
Tekoäly
Deepfake-ilmaisimet tavoittelevat uutta maaperää: piileviä diffuusiomalleja ja GAN-verkkoja

Lausunto Viime aikoina syvän väärennösten havaitsemisen tutkimusyhteisö, joka on vuoden 2017 lopusta lähtien ollut lähes yksinomaan automaattinen kooderi-pohjainen kehys, joka sai tuolloin ensiesityksensä niin suurella yleisön kunnioituksella (ja kauhistunut), on alkanut kiinnostua vähemmän pysähtyneistä arkkitehtuureista, mukaan lukien piilevä diffuusio malleja, kuten DALL-E2 ja Vakaa diffuusiosekä GAN-verkkojen (Generative Adversarial Networks) tuotos. Esimerkiksi kesäkuussa, UC Berkeley julkaisi tulokset tutkimuksestaan ilmaisimen kehittämiseksi tuolloin hallitsevan DALL-E 2:n lähtöön.
Kasvavaa kiinnostusta näyttää ohjaavan äkillinen evoluutiohyppy latenttien diffuusiomallien kapasiteetissa ja saatavuudessa vuonna 2022 suljetun lähdekoodin ja rajoitetun pääsyn kanssa. vapauta DALL-E 2:sta keväällä, jota seuraa loppukesällä sensaatiomainen avointa lähdettä stabiilin diffuusion stabiilisuus.ai.
GANeja on myös ollut pitkään opiskellut tässä yhteydessä, vaikkakin vähemmän intensiivisesti, koska se on hyvin vaikea käyttää niitä ihmisten vakuuttaviin ja yksityiskohtaisiin videopohjaisiin harrastuksiin; ainakin verrattuna tähän mennessä arvostettuihin autoenkooderipaketteihin, kuten kasvojen vaihto ja DeepFaceLab – ja jälkimmäisen suoratoistona toimiva serkku, DeepFaceLive.
Liikkuvat kuvat
Kummassakin tapauksessa galvanointitekijä näyttää olevan myöhemmän kehityssprintin mahdollisuus video- synteesi. Lokakuun alkua – ja vuoden 2022 suurta konferenssikautta – leimasi äkillisten ja odottamattomien ratkaisujen lumivyöry erilaisiin pitkäaikaisiin videosynteesivirheisiin: Facebookilla oli pian julkaistuja näytteitä omasta tekstistä videoksi -alustaan, mutta Google Research tukahdutti nopeasti tämän alkuperäisen suosion julkistamalla uuden Imagen-to-Video T2V -arkkitehtuurinsa, joka pystyy tulostamaan korkearesoluutioisia kuvamateriaalia (tosin vain 7-kerroksisen skaalaajien verkoston kautta).
Jos uskot, että tämänkaltaiset asiat tulevat kolminkertaisiksi, harkitse myös stability.ai:n arvoituksellinen lupaus, että "video on tulossa" Stable Diffusionille, ilmeisesti myöhemmin tänä vuonna, kun taas Stable Diffusion -kehittäjä Runway on teki samanlaisen lupauksen, vaikka on epäselvää, viittaavatko ne samaan järjestelmään. The Discord viesti Vakauden toimitusjohtaja Emad Mostaque lupasi myös "ääni, video [ja] 3d".
Entäpä monien uusien out-of-the-blue-tarjonta äänen sukupolven puitteet (jotkut perustuvat piilevään diffuusioon) ja uusi diffuusiomalli, joka voi tuottaa aito hahmoliike, ajatus siitä, että "staattiset" kehykset, kuten GAN-liittimet ja diffuusorit, ottavat vihdoin paikkansa tukina. lisäaineet ulkoiset animaatiokehykset alkavat saada todellista vetovoimaa.
Lyhyesti sanottuna näyttää todennäköiseltä, että autoenkooderiin perustuvien videon syväväärennösten maailma, joka voi tehokkaasti korvata kasvojen keskiosa, saattaa tähän aikaan ensi vuonna peittää uuden sukupolven diffuusiopohjaiset syväväärennösteknologiat – suosittuja, avoimen lähdekoodin lähestymistapoja, joilla on mahdollisuus väärentää fotorealistisesti kokonaisten kehojen lisäksi kokonaisia kohtauksia.
Tästä syystä ehkä deepfake-tutkijayhteisö alkaa ottamaan kuvasynteesiä vakavasti ja ymmärtämään, että se voi palvella muutakin tarkoitusta kuin vain tuottaa väärennettyjä LinkedIn-profiilikuvia; ja jos kaikki heidän vaikeaselkoiset piilevät tilat, jotka voivat saavuttaa ajallisen liikkeen suhteen, on toimii todella loistavana tekstuurin hahmontajana, se voi itse asiassa olla enemmän kuin tarpeeksi.
Blade Runner
Kaksi viimeisintä paperia, joissa käsitellään piilevää diffuusiota ja GAN-pohjaista syväväärennösten havaitsemista, ovat vastaavasti DE-FAKE: Tekstistä kuvaksi diffuusiomallien luomien väärennettyjen kuvien havaitseminen ja osoittaminen, yhteistyö CISPA Helmholtz Center for Information Security and Salesforcen välillä; ja BLADERUNNER: nopea vastatoimi synteettisille (AI-generoiduille) StyleGAN-kasvoille, Adam Dorian Wongilta MIT:n Lincolnin laboratoriosta.
Ennen uuden menetelmänsä selittämistä jälkimmäinen artikkeli vie jonkin aikaa tutkiakseen aiempia lähestymistapoja sen määrittämiseksi, onko GAN luonut kuvan vai ei (paperi käsittelee erityisesti NVIDIAn StyleGAN-perhettä).
"Brady Bunch" -menetelmä – ehkä a merkityksetön viittaus kaikille, jotka eivät katsoneet televisiota 1970-luvulla tai jotka eivät osanneet nähdä 1990-luvun elokuvasovituksia – tunnistaa GAN-väärennössisällön niiden kiinteiden paikkojen perusteella, joissa tietyt GAN-kasvojen osat ovat varmasti omissa paikoissa. 'tuotantoprosessi'.

