Angle d’Anderson
Une Méthode de Données Forensiques pour une Nouvelle Génération de Deepfakes

Bien que la création de deepfakes de particuliers soit devenue une préoccupation publique croissante et soit de plus en plus interdite dans diverses régions, prouver effectivement qu’un modèle créé par un utilisateur – tel qu’un modèle permettant la revenge porn – a été spécifiquement formé sur les images d’une personne en particulier reste extrêmement difficile.
Pour mettre le problème en contexte : un élément clé d’une attaque de deepfake est de faussement prétendre qu’une image ou une vidéo représente une personne spécifique. Simplement déclarer que quelqu’un dans une vidéo est l’identité #A, plutôt que juste un sosie, est suffisant pour causer un préjudice, et aucun AI n’est nécessaire dans ce scénario.
Cependant, si un attaquant génère des images ou des vidéos AI à l’aide de modèles formés sur des données de personnes réelles, les systèmes de reconnaissance faciale des médias sociaux et des moteurs de recherche relieront automatiquement le contenu factice à la victime – sans nécessiter de noms dans les publications ou les métadonnées. Les visuels AI générés seuls assurent l’association.
Plus l’apparence de la personne est distincte, plus cela devient inévitable, jusqu’à ce que le contenu factice apparaisse dans les recherches d’images et atteigne finalement la victime.
Face à Face
Le moyen le plus courant de diffuser des modèles axés sur l’identité est actuellement le Low-Rank Adaptation (LoRA), dans lequel l’utilisateur forme un petit nombre d’images pendant quelques heures contre les poids d’un modèle de base beaucoup plus grand, tel que Stable Diffusion (pour les images statiques, principalement) ou Hunyuan Video, pour les deepfakes vidéo.
Les cibles les plus courantes des LoRAs, y compris la nouvelle génération de LoRAs basées sur la vidéo, sont les célébrités féminines, dont la célébrité les expose à ce type de traitement avec moins de critiques publiques que dans le cas de victimes « inconnues », en raison de l’hypothèse que de tels travaux dérivés sont couverts par la « fair use » (au moins aux États-Unis et en Europe).

Les célébrités féminines dominent les listes LoRA et Dreambooth sur le portail civit.ai. Le LoRA le plus populaire compte actuellement plus de 66 000 téléchargements, ce qui est considérable, étant donné que cette utilisation de l’IA est encore considérée comme une activité « de niche ».
Il n’y a pas de forum public pour les victimes non célébrités de deepfaking, qui ne surgissent dans les médias que lorsque des affaires de poursuites judiciaires surviennent, ou que les victimes s’expriment dans des médias populaires.
Cependant, dans les deux scénarios, les modèles utilisés pour falsifier les identités cibles ont « distillé » leurs données de formation si complètement dans l’espace latent du modèle qu’il est difficile d’identifier les images sources qui ont été utilisées.
Si cela était possible de le faire dans une marge d’erreur acceptable, cela permettrait de poursuivre ceux qui partagent des LoRAs, puisqu’il prouve non seulement l’intention de deepfaker une identité particulière (c’est-à-dire celle d’une personne « inconnue » spécifique, même si le malfaiteur ne la nomme pas pendant le processus de diffamation), mais expose également le téléchargeur à des accusations de violation de droits d’auteur, lorsque cela s’applique.
Le dernier serait utile dans les juridictions où la réglementation juridique des technologies de deepfaking est manquante ou en retard.
Sur-Exposé
L’objectif de la formation d’un modèle de base, tel que le modèle de base multi-gigaoctet que l’utilisateur pourrait télécharger à partir de Hugging Face, est que le modèle devienne bien généralisé, et ductile. Cela implique une formation sur un nombre adéquat d’images diverses, et avec des paramètres appropriés, et la fin de la formation avant que le modèle « sur-apprenne » les données.
Un modèle sur-apprenu a vu les données tellement de fois (excessivement) pendant le processus de formation qu’il tendra à reproduire des images très similaires, exposant ainsi la source des données de formation.

