Tekoäly
Ei, heillä ei ollut mitään tekemistä Claude:n hidastamisen kanssa – se oli vielä huonompi

Oikein, puhutaan siitä, mitä on tapahtunut Claude:n kanssa, koska jos olet käyttänyt sitä viime kuukauden aikana, sinun on luultavasti huomannut, että jokin on vialla.
Kuuden viikon ajan Claude:n käyttäjät ovat menettäneet järkensä. Elokuun alusta lähtien valituksia tulvi Reddit:iin, X:ään ja kehittäjien foorumeille. Ongelmat olivat kaikkialla:
- Koodi, joka aiemmin toimi täydellisesti, oli yhtäkkiä rikki
- Claude väitti, että se oli tehnyt muutoksia tiedostoihin, vaikka se ei ollutkaan
- Sattumanvaraiset thain ja kiinan merkit ilmestyivät englanninkielisiin vastauksiin
- Ohjeita ei noudatettu
- Sama kysymys sai täysin erilaisia vastauksia
- Claude Code:n käyttäjät sanoivat, että se tuntui “lobotomoidulta” verrattuna aikaisempaan
Valitukset olivat niin pahia, että elokuun lopussa ihmiset olivat vakuuttuneita siitä, että Anthropic salaa hidastaa Claude:a säästääkseen rahaa. Salaliittoteoriat olivat joka puolella – ehkä he olivat vähentäneet laatua ruuhka-aikoina, ehkä he olivat vaihtaneet halvemman mallin, ehkä tämä oli tarkoituksellinen heikentäminen hallitakseen palvelimen kustannuksia.
Käyttäjät maksoivat Claude Pro:sta ja saivat vastineeksi mitä tuntui olevan Claude Lite. Kehittäjät, jotka olivat rakentaneet työvirran Claude:n ympärille, katsoivat yhtäkkiä tuottavuutensa romahtavan. Sanotaan, että jotkut käyttäjät eivät kokeneet mitään ongelmia, mikä teki kaiken vielä monimutkaisemmaksi.
Anthropic Myöntää Lopulta: Kyllä, Meillä Oli Ongelmia
Käyttäjien valitusten ja kasvavan pettymysten jälkeen, Anthropic on julkaissut massiivisen teknisen post-mortem-raportin, joka sanoo perustuu: “Te olette oikein. Claude oli rikki. Tässä on mitä tapahtui.”
Ja vastaus on mielenkiintoinen.
Tuli ilmi, ettei ollut yhtä ongelmaa. Se oli kolme täysin erillistä infrastruktuurivirhettä, jotka kaikki vaikuttivat samanaikaisesti ja loivat täydellisen myrskyn AI-heikentymisestä. He eivät olleet hidastamassa. He eivät leikanneet kulua. Heillä oli vain kolme eri asiaa, jotka menevät rikki samanaikaisesti tavalla, joka vei heiltä kuusi viikkoa ymmärtää ja korjata.
Anna minun selittää tarkemmin, mitä meni vikaan, koska tämä on todella hyödyllinen katsaus siitä, miten nämä AI-järjestelmät voivat epäonnistua tavalla, jota kukaan ei odota.
Kolmen Virheen Romahdus: Kaaoksen Aikajana
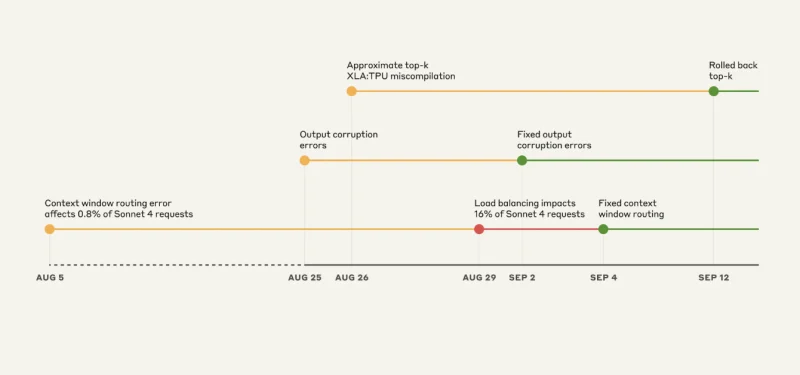
Lähde: Anthropic
Virhe #1: Väärä Palvelinongelma
Tämä on melkein hauska, jos et olisi se, joka koki sen. Claude Sonnet 4 oli suunniteltu käsittelemään 200 000 tokenin konteksteja. Mutta elokuun 5. päivästä lähtien jotkut pyynnöt ohjattiin palvelimille, jotka oli määritelty 1 miljoonan tokenin konteksteja varten.
