
Tekoäly
EfficientViT: Muistitehokas visiomuuntaja korkearesoluutioiseen tietokonenäköön

Suuren mallikapasiteetin ansiosta Vision Transformer -malleilla on viime aikoina ollut suuri menestys. Suorituskyvystään huolimatta näkömuuntajamalleilla on yksi suuri puute: niiden huomattava laskentakyky johtuu korkeista laskentakustannuksista, ja siksi näkömuuntajat eivät ole ensimmäinen valinta reaaliaikaisiin sovelluksiin. Tämän ongelman ratkaisemiseksi joukko kehittäjiä lanseerasi EfficientViT:n, perheen nopeita näkömuuntajia.
EfficientViT-työskentelyn aikana kehittäjät havaitsivat, että nykyisten muuntajamallien nopeutta rajoittavat usein tehottomat muistitoiminnot, erityisesti elementtikohtaiset toiminnot ja tensorien uudelleenmuotoilu MHSA- tai Multi-Head Self Attention -verkossa. Näiden tehottomien muistitoimintojen ratkaisemiseksi EfficientViT-kehittäjät ovat työstäneet uutta rakennuspalkkaa käyttämällä sandwich-layoutia eli EfficientViT-mallissa käytetään yhtä muistiin sidottua Multi-Head Self Attention -verkkoa tehokkaiden FFN-kerrosten välillä, mikä auttaa parantamaan muistin tehokkuutta. parantaa myös yleistä kanavaviestintää. Lisäksi malli havaitsee myös, että huomiokartoilla on usein suuria yhtäläisyyksiä päiden välillä, mikä johtaa laskennalliseen redundanssiin. Redundanssiongelman ratkaisemiseksi EfficientViT-malli esittelee peräkkäisen ryhmätarkkailumoduulin, joka syöttää huomiopäät täyden ominaisuuden eri jaotteluihin. Menetelmä paitsi säästää laskennallisia kustannuksia, myös parantaa mallin huomion monimuotoisuutta.
EfficientViT-mallilla eri skenaarioissa tehdyt kattavat kokeet osoittavat, että EfficientViT ylittää olemassa olevat tehokkaat mallit tietokoneen visio samalla kun saavutetaan hyvä kompromissi tarkkuuden ja nopeuden välillä. Sukellaan siis syvemmälle ja tutkitaan EfficientViT-mallia hieman syvemmälle.
Vision Transformersin ja EfficientViT:n esittely
Vision Transformers ovat edelleen yksi suosituimmista viitekehyksestä tietokonenäköalalla, koska ne tarjoavat erinomaisen suorituskyvyn ja korkeat laskentaominaisuudet. Näkömuuntajamallien tarkkuuden ja suorituskyvyn jatkuvan parantuessa myös käyttökustannukset ja laskennalliset yleiskustannukset kasvavat. Esimerkiksi nykyiset mallit, joiden tiedetään tarjoavan uusinta suorituskykyä ImageNet-tietojoukoissa, kuten SwinV2 ja V-MoE, käyttävät 3B- ja 14.7B-parametreja. Näiden mallien pelkkä koko yhdistettynä laskentakustannuksiin ja vaatimuksiin tekevät niistä käytännössä sopimattomia reaaliaikaisiin laitteisiin ja sovelluksiin.
EfficientNet-mallin tavoitteena on selvittää, miten tehokkuutta voidaan parantaa näkömuuntajamallitja löytää periaatteet tehokkaiden ja tehokkaiden muuntajapohjaisten kehysarkkitehtuurien suunnittelussa. EfficientViT-malli perustuu olemassa oleviin näkömuuntajakehyksiin, kuten Swim ja DeiT, ja se analysoi kolme olennaista tekijää, jotka vaikuttavat mallien häiriönopeuksiin, mukaan lukien laskennan redundanssi, muistin käyttö ja parametrien käyttö. Lisäksi mallissa havaitaan, että näkömuuntajamallien nopeus muistiin sidottuissa, mikä tarkoittaa, että prosessorien/GPU:iden laskentatehon täysi hyödyntäminen on kielletty tai rajoitettu muistin käyttöviiveen vuoksi, mikä vaikuttaa negatiivisesti muuntajien ajonopeuteen. . Elementtikohtaiset toiminnot ja tensorien uudelleenmuotoilu MHSA- tai Multi-Head Self Attention -verkossa ovat muistin kannalta tehottomimpia toimintoja. Malli havaitsee lisäksi, että FFN:n (feed forward network) ja MHSA:n välisen suhteen optimaalinen säätäminen voi auttaa vähentämään merkittävästi muistin käyttöaikaa vaikuttamatta suorituskykyyn. Malli havaitsee kuitenkin myös jonkin verran redundanssia huomiokartoissa, mikä johtuu huomiopään taipumuksesta oppia samanlaisia lineaarisia projektioita.
Malli on EfficientViT:n tutkimustyön tulosten lopullinen kultivointi. Mallissa on uusi musta sandwich-asettelulla, joka käyttää yhtä muistiin sidottua MHSA-kerrosta Feed Forward Network- tai FFN-kerrosten välissä. Lähestymistapa ei vain lyhennä muistiin sidottujen toimintojen suorittamiseen kuluvaa aikaa MHSA:ssa, vaan se myös tekee koko prosessista tehokkaamman muistin sallimalla useamman FFN-kerroksen helpottaa viestintää eri kanavien välillä. Mallissa hyödynnetään myös uutta CGA- tai Cascaded Group Attention -moduulia, jonka tavoitteena on tehostaa laskelmia vähentämällä laskennallista redundanssia huomiopäiden lisäksi myös lisäämällä verkon syvyyttä, mikä johtaa kohonneeseen mallikapasiteettiin. Lopuksi malli laajentaa keskeisten verkkokomponenttien kanavan leveyttä, mukaan lukien arvoennusteet, samalla kun pienentää verkkokomponentteja, joilla on pieni arvo, kuten piilotetut mitat syöttöverkoissa parametrien uudelleenjakamiseksi kehyksessä.