L’identité « Ann Graham Lotz » peut être presque parfaitement reproduite dans le modèle Stable Diffusion V1.5. La reconstruction est presque identique aux données de formation (à gauche dans l’image ci-dessus). Source : https://arxiv.org/pdf/2301.13188
Cependant, les modèles sur-apprenus sont généralement écartés par leurs créateurs plutôt que distribués, puisqu’ils sont en tout cas inaptes à leur fin. Par conséquent, cela est une « aubaine » forensique peu probable. Dans tous les cas, le principe s’applique plus à la formation coûteuse et à grande échelle des modèles de base, où plusieurs versions de la même image qui ont infiltré un énorme jeu de données source peuvent rendre certaines images de formation faciles à invoquer (voir image et exemple ci-dessus).
Les choses sont un peu différentes dans le cas des modèles LoRA et Dreambooth (bien que Dreambooth soit tombé en désuétude en raison de ses grandes tailles de fichiers). Ici, l’utilisateur sélectionne un très petit nombre d’images diverses d’un sujet, et les utilise pour former un LoRA.

À gauche, sortie d’un LoRA Hunyuan Video. À droite, les données qui ont rendu la ressemblance possible (images utilisées avec la permission de la personne représentée).
Fréquemment, le LoRA aura un mot déclencheur formé, tel que [nom de la célébrité]. Cependant, très souvent, le sujet spécifiquement formé apparaîtra dans la sortie générée même sans de tels prompts, car même un LoRA bien équilibré (c’est-à-dire non sur-apprenu) est un peu « fixé » sur le matériel sur lequel il a été formé, et tendra à l’inclure dans toute sortie.
Cette prédisposition, combinée au nombre limité d’images qui sont optimales pour un jeu de données LoRA, expose le modèle à l’analyse forensique, comme nous le verrons.
Démasquer les Données
Ces questions sont abordées dans un nouveau document de recherche du Danemark, qui propose une méthodologie pour identifier les images sources (ou groupes d’images sources) dans une attaque de type Membership Inference Attack (MIA) en boîte noire. La technique implique au moins en partie l’utilisation de modèles formés sur mesure conçus pour aider à exposer les données sources en générant leurs propres « deepfakes » :

Exemples d’images « fausses » générées par la nouvelle approche, à des niveaux de guidance de classification sans superviseur (CFG) croissants, jusqu’au point de destruction. Source : https://arxiv.org/pdf/2502.11619
Bien que le travail, intitulé Membership Inference Attacks for Face Images Against Fine-Tuned Latent Diffusion Models, soit une contribution intéressante à la littérature autour de ce sujet particulier, il s’agit également d’un document inaccessible et écrit de manière concise qui nécessite une décoding considérable. Par conséquent, nous allons couvrir au moins les principes de base derrière le projet ici, ainsi qu’une sélection des résultats obtenus.
En effet, si quelqu’un affine un modèle d’IA sur votre visage, la méthode des auteurs peut aider à prouver cela en recherchant des signes de mémorisation dans les images générées par le modèle.
Dans un premier temps, un modèle d’IA cible est affiné sur un jeu de données d’images de visages, ce qui le rend plus susceptible de reproduire des détails de ces images dans ses sorties. Par la suite, un mode d’attaque de classification est formé en utilisant des images générées par l’IA à partir du modèle cible comme « positifs » (membres soupçonnés du jeu de données) et d’autres images à partir d’un autre jeu de données comme « négatifs » (non-membres).
En apprenant les différences subtiles entre ces groupes, le modèle d’attaque peut prédire si une image donnée faisait partie du jeu de données d’origine utilisé pour l’affiner.
L’attaque est la plus efficace dans les cas où le modèle d’IA a été affiné de manière extensive, ce qui signifie que plus un modèle est spécialisé, plus il est facile de détecter si certaines images ont été utilisées. Cela s’applique généralement aux LoRAs conçus pour recréer des célébrités ou des personnes privées.
Les auteurs ont également constaté qu’ajouter des filigranes visibles aux images de formation rend la détection encore plus facile, bien que les filigranes cachés n’offrent pas un grand avantage.
