Intelligence artificielle
L’IA aide les orateurs nerveux à ‘lire la salle’ lors de vidéoconférences

En 2013, un sondage sur les phobies courantes a déterminé que la perspective de parler en public était pire que la perspective de la mort pour la majorité des répondants. Le syndrome est connu sous le nom de glossophobie.
La migration vers les réunions en ligne sur des plateformes telles que Zoom et Google Spaces, due au COVID, n’a pas amélioré la situation. Lorsqu’une réunion compte un grand nombre de participants, nos capacités naturelles d’évaluation des menaces sont altérées par les rangées et les icônes de participants à basse résolution, ainsi que par la difficulté de lire les signaux visuels subtils des expressions faciales et du langage corporel. Skype, par exemple, s’est révélé être une mauvaise plateforme pour transmettre des indices non verbaux.
Les effets sur la performance de la parole publique de l’intérêt et de la réactivité perçus sont bien documentés et intuitivement évidents pour la plupart d’entre nous. Une réponse opaque de l’audience peut causer aux orateurs des hésitations et les amener à recourir à des discours de remplissage, sans savoir si leurs arguments rencontrent un accord, un mépris ou un désintérêt, ce qui peut rendre l’expérience inconfortable à la fois pour l’orateur et pour ses auditeurs.
Sous la pression du changement inattendu vers la vidéoconférence en ligne inspiré par les restrictions et les précautions liées au COVID, le problème est en train de s’aggraver, et un certain nombre de systèmes de rétroaction d’audience ont été suggérés dans les communautés de recherche en vision par ordinateur et en affect ces dernières années.
Solutions axées sur le matériel
La plupart de ces systèmes, cependant, nécessitent un équipement supplémentaire ou un logiciel complexe qui peut soulever des problèmes de confidentialité ou de logistique – des approches coûteuses ou contraintes en ressources qui précèdent la pandémie. En 2001, le MIT a proposé le Galvactivator, un dispositif porté à la main qui infère l’état émotionnel du participant à l’audience, testé lors d’un symposium d’une journée.

En 2001, le Galvactivator du MIT, qui mesurait la réponse de conductivité cutanée pour tenter de comprendre le sentiment et l’engagement de l’audience. Source : https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
Une grande partie de l’énergie académique a également été consacrée au déploiement possible de « clickers » en tant que système de réponse d’audience (ARS), une mesure pour augmenter la participation active des auditoires (ce qui augmente automatiquement l’engagement, puisque cela force le spectateur à jouer le rôle d’un nœud de rétroaction actif), mais qui a également été envisagé comme un moyen d’encouragement des orateurs.
D’autres tentatives pour « connecter » l’orateur et l’audience ont inclus la surveillance de la fréquence cardiaque, l’utilisation d’équipements complexes portés par le corps pour exploiter l’électroencéphalographie, des « compteurs d’applaudissements », la reconnaissance d’émotions basée sur la vision par ordinateur pour les travailleurs de bureau, et l’utilisation d’émoticônes envoyés par l’audience pendant l’oraison de l’orateur.

En 2017, l’EngageMeter, un projet de recherche académique conjoint de l’Université de Munich et de l’Université de Stuttgart. Source : http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Dans le cadre de la recherche sur l’analyse d’audience, le secteur privé a pris un intérêt particulier pour l’estimation et le suivi du regard – des systèmes où chaque membre de l’audience (qui peut à son tour devoir parler), est soumis à un suivi oculaire en tant qu’indice d’engagement et d’approbation.
Toutes ces méthodes sont relativement complexes. Beaucoup d’entre elles nécessitent un équipement spécialisé, des environnements de laboratoire, des logiciels sur mesure et des abonnements à des API commerciales coûteuses – ou une combinaison de ces facteurs restrictifs.
Par conséquent, le développement de systèmes minimalistes basés sur peu plus que des outils courants pour la vidéoconférence est devenu intéressant au cours des 18 derniers mois.
Rapport de l’approbation de l’audience de manière discrète
À cette fin, une nouvelle collaboration de recherche entre l’Université de Tokyo et l’Université Carnegie Mellon propose un système novateur qui peut être greffé sur des outils de vidéoconférence standard (tels que Zoom) en utilisant uniquement un site Web équipé d’une webcam sur lequel un logiciel d’estimation de regard et de pose léger est en cours d’exécution. De cette façon, même le besoin de plugins de navigateur local est évité.
