
Tekoäly
InstructIR: Korkealaatuinen kuvan palauttaminen ihmisen ohjeiden mukaan

Kuva voi välittää paljon, mutta sitä voivat myös häiritä erilaiset ongelmat, kuten liikkeen epäterävyys, utu, kohina ja alhainen dynaaminen alue. Nämä ongelmat, joita yleisesti kutsutaan heikon tietokonenäön heikkenemiseksi, voivat johtua vaikeista ympäristöolosuhteista, kuten kuumuudesta tai sateesta, tai itse kameran rajoituksista. Kuvan palauttaminen on keskeinen haaste tietokonenäön alalla, sillä se pyrkii saamaan laadukkaan ja puhtaan kuvan sellaisesta, jossa on tällaisia vaurioita. Kuvan palauttaminen on monimutkaista, koska minkä tahansa kuvan palauttamiseen voi olla useita ratkaisuja. Jotkut lähestymistavat kohdistuvat tiettyihin heikkenemiseen, kuten melun vähentämiseen tai epätarkkuuden tai sameuden poistamiseen.
Vaikka nämä menetelmät voivat tuottaa hyviä tuloksia tietyissä ongelmissa, niillä on usein vaikeuksia yleistää erityyppisiin huonontumiseen. Monet kehykset käyttävät yleistä hermoverkkoa monenlaisiin kuvanpalautustehtäviin, mutta nämä verkot opetetaan kukin erikseen. Erilaisten mallien tarve kutakin heikkenemistyyppiä varten tekee tästä lähestymistavasta laskennallisesti kallista ja aikaa vievää, mikä johtaa viimeaikaisessa kehityksessä keskittymiseen All-In-One-restaurointimalleihin. Näissä malleissa käytetään yhtä syvän sokean palautusmallia, joka käsittelee useita tasoja ja -tyyppejä huonontumisesta ja käyttää usein huononemiskohtaisia kehotteita tai ohjausvektoreita suorituskyvyn parantamiseksi. Vaikka All-In-One-mallit osoittavat yleensä lupaavia tuloksia, ne kohtaavat silti haasteita käänteisten ongelmien kanssa.
InstructIR edustaa uraauurtavaa lähestymistapaa alalla, joka on ensimmäinen kuvan palauttaminen kehys, joka on suunniteltu ohjaamaan restaurointimallia ihmisen kirjoittamien ohjeiden avulla. Se voi käsitellä luonnollisen kielen kehotteita palauttaakseen korkealaatuisia kuvia huonontuneista kuvista ottaen huomioon erilaiset huononemistyypit. InstructIR asettaa uuden suorituskyvyn standardin useille kuvien palautustehtäville, mukaan lukien hämärän kuvan poistaminen, kohinan poistaminen, hämärtäminen, epätarkkuuden poistaminen ja parantaminen hämärässä.
Tämän artikkelin tarkoituksena on kattaa InstructIR-kehys perusteellisesti, ja tutkimme mekanismia, metodologiaa, viitekehyksen arkkitehtuuria sekä sen vertailua uusimpien kuvien ja videoiden luontikehysten kanssa. Joten aloitetaan.
InstructIR: Korkealaatuinen kuvanpalautus
Kuvan palauttaminen on tietokonenäön perusongelma, koska sen tarkoituksena on palauttaa korkealaatuinen puhdas kuva kuvasta, joka osoittaa huonontumista. Matalatasoisessa tietokonenäössä huonontuminen on termi, jota käytetään kuvaamaan kuvassa havaittuja epämiellyttäviä vaikutuksia, kuten liikkeen epäterävyyttä, sameutta, kohinaa, alhaista dynaamista aluetta ja paljon muuta. Syy siihen, miksi kuvan palauttaminen on monimutkainen käänteinen haaste, johtuu siitä, että minkä tahansa kuvan palauttamiseen voi olla useita erilaisia ratkaisuja. Jotkut kehykset keskittyvät tiettyihin heikkenemiseen, kuten ilmentymien kohinan vähentämiseen tai kuvan kohinan vaimentamiseen, kun taas toiset saattavat keskittyä enemmän epätarkkuuden tai epätarkkuuden poistamiseen tai sameuden tai hämärtymisen poistamiseen.