L’approche a été testée dans un environnement en boîte noire, ce qui signifie qu’elle fonctionne sans accès aux détails internes du modèle, mais uniquement à ses sorties.
La méthode obtenue est intense en termes de calcul, comme les auteurs le reconnaissent ; cependant, la valeur de ce travail réside dans l’indication de la direction pour des recherches supplémentaires, et pour prouver que les données peuvent être réellement extraites à une tolérance acceptable ; par conséquent, compte tenu de sa nature seminale, il n’a pas besoin de fonctionner sur un téléphone intelligent à ce stade.
Méthode/Données
Plusieurs jeux de données de l’Université technique du Danemark (DTU, l’institution hôte du document de recherche) ont été utilisés dans l’étude, pour affiner le modèle cible et pour former et tester le mode d’attaque.
Les jeux de données utilisés étaient dérivés de DTU Orbit :
DseenDTU L’ensemble d’images de base.
DDTU Images extraites de DTU Orbit.
DseenDTU Une partition de DDTU utilisée pour affiner le modèle cible.
DunseenDTU Une partition de DDTU qui n’a pas été utilisée pour affiner un modèle de génération d’images et a été utilisée pour tester ou former le modèle d’attaque.
wmDseenDTU Une partition de DDTU avec des filigranes visibles utilisés pour affiner le modèle cible.
hwmDseenDTU Une partition de DDTU avec des filigranes cachés utilisés pour affiner le modèle cible.
DgenDTU Images générées par un Modèle de diffusion latent (LDM) qui a été affiné sur l’ensemble d’images DseenDTU.
Les jeux de données utilisés pour affiner le modèle cible se composent de paires d’images et de texte légendés par le modèle de légende BLIP (peut-être pas par coïncidence l’un des modèles les plus populaires non censurés dans la communauté d’IA occasionnelle).
BLIP a été configuré pour préfixer la phrase ‘a dtu headshot of a’ à chaque description.
De plus, plusieurs jeux de données de l’Université d’Aalborg (AAU) ont été employés dans les tests, tous dérivés du corpus VBN d’AAU :
DAAU Images extraites d’AAU vbn.
DseenAAU Une partition de DAAU utilisée pour affiner le modèle cible.
DunseenAAU Une partition de DAAU qui n’est pas utilisée pour affiner un modèle de génération d’images, mais est utilisée pour tester ou former le modèle d’attaque.
DgenAAU Images générées par un LDM affiné sur l’ensemble d’images DseenAAU.
Équivalent aux ensembles précédents, la phrase ‘a aau headshot of a’ a été utilisée. Cela a garanti que toutes les étiquettes dans le jeu de données DTU suivaient le format ‘a dtu headshot of a (…)’, renforçant les caractéristiques de base du jeu de données pendant l’affinage.
Tests
Plusieurs expériences ont été menées pour évaluer comment les attaques d’inférence de membership se sont comportées contre le modèle cible. Chaque test visait à déterminer s’il était possible de mener une attaque réussie dans le schéma montré ci-dessous, où le modèle cible est affiné sur un jeu de données d’images obtenu sans autorisation.

Schéma de l’approche.
Avec le modèle affiné interrogé pour générer des images de sortie, ces images sont ensuite utilisées comme exemples positifs pour former le modèle d’attaque, tandis que des images supplémentaires non liées sont incluses comme exemples négatifs.
Le modèle d’attaque est formé en utilisant l’apprentissage supervisé et est ensuite testé sur de nouvelles images pour déterminer si elles faisaient partie du jeu de données utilisé pour affiner le modèle cible. Pour évaluer la précision de l’attaque, 15 % des données de test sont mis de côté pour la validation.
Puisque le modèle cible est affiné sur un jeu de données connu, le statut réel de membership de chaque image est déjà établi lors de la création des données de formation pour le modèle d’attaque. Cela permet une évaluation claire de la manière dont le modèle d’attaque peut distinguer les images qui faisaient partie du jeu de données d’affinage et celles qui ne l’étaient pas.