Les nods et l’attention estimée de l’utilisateur sont traduits en données représentatives qui sont visualisées pour l’orateur, permettant un « test de ph » en temps réel de la mesure dans laquelle le contenu engage l’audience – et également au moins un vague indicateur des périodes de discours où l’orateur peut perdre l’intérêt de l’audience.
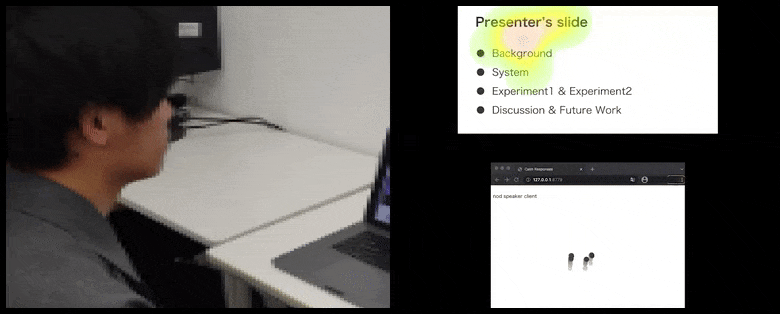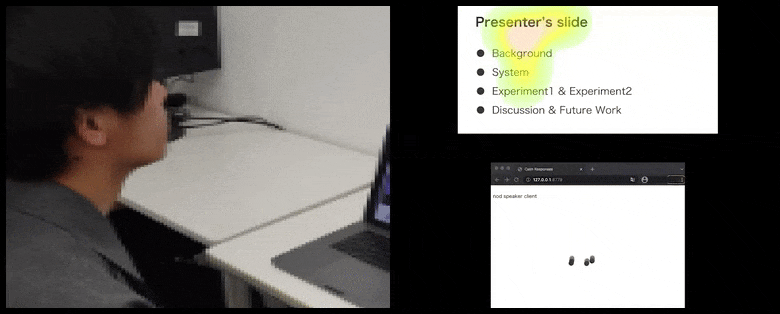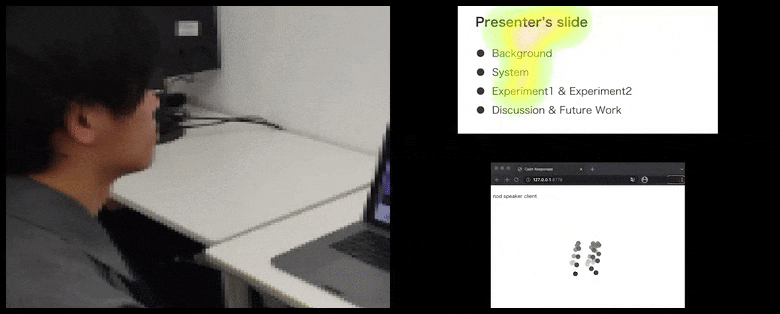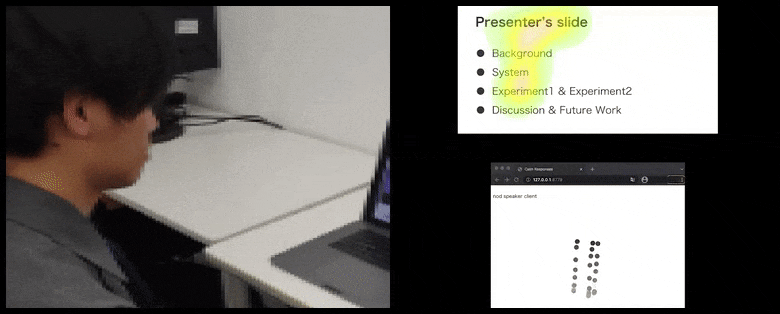
Avec CalmResponses, l’attention et les nods de l’utilisateur sont ajoutés à un pool de rétroaction d’audience et traduits en une représentation visuelle qui peut bénéficier à l’orateur. Voir la vidéo intégrée à la fin de l’article pour plus de détails et d’exemples. Source : https://www.youtube.com/watch?v=J_PhB4FCzk0
Dans de nombreuses situations académiques, telles que les cours en ligne, les étudiants peuvent être complètement invisibles pour l’orateur, puisqu’ils n’ont pas activé leurs caméras en raison de leur conscience de leur environnement ou de leur apparence actuelle. CalmResponses peut résoudre cet obstacle épineux de rétroaction de l’orateur en signalant ce qu’il sait sur la façon dont l’orateur regarde le contenu, et s’il hoche la tête, sans qu’il soit nécessaire pour le spectateur d’activer sa caméra.