Viimeaikaiset syväoppimismenetelmät ovat osoittaneet vahvempaa ja johdonmukaisempaa suorituskykyä perinteisiin kuvanpalautusmenetelmiin verrattuna. Nämä syväoppivan kuvan palautusmallit ehdottavat muuntajiin ja konvoluutiohermoverkkoihin perustuvien hermoverkkojen käyttöä. Näitä malleja voidaan kouluttaa itsenäisesti erilaisiin kuvien palautustehtäviin, ja niillä on myös kyky vangita paikallisia ja globaaleja ominaisuuksien vuorovaikutuksia ja parantaa niitä, mikä johtaa tyydyttävään ja tasaiseen suorituskykyyn. Vaikka jotkin näistä menetelmistä voivat toimia riittävästi tietyntyyppisissä hajoamistyypeissä, ne eivät tyypillisesti ekstrapoloi hyvin erilaisiin hajoamistyyppeihin. Lisäksi vaikka monet olemassa olevat puitteet käyttävät samaa hermoverkkoa useisiin kuvanpalautustehtäviin, jokainen hermoverkkoformulaatio opetetaan erikseen. Tästä syystä on ilmeistä, että erillisen hermomallin käyttäminen jokaista ajateltavissa olevaa huononemista varten on epäkäytännöllistä ja aikaa vievää, minkä vuoksi viimeaikaiset kuvanpalautuskehykset ovat keskittyneet All-In-One-palautusvälityspalvelimiin.
All-In-One- tai Multi-degradation- tai Multi-task-kuvanpalautusmallit ovat saamassa suosiota tietokonenäkökentässä, koska ne pystyvät palauttamaan kuvan useiden erityyppisten ja -tasojen huononemisen ilman, että malleja tarvitsee kouluttaa erikseen jokaista heikkenemistä varten. . All-In-One-kuvanpalautusmallit käyttävät yhtä syvän sokean kuvan palautusmallia erityyppisten ja eritasoisten kuvan huononemisen hallintaan. Eri All-In-One-mallit käyttävät erilaisia lähestymistapoja ohjaamaan sokeaa mallia palauttamaan huonontunut kuva, esimerkiksi apumalli, joka luokittelee huononemisen tai moniulotteiset ohjausvektorit tai kehotteet, jotka auttavat mallia palauttamaan erityyppiset heikkenemismuodot kuva.
Tästä huolimatta pääsemme tekstipohjaiseen kuvankäsittelyyn, koska useat viitekehykset ovat viime vuosina ottaneet käyttöön tekstistä kuvaksi luomiseen ja tekstipohjaisiin kuvankäsittelytehtäviin. Nämä mallit käyttävät usein tekstikehotteita kuvaamaan toimintoja tai kuvia yhdessä diffuusiopohjaiset mallit luodaksesi vastaavat kuvat. InstructIR-kehyksen pääinspiraationa on InstructPix2Pix-kehys, jonka avulla malli voi muokata kuvaa käyttämällä käyttäjän ohjeita, jotka opastavat mallia tekemään toimenpiteitä syöttökuvan tekstitunnisteiden, kuvausten tai kuvatekstien sijaan. Tämän seurauksena käyttäjät voivat käyttää luonnollisia kirjoitettuja tekstejä ohjaamaan mallia, mitä toimenpiteitä on suoritettava ilman, että tarvitsee tarjota esimerkkikuvia tai lisäkuvauksia.
Näihin perusteisiin perustuva InstructIR-kehys on kaikkien aikojen ensimmäinen tietokonenäkömalli, joka käyttää ihmisen kirjoittamia ohjeita kuvan palauttamiseen ja käänteisten ongelmien ratkaisemiseen. Luonnollisen kielen kehotteita varten InstructIR-malli voi palauttaa korkealaatuisia kuvia huononnetuista vastineistaan ja ottaa huomioon myös useita huononemistyyppejä. InstructIR-kehys pystyy tarjoamaan huippuluokan suorituskyvyn monenlaisissa kuvanpalautustehtävissä, mukaan lukien kuvan vääristymisen, kohinan poistamisen, hämärtymisen, epätarkkuuden ja kuvan parantamisen hämärässä. Toisin kuin olemassa olevat teokset, joissa kuvien palauttaminen saavutetaan käyttämällä opittuja ohjausvektoreita tai kehote upotuksia, InstructIR-kehys käyttää raakoja käyttäjäkehotteita tekstimuodossa. InstructIR-kehys pystyy yleistämään kuvien palauttamiseen ihmisen kirjoitetuilla ohjeilla, ja InstructIR:n toteuttama yksittäinen all-in-one -malli kattaa aiempia malleja enemmän palautustehtäviä. Seuraava kuva esittää InstructIR-kehyksen erilaisia palautusnäytteitä.

InstructIR: Menetelmä ja arkkitehtuuri
InstructIR-kehys koostuu ytimestä tekstienkooderista ja kuvamallista. Malli käyttää kuvamallina NAFNet-kehystä, tehokasta kuvanpalautusmallia, joka noudattaa U-Net-arkkitehtuuria. Lisäksi malli toteuttaa tehtävien reititystekniikoita useiden tehtävien oppimiseksi onnistuneesti yhdellä mallilla. Seuraava kuva havainnollistaa InstructIR-kehyksen koulutus- ja arviointitapaa.