Kuten yllä olevasta kuvasta näkyy, EfficientViT-kehys toimii paremmin kuin nykyiset CNN- ja ViT-mallit sekä tarkkuuden että nopeuden suhteen. Mutta kuinka EfficientViT-kehys onnistui päihittämään jotkin nykyiset huipputason puitteet? Otetaan se selvää.
EfficientViT: Vision Transformersin tehokkuuden parantaminen
EfficientViT-mallin tavoitteena on parantaa olemassa olevien näkömuuntajamallien tehokkuutta kolmella näkökulmalla,
- Laskennallinen redundanssi.
- Muistin käyttö.
- Parametrien käyttö.
Mallin tavoitteena on selvittää, miten yllä olevat parametrit vaikuttavat näkömuuntajamallien tehokkuuteen ja miten ne ratkaistaan, jotta saavutetaan parempia tuloksia paremmalla hyötysuhteella. Puhutaanpa niistä hieman syvällisemmin.
Muistin käyttö ja tehokkuus
Yksi olennaisista mallin nopeuteen vaikuttavista tekijöistä on muistin käyttö yläpuolella tai MAO. Kuten alla olevasta kuvasta näkyy, useat muuntajan operaattorit, mukaan lukien elementtikohtainen lisäys, normalisointi ja toistuva uudelleenmuotoilu, ovat muistin kannalta tehottomia toimintoja, koska ne vaativat pääsyn eri muistiyksiköihin, mikä on aikaa vievä prosessi.
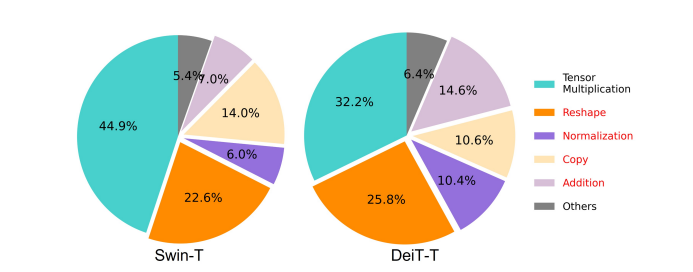
Vaikka on olemassa joitain olemassa olevia menetelmiä, jotka voivat yksinkertaistaa standardinmukaisia softmax-itsehuollon laskelmia, kuten matala-arvoinen approksimaatio ja harvat huomioarvot, ne tarjoavat usein rajoitetun kiihtyvyyden ja heikentävät tarkkuutta.
Toisaalta EfficientViT-kehyksen tavoitteena on alentaa muistin käyttökustannuksia vähentämällä muistia tehottomien kerrosten määrää viitekehyksessä. Malli skaalaa DeiT-T:n ja Swin-T:n pieniksi aliverkoiksi, joiden häiriöt ovat 1.25X ja 1.5X suuremmat, ja vertaa näiden aliverkkojen suorituskykyä MHSA-kerrosten suhteisiin. Kuten alla olevasta kuvasta näkyy, lähestymistapa parantaa MHSA-kerrosten tarkkuutta toteutettuna noin 20-40 %.