Le document s’intitule CalmResponses : Affichage des réactions collectives de l’audience dans la communication à distance, et est un travail conjoint entre deux chercheurs de l’UoT et un de Carnegie Mellon.
Les auteurs offrent une démo en direct sur le Web et ont publié le code source sur GitHub.
Le cadre CalmResponses
L’intérêt de CalmResponses pour les nods, par opposition à d’autres dispositions possibles de la tête, est basé sur la recherche (dont certaines remontent à l’époque de Darwin) qui indique que plus de 80 % de tous les mouvements de tête des auditeurs sont composés de nods (même lorsqu’ils expriment un désaccord). Dans le même temps, les mouvements des yeux ont été montrés sur de nombreuses études pour être un indice fiable d’intérêt ou d’engagement.
CalmResponses est mis en œuvre avec HTML, CSS et JavaScript, et comprend trois sous-systèmes : un client d’audience, un client d’orateur et un serveur. Le client d’audience transmet les données de regard et de mouvement de tête de l’utilisateur via WebSockets sur la plateforme d’application cloud Heroku.

La visualisation des nods de l’audience est affichée à droite dans un mouvement animé sous CalmResponses. Dans ce cas, la visualisation du mouvement est disponible non seulement pour l’orateur, mais également pour toute l’audience. Source : https://arxiv.org/pdf/2204.02308.pdf
Pour la section de suivi des yeux du projet, les chercheurs ont utilisé WebGazer, un cadre de suivi des yeux léger et basé sur JavaScript qui peut fonctionner avec une faible latence directement à partir d’un site Web (voir le lien ci-dessus pour la mise en œuvre Web des chercheurs).
Puisque le besoin d’une mise en œuvre simple et d’une reconnaissance de réponse globale l’emporte sur le besoin de précision élevée dans l’estimation de la pose et du regard, les données de pose d’entrée sont lissées selon les valeurs moyennes avant d’être prises en compte pour l’estimation de la réponse globale.
L’action de nod est évaluée via la bibliothèque JavaScript clmtrackr, qui ajuste des modèles faciaux aux visages détectés dans les images ou les vidéos via un décalage de repère régularisé. Aux fins d’économie et de faible latence, seul le repère détecté pour le nez est activement surveillé dans la mise en œuvre des auteurs, puisque cela suffit pour suivre les actions de nod.
Le mouvement de la pointe du nez de l’utilisateur crée un sillage qui contribue au pool de rétroaction d’audience liée aux nods, visualisé de manière agrégée pour tous les participants.
Carte de chaleur
Alors que l’activité de nod est représentée par des points mobiles dynamiques (voir les images ci-dessus et la vidéo à la fin), l’attention visuelle est signalée en termes de carte de chaleur qui montre à l’orateur et à l’audience où se trouve le locus général d’attention sur l’écran de présentation partagé ou l’environnement de vidéoconférence.

Tous les participants peuvent voir où se trouve l’attention générale de l’utilisateur. L’article ne mentionne pas si cette fonctionnalité est disponible lorsque l’utilisateur peut voir une « galerie » d’autres participants, ce qui pourrait révéler une focalisation spécieuse sur un participant particulier, pour diverses raisons.
Tests
Deux environnements de test ont été formulés pour CalmResponses sous la forme d’une étude d’ablation tacite, en utilisant trois ensembles de circonstances variés : dans la « Condition B » (de base), les auteurs ont reproduit une conférence en ligne typique pour les étudiants, où la majorité des étudiants gardent leurs caméras éteintes, et l’orateur n’a pas la possibilité de voir les visages de l’audience ; dans la « Condition CR-E », l’orateur pouvait voir la rétroaction du regard (cartes de chaleur) ; dans la « Condition CR-N », l’orateur pouvait voir à la fois l’activité de nod et le regard de l’audience.