InstructPix2Pix-mallista inspiraation saaneen InstructIR-kehyksen ohjausmekanismina käytetään ihmisen kirjoittamia ohjeita, koska käyttäjän ei tarvitse antaa lisätietoja. Nämä ohjeet tarjoavat ilmeisen ja selkeän tavan olla vuorovaikutuksessa, jolloin käyttäjät voivat osoittaa kuvan tarkan sijainnin ja huononemisen tyypin. Lisäksi käyttäjäkehotteiden käyttäminen kiinteiden huononemiskohtaisten kehotteiden sijaan parantaa mallin käytettävyyttä ja sovelluksia, koska sitä voivat käyttää myös käyttäjät, joilla ei ole tarvittavaa toimialueasiantuntemusta. InstructIR-kehyksen varustamiseksi kyvyllä ymmärtää erilaisia kehotteita malli käyttää GPT-4:ää, suurta kielimallia erilaisten pyyntöjen luomiseen, ja moniselitteiset ja epäselvät kehotteet poistetaan suodatusprosessin jälkeen.
Tekstienkooderi
Kielimallit käyttävät tekstienkooderia yhdistämään käyttäjän kehotteet tekstin upotukseen tai kiinteän kokoiseen vektoriesitykseen. Perinteisesti tekstikooderi a CLIP malli on tärkeä osa tekstipohjaisten kuvien luonnissa ja tekstipohjaisissa kuvankäsittelymalleissa käyttäjien kehotteiden koodaamiseksi, koska CLIP-kehys on erinomainen visuaalisissa kehotteissa. Useimmiten kuitenkin käyttäjien huononemiskehotuksissa on vain vähän tai ei ollenkaan visuaalista sisältöä, minkä vuoksi suuret CLIP-enkooderit ovat hyödyttömiä tällaisiin tehtäviin, koska se heikentää tehokkuutta merkittävästi. Tämän ongelman ratkaisemiseksi InstructIR-kehys valitsee tekstipohjaisen lausekooderin, joka on koulutettu koodaamaan lauseita mielekkäässä upotustilassa. Lauseenkooderit on valmiiksi koulutettu miljoonien esimerkkien perusteella, ja silti ne ovat kompakteja ja tehokkaita verrattuna perinteisiin CLIP-pohjaisiin tekstikooderiin, samalla kun niillä on kyky koodata erilaisten käyttäjäkehotteiden semantiikkaa.
Tekstiopastus
InstructIR-kehyksen tärkeä näkökohta on koodatun käskyn toteuttaminen kuvamallin ohjausmekanismina. Tämän pohjalta ja inspiroituneena monien tehtävien reitittämiseen InstructIR-kehys ehdottaa Instruction Construction Blockia tai ICB:tä mahdollistamaan tehtäväkohtaiset muunnokset mallissa. Perinteinen tehtäväreititys käyttää tehtäväkohtaisia binaarimaskeja kanavan ominaisuuksiin. Koska InstructIR-kehys ei kuitenkaan tunne hajoamista, tätä tekniikkaa ei toteuteta suoraan. Lisäksi kuvaominaisuuksille ja koodatuille käskyille InstructIR-kehys käyttää tehtäväreititystä ja tuottaa maskin käyttämällä Sigmoid-funktiolla aktivoitua lineaarista kerrosta tuottamaan painojoukon tekstin upottamisesta riippuen, jolloin saadaan c-ulottuvuus per. kanavan binaarimaski. Malli parantaa edelleen ehdollisia ominaisuuksia käyttämällä NAFBlockia ja käyttää NAFBlockia ja Instruction Conditioned Blockia ominaisuuksien ehdoittamiseen sekä enkooderilohkossa että dekooderilohkossa.
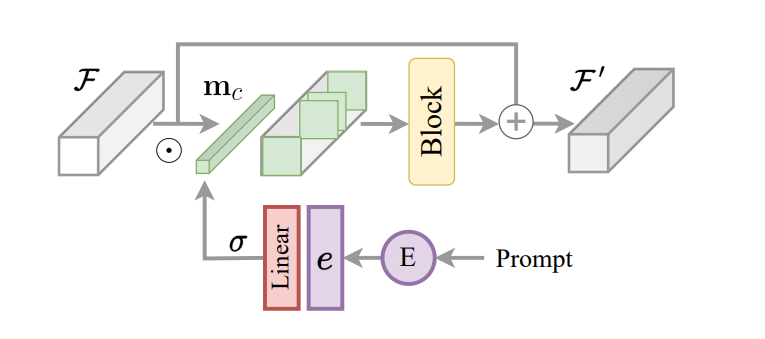
Vaikka InstructIR-kehys ei edellytä hermoverkkosuodattimia eksplisiittisesti, maski auttaa mallia valitsemaan kuvaohjeiden ja tietojen perusteella oleellisimmat kanavat.
