gemma 2 utilise une nouvelle technique de fusion de modèles appelée Warp, qui combine plusieurs modèles en trois étapes :
- Moyenne mobile exponentielle (EMA) lors du réglage fin de l'apprentissage par renforcement
- Interpolation linéaire sphérique (SLERP) après avoir affiné plusieurs politiques
- Interpolation linéaire vers l'initialisation (LITI) comme étape finale
Cette approche vise à créer un modèle final plus robuste et plus performant.
Benchmarks de Performance
Gemma 2 démontre des performances impressionnantes dans divers benchmarks :
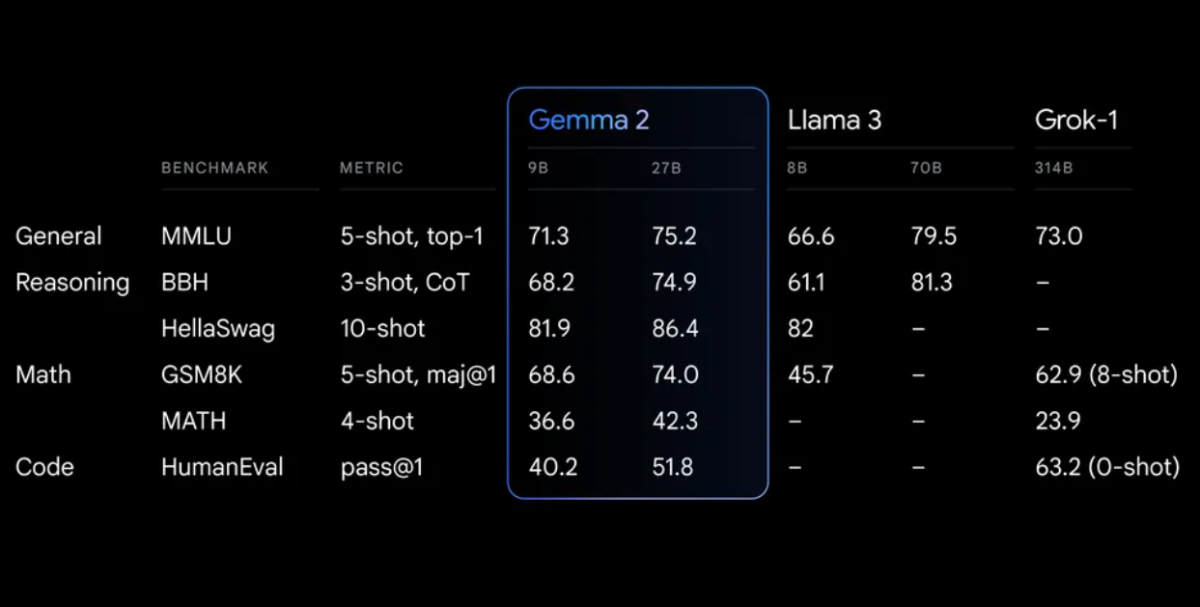
Gemma 2 sur une architecture repensée, conçue pour à la fois des performances exceptionnelles et une efficacité d'inférence
Premiers pas avec Gemma 2
Pour commencer à utiliser Gemma 2 dans vos projets, vous avez plusieurs options :
1. Google IA Studio
Pour une expérimentation rapide sans configuration matérielle requise, vous pouvez accéder à Gemma 2 via Google IA Studio.
2. Transformateurs de visage étreignant
Gemma 2 est intégré au populaire Étreindre le visage Bibliothèque Transformers. Voici comment l'utiliser :
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the model and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Prepare input prompt = "Explain the concept of quantum entanglement in simple terms." inputs = tokenizer(prompt, return_tensors="pt") # Generate text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Pour les utilisateurs de TensorFlow, Gemma 2 est disponible via Keras :
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Load the model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate text
prompt = "Explain the concept of quantum entanglement in simple terms."
output = model.generate(prompt, max_length=200)
print(output)
Utilisation avancée : créer un système RAG local avec Gemma 2
Une application puissante de Gemma 2 est la création d'un système de génération augmentée par récupération (RAG). Créons un système RAG simple et entièrement local utilisant Gemma 2 et les plongements Nomic.
Étape 1 : Configuration de l'environnement
Tout d’abord, assurez-vous que les bibliothèques nécessaires sont installées :
pip install langchain ollama nomic chromadb
Étape 2 : indexer les documents
Créez un indexeur pour traiter vos documents :
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Usage
indexer = Indexer("path/to/your/documents")
vector_store = indexer.index()
Étape 3 : Configuration du système RAG
Maintenant, créons le système RAG en utilisant Gemma 2 :
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Usage
rag_system = RAGSystem(vector_store)
response = rag_system.query("What is the capital of France?")
print(response["result"])
Ce système RAG utilise Gemma 2 via Ollama pour le modèle de langage et les intégrations Nomic pour la récupération de documents. Il vous permet de poser des questions basées sur les documents indexés, en fournissant des réponses contextuelles à partir des sources pertinentes.
Affiner Gemma 2
Pour des tâches ou des domaines spécifiques, vous souhaiterez peut-être affiner Gemma 2. Voici un exemple simple utilisant la bibliothèque Hugging Face Transformers :
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load model and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prepare dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
N'oubliez pas d'ajuster les paramètres de formation en fonction de vos besoins spécifiques et de vos ressources informatiques.
Considérations éthiques et limites
Bien que Gemma 2 offre des capacités impressionnantes, il est essentiel d'être conscient de ses limites et de ses considérations éthiques :
- Préjugé: Comme tous les modèles de langage, Gemma 2 peut refléter des biais présents dans ses données de formation. Évaluez toujours ses résultats de manière critique.
- Précision factuelle: Bien que très performant, Gemma 2 peut parfois générer des informations incorrectes ou incohérentes. Vérifiez les faits importants auprès de sources fiables.
- Longueur du contexte: Gemma 2 a une longueur de contexte de 8192 jetons. Pour les documents ou conversations plus longs, vous devrez peut-être mettre en œuvre des stratégies pour gérer efficacement le contexte.
- Ressources informatiques: En particulier pour le modèle 27B, des ressources informatiques importantes peuvent être nécessaires pour une inférence et un réglage efficaces.
- Utilisation responsable:Adhérez aux pratiques d'IA responsable de Google et assurez-vous que votre utilisation de Gemma 2 est conforme aux principes éthiques de l'IA.
Conclusion
Les fonctionnalités avancées de Gemma 2 telles que l'attention par fenêtre coulissante, le soft-capping et les nouvelles techniques de fusion de modèles en font un outil puissant pour un large éventail de tâches de traitement du langage naturel.
En tirant parti de Gemma 2 dans vos projets, que ce soit via une simple inférence, des systèmes RAG complexes ou des modèles affinés pour des domaines spécifiques, vous pouvez exploiter la puissance de SOTA AI tout en gardant le contrôle de vos données et processus.