Laskentatehokkuus
MHSA-tasoilla on taipumus upottaa syöttösekvenssi useisiin aliavaruuksiin tai päihin, ja ne laskevat huomiokartat yksitellen, mikä on lähestymistapa, jonka tiedetään parantavan suorituskykyä. Huomiokartat eivät kuitenkaan ole laskennallisesti halpoja, ja laskennallisten kustannusten selvittämiseksi EfficientViT-mallissa tutkitaan, miten voidaan vähentää ylimääräistä huomiota pienemmissä ViT-malleissa. Malli mittaa kunkin pään ja jäljellä olevien päiden maksimaalisen kosinin samankaltaisuuden jokaisessa lohkossa harjoittelemalla leveyttä pienennettyjä DeiT-T- ja Swim-T-malleja 1.25-kertaisella päättelynopeudella. Kuten alla olevasta kuvasta voidaan havaita, huomiopäiden välillä on suuri määrä samankaltaisuutta, mikä viittaa siihen, että malliin liittyy laskennan redundanssia, koska useilla päillä on taipumus oppia samanlaiset projektiot tarkasta täydellisestä ominaisuudesta.

Kannustaakseen päitä oppimaan erilaisia malleja mallissa käytetään nimenomaisesti intuitiivista ratkaisua, jossa jokaiselle päälle syötetään vain osa koko ominaisuudesta, tekniikka, joka muistuttaa ryhmäkonvoluutioideaa. Malli kouluttaa eri näkökohtia alennettuihin malleihin, joissa on muokattuja MHSA-kerroksia.
Parametrien tehokkuus
Keskimääräiset ViT-mallit perivät suunnittelustrategiansa, kuten vastaavan leveyden käyttö projektioissa, laajennussuhteen asettaminen arvoon 4 FFN:ssä ja NLP-muuntajien nostaminen vaiheissa. Näiden komponenttien kokoonpanot on suunniteltava huolellisesti uudelleen kevyitä moduuleja varten. EfficientViT-malli käyttää Taylor-strukturoitua karsimista löytääkseen olennaiset komponentit Swim-T- ja DeiT-T-kerroksista automaattisesti ja tutkii tarkemmin taustalla olevia parametrien allokointiperiaatteita. Tietyissä resurssirajoituksissa karsintamenetelmät poistavat merkityksettömät kanavat ja säilyttävät kriittiset kanavat parhaan mahdollisen tarkkuuden varmistamiseksi. Alla olevassa kuvassa verrataan kanavien suhdetta tuloupotuksiin ennen ja jälkeen karsimisen Swin-T-kehyksessä. Havaittiin, että: Lähtötason tarkkuus: 79.1 %; karsittu tarkkuus: 76.5 %.