Pour ces tests, le modèle Stable Diffusion V1.5 a été utilisé. Bien que ce modèle relativement ancien apparaisse souvent dans la recherche en raison de la nécessité de tests cohérents et du vaste corpus de travaux antérieurs qui l’utilise, c’est une utilisation appropriée ; V1.5 est resté populaire pour la création de LoRA dans la communauté de loisirs de Stable Diffusion pendant longtemps, malgré de multiples versions ultérieures, et même malgré l’avènement de Flux – car le modèle est complètement non censuré.
Le modèle d’attaque des chercheurs était basé sur Resnet-18, avec les poids pré-formés du modèle conservés. La couche de 1000 neurones de la dernière couche de ResNet-18 a été substituée par une couche entièrement connectée avec deux neurones. La perte de formation loss était une entropie croisée catégorique, et l’optimiseur Adam a été utilisé.
Pour chaque test, le modèle d’attaque a été formé cinq fois en utilisant des graines aléatoires différentes pour calculer des intervalles de confiance à 95 % pour les métriques clés. La classification sans surveillance avec le modèle CLIP a été utilisée comme référence.
(Veuillez noter que le tableau de résultats principal original dans le document de recherche est concis et inhabituellement difficile à comprendre. Par conséquent, je l’ai reformulé ci-dessous dans un format plus convivial pour l’utilisateur. Veuillez cliquer sur l’image pour la voir en meilleure résolution)
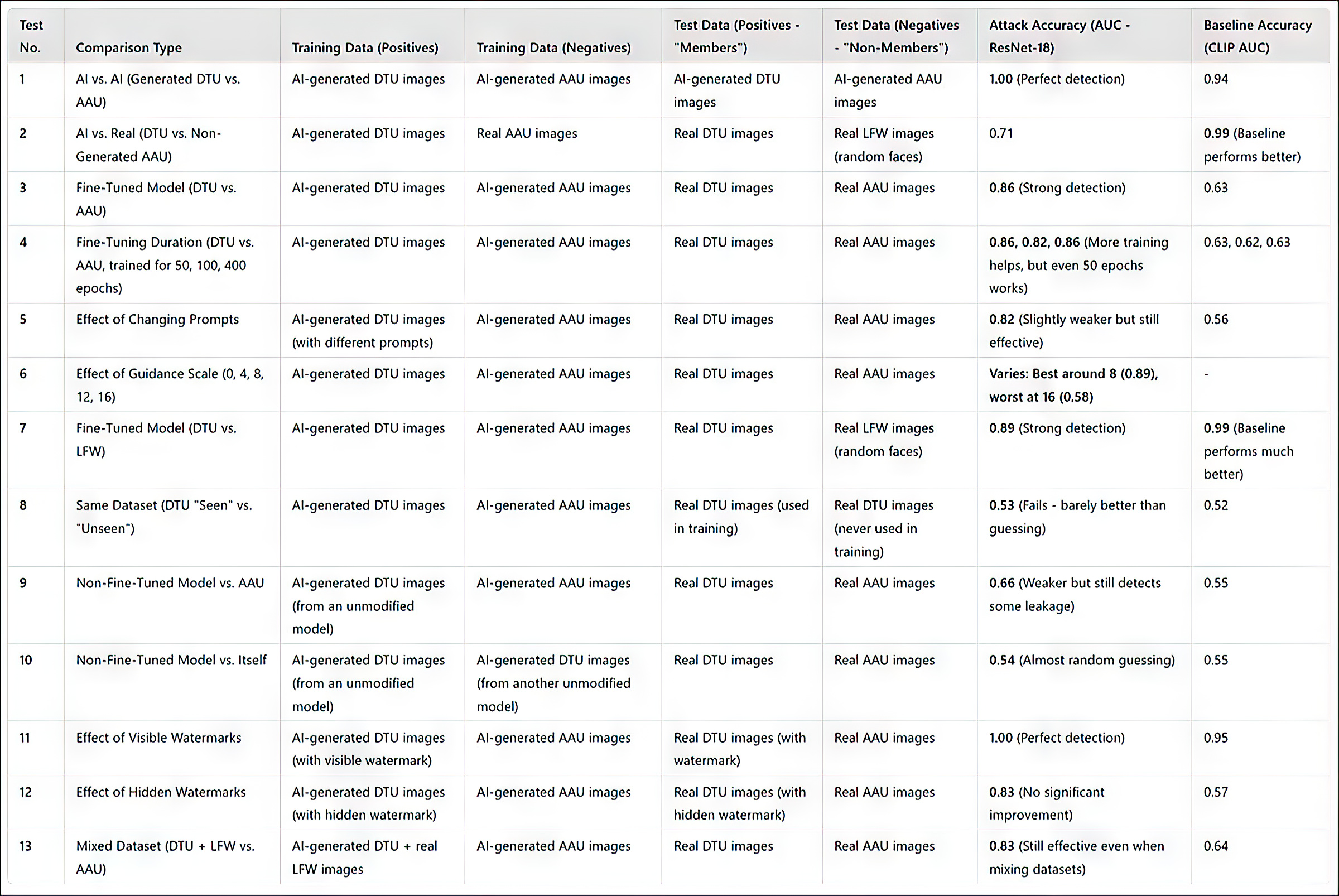
Résumé des résultats de tous les tests. Cliquez sur l’image pour la voir en meilleure résolution
La méthode d’attaque des chercheurs s’est avérée la plus efficace lorsqu’elle visait des modèles affinés, en particulier ceux formés sur un ensemble spécifique d’images, tel que le visage d’un individu. Cependant, bien que l’attaque puisse déterminer si un jeu de données a été utilisé, elle a du mal à identifier des images individuelles au sein de ce jeu de données.