SANS-instituutin webcastin vuonna 2022 esittämä Brady Bunch -menetelmä: GAN-pohjainen kasvogeneraattori suorittaa tietyissä tapauksissa epätodennäköisen tasaisen sijoittelun tietyille kasvonpiirteille, mikä vääristää valokuvan alkuperän. Lähde: https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
Toinen hyödyllinen tunnettu osoitus on StyleGANin toistuva kyvyttömyys renderöidä useita kasvoja (ensimmäinen kuva alla) tarvittaessa, samoin kuin sen lahjakkuuden puute tarvikkeiden koordinoinnissa (keskimmäinen kuva alla) ja taipumus käyttää hiusrajaa improvisoinnin alkuna. hattu (kolmas kuva alla).

Kolmas menetelmä, johon tutkija kiinnittää huomiota, on valokuvan peittokuva (josta esimerkki löytyy kohdasta elokuun artikkelissamme mielenterveyshäiriöiden tekoälyavusteisesta diagnosoinnista), joka käyttää kompositiollisia "kuvansekoitusohjelmistoja", kuten CombineZ-sarjaa, yhdistämään useita kuvia yhdeksi kuvaksi, mikä paljastaa usein rakenteen taustalla olevat yhteiset piirteet – mahdollinen osoitus synteesistä.

Uudessa asiakirjassa ehdotettu arkkitehtuuri on otsikoitu (mahdollisesti vastoin kaikkia SEO-neuvoja) Blade Runner, viitaten Voight-Kampff-testi joka määrittää, ovatko scifi-franchisingin antagonistit "väärennettyjä" vai eivät.
Liukuputki koostuu kahdesta vaiheesta, joista ensimmäinen on PapersPlease-analysaattori, joka voi arvioida tietoja, jotka on kerätty tunnetuilta GAN-face-sivustoilta, kuten thispersondoesnotexist.com tai generated.photos.

Vaikka koodin supistettu versio voidaan tarkastaa GitHubissa (katso alla), tästä moduulista annetaan muutamia yksityiskohtia, paitsi että OpenCV ja DLIB käytetään kasvojen rajaamiseen ja havaitsemiseen kerätystä materiaalista.
Toinen moduuli on Keskuudessamme ilmaisin. Järjestelmä on suunniteltu etsimään koordinoitua silmien sijoittelua valokuvista, joka on StyleGANin kasvojen ulostulon jatkuva ominaisuus, joka on tyypillistä yllä kuvatulle "Brady Bunch" -skenaariolle. amongUs saa virtansa tavallisesta 68 maamerkin tunnistimesta.