Aluksi vain 0,8% pyynnöistä vaikuttui. Ei suuri asia, oikea? Väärin.
Elokuun 29. päivänä säännöllinen kuormituksen tasapainotus päivittäminen muutti tämän pienen ongelman suureksi ongelmaksi. Yhtäkkiä huipussa 16% Sonnet 4 -pyynnöistä ohjattiin väärille palvelimille. Ja reititys oli “tahmea”. Kun sinut ohjattiin väärään reittiin, sinä jäit siihen.
Vaikutus:
- Noin 30% Claude Code -käyttäjistä, jotka olivat aktiivisia kyseisen ajanjakson aikana, kokivat vähintään yhden pyynnön, joka ohjattiin väärään reittiin
- Vastausajat heikkenivät vaikuttuneille käyttäjille
- Sama käyttäjä koki ongelman toistuvasti, kun taas toiset eivät kokeneet mitään ongelmia
Virhe #2: Sattumanvarainen Merkinten Generaattori
Elokuun 25. päivänä Anthropic asensi virheellisen konfiguraation heidän TPU-palvelimiinsa. Tuloksena oli, että Claude alkoi sattumanvaraisesti lisätä thain ja kiinan merkkejä englanninkielisiin vastauksiin.
Kuvittele, että pyydät Claude:ta debugaamaan Python-koodisi ja saat tämän:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price # <- Mitä?
return ผลรวม
Tämä vaikutti:
- Opus 4.1 ja Opus 4: 25.-28. elokuuta
- Sonnet 4: 25. elokuuta – 2. syyskuuta
Tekninen syy oli tokenin generoimisvirhe, joka antoi korkean todennäköisyyden merkeille, joilla ei ollut mitään asiaa. Se murskasi perustavanlaatuisen mekanismin, jolla Claude valitsee seuraavan sanan.
Virhe #3: Näkymätön Kääntäjän Virhe
Tämä on pelottava osa insinöörien näkökulmasta. Google:n XLA-kääntäjässä oli ollut latentti virhe, joka oli ollut piilevä. Kun Anthropic asensi koodin parantamaan tokenin valintaa elokuun 25. päivänä, he käynnistivät vahingossa sen.
Tämä virhe oli todella outo – se sai aikaan, että Claude vahingossa jätti pois todennäköisimmän tokenin tekstiä generoitaessa. Claude tiesi oikean vastauksen, mutta se estettiin fyysisesti sanomasta sitä.
Todella sekava osa? He olivat todella kiertäneet tämän virheen joulukuussa 2024 ilman, että he olivat sitä tajunneet. Kun he “korjasivat” sitä, mitä he luulivat olevan alkuperäinen syy elokuussa, he poistivat kiertoreitin ja päästivät todellisen ongelman valloilleen.
Miksi Korjaaminen Kesti Kuusi Viikkoa
Sinun saatat ihmetellä: miten yhtiö kuten Anthropic, jolla on maailmanluokan insinöörit, voi viedä kuusi viikkoa ymmärtääkseen tämän?
Vastaus paljastaa, kuinka monimutkaisia nämä järjestelmät todella ovat:
1. Yksityisyysvalvonta Esti Vianmääritystä
“Sisäiset yksityisyys- ja turvallisuusvalvontamme rajoittavat, miten ja milloin insinöörit voivat käyttää Claude:a, erityisesti kun nämä vuorovaikutukset eivät ole ilmoitettu meille palautteena.”
He eivät voineet nähdä, mitä menee vikaan, ellei käyttäjät ilmoittaneet siitä palautteena. Hyvä yksityisyydelle, mutta huono vianmääritykselle.
2. Virheet Piilottivat Itsensä
Claude usein toipui yksittäisistä virheistä, mikä teki heikentymisestä näyttää siltä, kuin se olisi normaali vaihtelu eikä systemaattinen virhe. Heidän benchmarkkinsa ja arviointinsa eivät havainneet sitä, koska malli korjasi itsensä tarpeeksi päästäkseen läpi testeistä.