Dans des termes pratiques, ce dernier n’est pas nécessairement un obstacle à l’utilisation d’une approche telle que celle-ci à des fins forensiques ; alors qu’il y a relativement peu de valeur à établir qu’un jeu de données célèbre tel que ImageNet a été utilisé dans un modèle, un attaquant contre une personne privée (et non une célébrité) aura tendance à avoir moins de choix de données sources, et devra exploiter pleinement les groupes de données disponibles tels que les albums de médias sociaux et d’autres collections en ligne. Ces derniers créent effectivement un « hash » qui peut être découvert par les méthodes décrites.
Le document de recherche note qu’une autre façon d’améliorer la précision est d’utiliser des images générées par l’IA comme « non-membres », plutôt que de compter uniquement sur des images réelles. Cela empêche des taux de réussite artificiellement élevés qui pourraient autrement tromper les résultats.
Un facteur supplémentaire qui influence considérablement la détection, notent les auteurs, est le filigrane. Lorsque les images de formation contiennent des filigranes visibles, l’attaque devient très efficace, tandis que les filigranes cachés offrent peu ou pas d’avantage.

La figure la plus à droite montre le filigrane « caché » réel utilisé dans les tests.
Enfin, le niveau de guidance dans la génération d’images texte-à-image joue également un rôle, avec l’équilibre idéal trouvé à une échelle de guidance d’environ 8. Même lorsque aucun prompt direct n’est utilisé, un modèle affiné tend encore à produire des sorties qui ressemblent à ses données de formation, renforçant ainsi l’efficacité de l’attaque.
Conclusion
Il est dommage que ce document de recherche intéressant ait été écrit de manière si inaccessible, car il devrait être d’un certain intérêt pour les défenseurs de la vie privée et les chercheurs occasionnels en IA.
Bien que les attaques d’inférence de membership puissent se révéler un outil forensique intéressant et fructueux, il est peut-être plus important pour cette branche de recherche de développer des principes applicables plus larges, pour éviter qu’elle ne se retrouve dans le même jeu de cache-cache qui a eu lieu pour la détection de deepfakes en général, lorsque la sortie d’un nouveau modèle affecte défavorablement la détection et les systèmes forensiques similaires.
Puisqu’il y a certaines preuves d’un principe directeur de niveau supérieur dans cette nouvelle recherche, nous pouvons espérer voir plus de travaux dans cette direction.
Publié pour la première fois vendredi 21 février 2025