Le premier scénario expérimental comprenait la condition B et la condition CR-E ; le deuxième comprenait la condition B et la condition CR-N. La rétroaction a été obtenue à la fois de l’orateur et de l’audience.
Dans chaque expérience, trois facteurs ont été évalués : l’évaluation objective et subjective de la présentation (y compris un questionnaire d’auto-évaluation de l’orateur concernant ses sentiments sur la façon dont la présentation s’est déroulée) ; le nombre d’événements de « discours de remplissage », indicatif d’insécurité et de prévarication momentanées ; et des commentaires qualitatifs. Ces critères sont communs estimateurs de la qualité de la parole et de l’anxiété de l’orateur.
Le bassin de test était composé de 38 personnes âgées de 19 à 44 ans, comprenant 29 hommes et neuf femmes avec un âge moyen de 24,7 ans, tous japonais ou chinois, et tous fluent en japonais. Ils ont été divisés de manière aléatoire en cinq groupes de 6-7 participants, et aucun des sujets ne se connaissait personnellement.
Les tests ont été menés sur Zoom, avec cinq orateurs donnant des présentations dans la première expérience et six dans la deuxième.

Les conditions de remplissage sont marquées de boîtes orange. En général, le contenu de remplissage a diminué dans une proportion raisonnable à la rétroaction accrue de l’audience du système.
Les chercheurs notent qu’un orateur a vu ses remplisseurs diminuer de manière notable, et que dans la « Condition CR-N », l’orateur a rarement prononcé des phrases de remplissage. Voir l’article pour les résultats très détaillés et granulaires signalés ; cependant, les résultats les plus marqués étaient dans l’évaluation subjective de l’orateur et des participants à l’audience.
Des commentaires de l’audience comprenaient :
‘Je me sentais impliqué dans les présentations” [AN2], “Je n’étais pas sûr que les discours des orateurs étaient améliorés, mais je sentais un sentiment d’unité à partir de la visualisation des mouvements de tête des autres.’ [AN6]
‘Je n’étais pas sûr que les discours des orateurs étaient améliorés, mais je sentais un sentiment d’unité à partir de la visualisation des mouvements de tête des autres.’
Les chercheurs notent que le système introduit un nouveau type de pause artificielle dans la présentation de l’orateur, puisque l’orateur est enclin à se référer au système visuel pour évaluer la rétroaction de l’audience avant de poursuivre.
Ils notent également une sorte d’« effet du manteau blanc », difficile à éviter dans les circonstances expérimentales, où certains participants se sont sentis contraints par les implications de sécurité possibles de la surveillance des données biométriques.
Conclusion
Un avantage notable dans un système comme celui-ci est que toutes les technologies non standard nécessaires pour une telle approche disparaissent complètement après leur utilisation. Il n’y a pas de plugins de navigateur résiduels à désinstaller, ou pour jeter des doutes dans l’esprit des participants quant à savoir s’ils devraient rester sur leurs systèmes respectifs ; et il n’y a pas besoin de guider les utilisateurs à travers le processus d’installation (bien que le cadre basé sur le Web nécessite une minute ou deux de calibration initiale de l’utilisateur), ou de naviguer dans la possibilité pour les utilisateurs de ne pas avoir les autorisations nécessaires pour installer des logiciels locaux, y compris les extensions et les extensions basées sur le navigateur.
Bien que les mouvements faciaux et oculaires évalués ne soient pas aussi précis qu’ils pourraient l’être dans des circonstances où des cadres d’apprentissage automatique locaux dédiés (tels que la série YOLO) pourraient être utilisés, cette approche presque sans friction de l’évaluation de l’audience fournit une précision suffisante pour une analyse large du sentiment et de la position dans des scénarios de vidéoconférence typiques. Par-dessus tout, c’est très bon marché.
Voir la vidéo du projet associé ci-dessous pour plus de détails et d’exemples.
Publié pour la première fois le 11 avril 2022.