Yllä oleva kuva osoittaa, että kehyksen kaksi ensimmäistä vaihetta säilyttävät enemmän ulottuvuuksia, kun taas kaksi viimeistä vaihetta säilyttävät paljon vähemmän mittoja. Se saattaa tarkoittaa, että tyypillinen kanavakonfiguraatio, joka kaksinkertaistaa kanavan jokaisen vaiheen jälkeen tai käyttää vastaavia kanavia kaikille lohkoille, voi johtaa merkittävään redundanssiin muutamassa viimeisessä lohkossa.
Tehokas Vision Transformer: Arkkitehtuuri
Yllä olevan analyysin aikana saatujen oppien perusteella kehittäjät työskentelivät uuden hierarkkisen mallin luomiseksi, joka tarjoaa nopeat häiriönopeudet, TehokasViT malli. Katsotaanpa yksityiskohtaisesti EfficientViT-kehyksen rakennetta. Alla oleva kuva antaa sinulle yleiskuvan EfficientViT-kehyksestä.
EfficientViT-kehyksen rakennuspalikoita
Tehokkaamman näkömuuntajaverkon rakennuspalikka on kuvattu alla olevassa kuvassa.

Kehys koostuu peräkkäisestä ryhmähuomiomoduulista, muistitehokkaasta sandwich-asettelusta ja parametrien uudelleenallokointistrategiasta, jotka keskittyvät mallin tehokkuuden parantamiseen laskennan, muistin ja parametrien osalta. Puhutaanpa niistä tarkemmin.
Sandwich Layout
Malli käyttää uutta sandwich-asettelua tehokkaamman ja tehokkaamman muistilohkon rakentamiseen kehykselle. Sandwich-asettelu käyttää vähemmän muistiin sidottuja itsehuomiokerroksia ja käyttää muistitehokkaampia syöttöverkkoja kanavaviestintään. Tarkemmin sanottuna mallissa käytetään yhtä itsetarkkailukerrosta spatiaaliseen sekoitukseen, joka on kerrostettu FFN-kerrosten väliin. Suunnittelu ei ainoastaan auta vähentämään muistin ajankulutusta itsetarkkailukerrosten takia, vaan mahdollistaa myös tehokkaan viestinnän verkon eri kanavien välillä FFN-kerrosten käytön ansiosta. Malli käyttää myös ylimääräistä vuorovaikutusmerkkikerrosta ennen jokaista myötäkytkentäverkkokerrosta käyttämällä DWConv- tai Deceptive Convolution -konvoluutiota, ja parantaa mallin kapasiteettia ottamalla käyttöön paikallisen rakenneinformaation induktiivisen biasin.
Cascaded Group Huomio
Yksi MHSA-kerrosten suurimmista ongelmista on huomiopäiden redundanssi, mikä tekee laskennasta tehottomampaa. Ongelman ratkaisemiseksi malli ehdottaa CGA- tai Cascaded Group Attention for vision -muuntajia, uutta huomiomoduulia, joka saa inspiraationsa tehokkaiden CNN-verkkojen ryhmäkäänteistä. Tässä lähestymistavassa malli syöttää yksittäisiin päihin jaettuna täydet ominaisuudet ja hajottaa siksi huomiolaskennan nimenomaisesti päiden kesken. Ominaisuuksien jakaminen sen sijaan, että syöttäisi kaikki ominaisuudet jokaiseen päähän, säästää laskentaa ja tekee prosessista tehokkaamman, ja malli jatkaa työskentelyä tarkkuuden ja kapasiteetin parantamiseksi entisestään rohkaisemalla tasoja oppimaan ennusteita ominaisuuksista, joilla on enemmän tietoa.