InstructIR: Toteutus ja tulokset
InstructIR-malli on päästä päähän koulutettava, eikä kuvamalli vaadi esikoulutusta. Vain tekstin upotusprojektiot ja luokituspää on koulutettava. Tekstienkooderi alustetaan käyttämällä BGE-enkooderia, BERT:n kaltaista kooderia, joka on valmiiksi koulutettu valtavalle määrälle valvottua ja valvomatonta dataa yleiskäyttöistä lauseen koodausta varten. InstructIR-kehys käyttää NAFNet-mallia kuvamallina ja NAFNetin arkkitehtuuri koostuu 4-tasoisesta kooderidekooderista, jossa on vaihteleva määrä lohkoja kullakin tasolla. Malli lisää myös 4 keskimmäistä lohkoa kooderin ja dekooderin väliin ominaisuuksien parantamiseksi. Lisäksi ohitusyhteyksien ketjuttamisen sijaan dekooderi toteuttaa summauksen ja InstructIR-malli toteuttaa vain ICB:n tai Instruction Conditioned Blockin tehtävän reititystä varten vain kooderissa ja dekooderissa. Jatkettaessa InstructIR-mallia optimoidaan käyttämällä häviötä palautetun kuvan ja totuudenmukaisen puhtaan kuvan välillä, ja ristientropiahäviötä käytetään tekstienkooderin intent-luokituspäässä. InstructIR-mallissa käytetään AdamW-optimoijaa, jonka eräkoko on 32 ja oppimisnopeus 5e-4 lähes 500 epookin ajan, ja se toteuttaa myös kosinihehkutuksen oppimisnopeuden vaimenemisen. Koska InstructIR-kehyksen kuvamalli sisältää vain 16 miljoonaa parametria ja opittuja tekstin projektioparametreja on vain 100 XNUMX, InstructIR-kehys on helposti koulutettavissa tavallisilla GPU:illa, mikä vähentää laskentakustannuksia ja lisää soveltuvuutta.
Useita hajoamistuloksia
InstructIR-kehys määrittelee kaksi alkuasetusta useille huononnuksille ja usean tehtävän palautuksille:
- 3D kolmen hajoamisen malleille ratkaisemaan huononemisongelmia, kuten hämärtymistä, melun vaimentamista ja rappeutumista.
- 5D viidelle huononemismallille, jotka ratkaisevat heikkenemisongelmia, kuten kuvan kohinaa, parannuksia heikossa valaistuksessa, hämärtymistä, kohinan vaimentamista ja vääristymistä.
5D-mallien suorituskyky on esitelty seuraavassa taulukossa, ja siinä verrataan sitä uusimpaan kuvanpalautukseen ja all-in-one-malleihin.

Kuten voidaan havaita, InstructIR-kehys yksinkertaisella kuvamallilla ja vain 16 miljoonalla parametrilla pystyy käsittelemään viisi erilaista kuvanpalautustehtävää ohjepohjaisen ohjauksen ansiosta ja tuottaa kilpailukykyisiä tuloksia. Seuraava taulukko osoittaa kehyksen suorituskyvyn 3D-malleissa, ja tulokset ovat verrattavissa yllä oleviin tuloksiin.

InstructIR-kehyksen pääkohokohta on käskypohjainen kuvan palauttaminen, ja seuraava kuva havainnollistaa InstructIR-mallin uskomattomia kykyjä ymmärtää monenlaisia ohjeita tiettyyn tehtävään. Myös kontradiktoriselle käskylle InstructIR-malli suorittaa identiteetin, jota ei pakoteta.

Loppuajatukset
Kuvan palauttaminen on tietokonenäön perusongelma, koska sen tarkoituksena on palauttaa korkealaatuinen puhdas kuva kuvasta, joka osoittaa huonontumista. Matalatasoisessa tietokonenäössä huonontuminen on termi, jota käytetään kuvaamaan kuvassa havaittuja epämiellyttäviä vaikutuksia, kuten liikkeen epäterävyyttä, sameutta, kohinaa, alhaista dynaamista aluetta ja paljon muuta. Tässä artikkelissa olemme puhuneet InstructIR:stä, maailman ensimmäisestä kuvanpalautuskehyksestä, joka pyrkii ohjaamaan kuvanpalautusmallia ihmisen kirjoittamien ohjeiden avulla. Luonnollisen kielen kehotteita varten InstructIR-malli voi palauttaa korkealaatuisia kuvia huononnetuista vastineistaan ja ottaa huomioon myös useita huononemistyyppejä. InstructIR-kehys pystyy tarjoamaan huippuluokan suorituskyvyn monenlaisissa kuvanpalautustehtävissä, mukaan lukien kuvan vääristymisen, kohinan poistamisen, hämärtymisen, epätarkkuuden ja kuvan parantamisen hämärässä.