3. Monialustainen Kaaos
Claude toimii AWS Trainiumilla, NVIDIA:n GPU:illa ja Google:n TPU:illa – kolmella täysin erilaisella laitteistojärjestelmällä. Jokainen virhe ilmeni eri tavalla kussakin järjestelmässä:
- AWS Bedrock: 0,18% Sonnet 4 -pyynnöistä vaikuttui huipussa
- Google Vertex AI: Alle 0,0004% vaikuttui
- Suora API: Jopa 16% vaikuttui
Tämä teki siitä näyttää siltä, kuin olisi useita erillisiä ongelmia eikä kolmea tiettyä virhettä.
4. Oireiden Yhdistäminen
Kolmen virheen ollessa aktiivisia samanaikaisesti, oireet olivat kaikkialla. Yksi käyttäjä saattoi saada thain merkkejä, toinen saattoi saada heikentyneitä vastauksia, kolmas saattoi nähdä täydellisen suorituskyvyn. Ei ollut selkeää mallia seurata.
Mitä Tämä Todella Merkitsee AI:n Luotettavuudelle
Tämä koko saga paljastaa jotain olennaista nykyisten AI-järjestelmien tilasta: ne ovat paljon hauraimpia, kuin ne näyttävät.
Emme puhu vain itse AI-mallista. Puhumme:
- Reititysinfrastruktuurista, joka voi lähettää pyynnöt väärään paikkaan
- Laitteistokohtaisista toteutuksista, jotka käyttäytyvät eri tavalla
- Kääntäjän virheistä, jotka voivat olla piilevässä tilassa kuukausia
- Kuormituksen tasapainotusohjelmista, jotka voivat muuttaa pienet ongelmat suuriksi katkoksi
Yksi virheellinen konfiguraatio, yksi kääntäjän virhe, yksi reititysvirhe – ja yhtäkkiä AI-avustajasi unohtaa, miten koodata tai alkaa puhua kieliä, joita se ei pitäisi.
Onko Se Todella Korjattu?
Anthropic sanoo, että he ovat ratkaisseet kaikki kolme ongelmaa 16. syyskuuta mennessä. He ovat:
- Korjanneet reitityslogiikan
- Peruuttaneet ongelmalliset konfiguraatiot
- Vaihtaneet likimääräisestä top-k -operaatiosta tarkkaan (ottamalla suorituskyvyn laskun tarkkuuden vuoksi)
- Lisänneet jatkuvaan tuotantoon valvontaa
Mutta käyttäjät ilmoittavat edelleen ongelmia. Jotkut kehittäjät väittävät, että Claude Code:tä edelleen tuntuu heikentyneen verrattuna sen aiempaan suorituskykyyn. Onko se:
- Jäännösvaikutuksia virheistä
- Uusia ongelmia, joita ei ole vielä tunnistettu
- Psykologista vinoumaa useiden viikkojen ongelmien jälkeen
- Tai todellista jatkuva heikentymistä
…emme tiedä vielä.
Pohjimmiltaan
Tämä tilanne on täydellinen tapaustutkimus siitä, miten monimutkaiset AI-järjestelmät voivat epäonnistua täysin odottamattomilla tavoilla. Kolme erillistä virhettä, jotka laukaisivat kaikki viikon sisällä toisistaan, loivat laajan laadun heikentymisen vaikutelman, joka kesti kuusi viikkoa diagnosoida ja korjata.
Voimme antaa Anthropic:lle kiitosta avoimuudesta. Teknisen post-mortem-raportin julkaiseminen on enemmän, kuin useimmat yhtiöt tekisivät. Mutta se myös osoittaa, kuinka paljon voi mennä vikaan näiden järjestelmien alla, joihin me luotamme yhä enemmän.
Kaikille, jotka rakentavat Claude:aan tai mihin tahansa LLM:ään: teidän tarvitsee redundanssi, validointi ja varasuunnitelmat. Koska, kuten olemme juuri nähneet, jopa parhaat AI-järjestelmät voivat olla kolmea eri ongelmaa samanaikaisesti, ja se saattaa kestää viikkoja, ennen kuin kukaan tajuaa, mitä todella tapahtuu.
Näiden AI-mallien tukemiseen käytettävä infrastruktuuri on yhtä tärkeä kuin mallit itse. Ja tällä hetkellä se infrastruktuuri näyttää olevan kasvukipujen keskellä.