Parametrien uudelleenallokointi
Parametrien tehokkuuden parantamiseksi malli kohdistaa parametrit uudelleen verkossa laajentamalla kriittisten moduulien kanavan leveyttä ja pienentämällä vähemmän tärkeiden moduulien kanavan leveyttä. Taylor-analyysin perusteella malli joko asettaa pienet kanavamitat projektioille kussakin vaiheessa jokaisessa vaiheessa tai malli sallii projektioiden olla samat kuin tulon. Syöttöverkon laajennussuhde lasketaan myös 2:een neljästä sen parametrien redundanssin helpottamiseksi. Ehdotettu uudelleenallokointistrategia, jonka EfficientViT-kehys toteuttaa, varaa enemmän kanavia tärkeille moduuleille, jotta ne voivat oppia esityksiä korkean ulottuvuuden tilassa paremmin, mikä minimoi ominaisuustietojen menetyksen. Lisäksi häiriöprosessin nopeuttamiseksi ja mallin tehokkuuden parantamiseksi entisestään malli poistaa automaattisesti tarpeettomat parametrit merkityksettömistä moduuleista.

EfficientViT-kehyksen yleiskatsaus voidaan selittää yllä olevassa kuvassa, jossa osat,
- EfficientViT:n arkkitehtuuri,
- Sandwich Layout lohko,
- Cascaded Group Huomio.
EfficientViT: Verkkoarkkitehtuurit

Yllä oleva kuva esittää yhteenvedon EfficientViT-kehyksen verkkoarkkitehtuurista. Malli esittelee päällekkäisen korjaustiedoston [20,80], joka upottaa 16 × 16 korjaustiedostoa C1-ulottuvuuden tunnuksiin, mikä parantaa mallin kykyä suoriutua paremmin matalan tason visuaalisen esityksen oppimisessa. Mallin arkkitehtuuri koostuu kolmesta vaiheesta, joissa jokainen vaihe pinoaa ehdotetut EfficientViT-kehyksen rakennuspalikat, ja tokenien lukumäärä kussakin alinäytteenottokerroksessa (resoluution 2x alinäytteenotto) pienenee 4X. Alinäytteistyksen tehostamiseksi malli ehdottaa alinäytteenottolohkoa, jossa on myös ehdotettu sandwich-asettelu sillä poikkeuksella, että käänteinen jäännöslohko korvaa huomiokerroksen informaation menetyksen vähentämiseksi näytteenoton aikana. Lisäksi mallissa käytetään perinteisen LayerNorm(LN) sijaan BatchNorm(BN):tä, koska BN voidaan taittaa edeltäviin lineaarisiin tai konvoluutiokerroksiin, mikä antaa sille ajonaikaisen edun LN:ään verrattuna.
EfficientViT-malliperhe
EfficientViT-malliperhe koostuu 6 mallista, joissa on eri syvyys- ja leveysasteikot, ja jokaiselle vaiheelle on varattu tietty määrä päitä. Mallit käyttävät alkuvaiheessa vähemmän lohkoja verrattuna loppuvaiheisiin, mikä on samanlainen kuin MobileNetV3-kehys, koska varhaisen vaiheen prosessointi suuremmilla resoluutioilla on aikaa vievää. Leveyttä kasvatetaan vaiheittain pienellä tekijällä redundanssin vähentämiseksi myöhemmissä vaiheissa. Alla olevassa taulukossa on EfficientViT-malliperheen arkkitehtoniset tiedot, joissa C, L ja H viittaavat leveyteen, syvyyteen ja päiden lukumäärään tietyssä vaiheessa.

EfficientViT: Mallin toteutus ja tulokset
EfficientViT-mallin kokonaiseräkoko on 2,048 300, se on rakennettu Timm & PyTorchilla, se on opetettu tyhjästä 8 jaksoa käyttämällä 100 Nvidia V1 GPU:ta, käyttää kosinioppimisnopeuden ajoitinta, AdamW-optimointiohjelmaa ja suorittaa kuvien luokittelukokeilunsa ImageNetissä. -224K. Syötekuvat rajataan satunnaisesti ja niiden kokoa muutetaan 224 × 300 -resoluutioon. Kokeissa, joihin liittyy kuvan alavirran luokittelu, EfficientViT-kehys hienosäätää mallia 256 aikakaudelle ja käyttää AdamW-optimoijaa, jonka eräkoko on 12. Malli käyttää RetineNetiä kohteen havaitsemiseen COCO:ssa ja jatkaa mallien kouluttamiseen XNUMX lisäjaksolle. aikakaudet samoilla asetuksilla.
Tulokset ImageNetissä
EfficientViT:n suorituskyvyn analysoimiseksi sitä verrataan nykyisiin ViT- ja CNN-malleihin ImageNet-tietojoukossa. Vertailun tulokset on raportoitu seuraavassa kuvassa. Kuten voidaan nähdä, EfficientViT-malliperhe ylittää useimmissa tapauksissa nykyiset puitteet ja onnistuu saavuttamaan ihanteellisen kompromissin nopeuden ja tarkkuuden välillä.

Vertailu tehokkaisiin CNN:ihin ja tehokkaisiin ViT:eihin
Malli vertaa ensin suorituskykyään Efficient CNN -verkkoihin, kuten EfficientNet, ja vanilja-CNN-kehyksiin, kuten MobileNets. Kuten voidaan nähdä, verrattuna MobileNet-kehyksiin, EfficientViT-mallit saavat paremman top-1-tarkkuuspisteen, kun taas ne toimivat 3.0X ja 2.5X nopeammin Intel-suorittimella ja V100 GPU:lla.
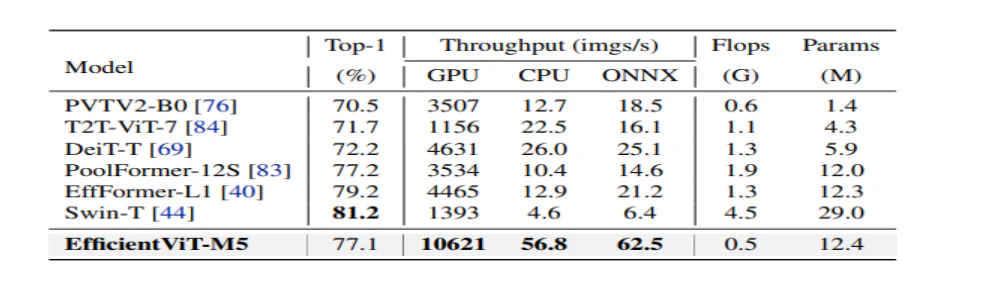
Yllä olevassa kuvassa verrataan EfficientViT-mallin suorituskykyä uusimpiin suuriin ViT-malleihin, jotka toimivat ImageNet-1K-tietojoukossa.
Alavirran kuvan luokittelu
EfficientViT-mallia sovelletaan erilaisiin alavirran tehtäviin mallin siirtämisoppimiskykyjen tutkimiseen ja alla oleva kuva tiivistää kokeen tulokset. Kuten voidaan havaita, EfficientViT-M5-malli onnistuu saavuttamaan parempia tai vastaavia tuloksia kaikissa tietosarjoissa säilyttäen samalla paljon korkeamman suorituskyvyn. Ainoa poikkeus on Cars-tietojoukko, jossa EfficientViT-malli ei toimita tarkkuutta.

Objektin tunnistus
EfficientViT:n esineiden havaitsemiskyvyn analysoimiseksi sitä verrataan tehokkaisiin malleihin COCO-objektien tunnistustehtävässä, ja alla olevassa kuvassa on yhteenveto vertailun tuloksista.

Loppuajatukset
Tässä artikkelissa olemme puhuneet EfficientViT:stä, nopean näkömuuntajamallien perheestä, joka käyttää peräkkäistä ryhmähuomiota ja tarjoaa muistitehokkaita toimintoja. Laajat kokeet, jotka on suoritettu EfficientViT:n suorituskyvyn analysoimiseksi, ovat osoittaneet lupaavia tuloksia, sillä EfficientViT-malli ylittää useimmissa tapauksissa nykyiset CNN- ja näkömuuntajamallit. Olemme myös yrittäneet antaa analyysin tekijöistä, jotka vaikuttavat näkömuuntajien häiriönopeuteen.