Kasvopisteen huomautukset Intelligent Behavior Understanding Groupin (IBUG) kautta, jonka kasvojen maamerkkipiirroskoodia käytetään Blade Runner -paketissa.
WithoutUs riippuu valmiiksi koulutetuista maamerkeistä, jotka perustuvat PapersPleasen tunnettuihin "Brady bunch" -koordinaatteihin, ja se on tarkoitettu käytettäväksi StyleGAN-pohjaisten kasvokuvien reaaliaikaisissa, verkkoon päin olevissa näytteissä.
Blade Runner, kirjoittaja ehdottaa, on plug-and-play -ratkaisu, joka on tarkoitettu yrityksille tai organisaatioille, joilla ei ole resursseja kehittää talon sisäisiä ratkaisuja tässä käsitellyn syvän väärennösten havaitsemiseen sekä "stop-gap-toimenpide, jolla voi ostaa aikaa" pysyvämpiä vastatoimia”.
Itse asiassa tällä epävakaalla ja nopeasti kasvavalla turvallisuusalalla ei ole paljon räätälöityjä or valmiita pilvitoimittajaratkaisuja, joihin aliresurssoitu yritys voi tällä hetkellä kääntyä luottavaisin mielin.
Vaikka Blade Runner pelaa huonosti vastaan silmälasillinen StyleGAN- väärennetyt ihmiset, tämä on suhteellisen yleinen ongelma samankaltaisissa järjestelmissä, jotka odottavat pystyvänsä arvioimaan silmien rajauksia keskeisinä viitepisteinä, jotka jäävät tällaisissa tapauksissa hämärään.
Blade Runnerista on tehty supistettu versio julkaistu avoimeen lähdekoodiin GitHubissa. On olemassa monipuolisempi oma versio, joka voi käsitellä useita valokuvia yhden valokuvan sijaan avoimen lähdekoodin arkiston toimintoa kohden. Kirjoittaja aikoo hänen mukaansa päivittää GitHub-version lopulta samaan standardiin, kun aika sallii. Hän myöntää myös, että StyleGAN todennäköisesti kehittyy tunnettujen tai nykyisten heikkouksiensa ulkopuolelle, ja ohjelmiston on samoin kehitettävä rinnakkain.
DE-FAKE
DE-FAKE-arkkitehtuurin tavoitteena ei ole ainoastaan saavuttaa "yleistä tunnistusta" kuville, jotka on tuotettu tekstistä kuvaksi diffuusiomalleilla, vaan tarjota menetelmä erottaa joka latentti diffuusio (LD) malli tuotti kuvan.
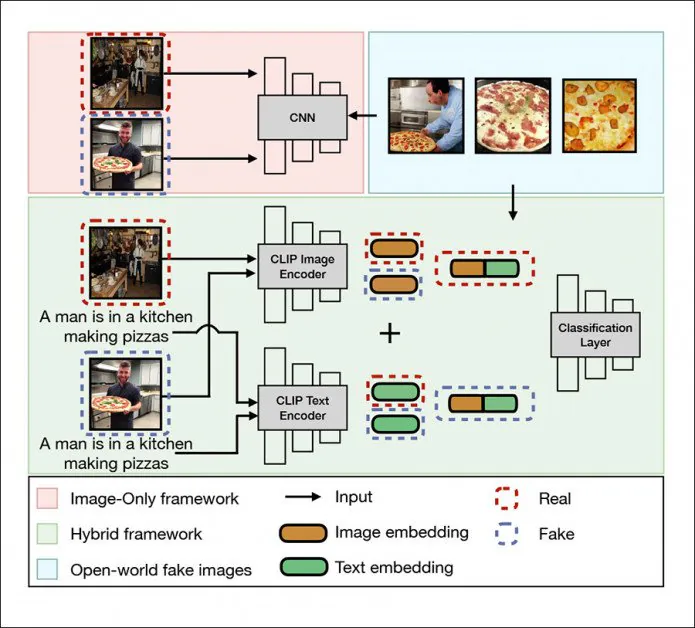
DE-FAKE:n yleinen tunnistuskehys koskee paikallisia kuvia, hybridikehystä (vihreä) ja avoimen maailman kuvia (sininen). Lähde: http://export.arxiv.org/pdf/2210.06998
Rehellisesti sanottuna tämä on tällä hetkellä melko helppo tehtävä, koska kaikilla suosituilla LD-malleilla – suljetuilla tai avoimella lähdekoodilla – on huomattavia erottuvia ominaisuuksia.
Lisäksi useimmat jakavat joitain yhteisiä heikkouksia, kuten taipumus leikata päät pois, koska mielivaltaisella tavalla että ei-neliön muotoiset verkkoon kaavitut kuvat syötetään massiivisiin tietojoukkoon, jotka virtaavat järjestelmät, kuten DALL-E 2, Stable Diffusion ja MidJourney:

Piilevät diffuusiomallit, kuten kaikki tietokonenäkömallit, vaativat neliömuotoisen syötteen; mutta LAION5B-tietojoukkoa ruokkiva web-kaappaus ei tarjoa mitään "ylellisiä lisäominaisuuksia", kuten kykyä tunnistaa kasvot (tai mihin tahansa muuhun) ja keskittyä niihin, ja katkaisee kuvat melko raa'asti sen sijaan, että ne täyttäisivät ne pois (mikä säilyttäisi koko lähteen kuva, mutta pienemmällä resoluutiolla). Kun nämä "viljelykasvit" on koulutettu, ne normalisoituvat, ja niitä esiintyy hyvin usein piilevien diffuusiojärjestelmien, kuten stabiilin diffuusion, ulostulossa. Lähteet: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac ja Stable Diffusion.
DE-FAKEn on tarkoitus olla algoritmiagnostikko, autoencoder anti-deepfake -tutkijoiden pitkään vaalittu tavoite ja tällä hetkellä melko saavutettavissa oleva tavoite LD-järjestelmien suhteen.
Arkkitehtuuri käyttää OpenAI:n Contrastive Language-Image Pretraining -tekniikkaa (CLIP) multimodaalinen kirjasto – olennainen osa vakaata diffuusiota, ja siitä on tulossa nopeasti uuden kuva-/videosynteesijärjestelmien aallon sydän – keinona poimia upotuksia "taotetuista" LD-kuvista ja kouluttaa luokittelija havaittujen kuvioiden ja luokkien perusteella.
"Mustassa laatikossa" -skenaariossa, jossa PNG-palat, jotka sisältävät tietoja generointiprosessista, on jo pitkään poistettu pois latausprosessien ja muista syistä, tutkijat käyttävät Salesforcea. BLIP-kehys (myös komponentti ainakin yksi Stable Diffusion -jakelu) 'sokeasti' kyselyyn kuvista niiden luoneiden kehotteiden todennäköisen semanttisen rakenteen.

Tutkijat käyttivät stabiilia diffuusiota, latenttia diffuusiota (joka on erillinen tuote), GLIDEä ja DALL-E 2:ta täydentämään koulutus- ja testausaineistoa, joka hyödyntää MSCOCO:ta ja Flickr30k:ta.
Normaalisti tarkastelemme melko laajasti tutkijoiden kokeiden tuloksia uuden viitekehyksen luomiseksi; mutta itse asiassa DE-FAKEn havainnot näyttävät todennäköisesti olevan hyödyllisempiä tulevaisuuden vertailukohtana myöhempiä iteraatioita ja vastaavia projekteja varten sen sijaan, että ne olisivat merkityksellisiä projektin onnistumisen mittareita, kun otetaan huomioon epävakaa ympäristö, jossa se toimii, ja järjestelmä, jossa se toimii. Lehden kokeissa kilpaileva on lähes kolme vuotta vanha – ajalta, jolloin kuvasynteesikohtaus oli todella syntymässä.

Kaksi vasemmanpuoleista kuvaa: "haastettu" aiempi kehys, joka syntyi vuonna 2019, menestyi ennustettavasti huonommin DE-FAKEa (kaksi oikeanpuoleista kuvaa) vastaan neljässä testatussa LD-järjestelmässä.
Ryhmän tulokset ovat ylivoimaisesti positiivisia kahdesta syystä: aikaisempaa työtä on vähän verrattaessa (eikä yhtään sellaista, joka tarjoaisi reilun vertailun, eli joka kattaisi vain kaksitoista viikkoa siitä, kun Stable Diffusion julkaistiin avoimeen lähdekoodiin).
Toiseksi, kuten edellä mainittiin, vaikka LD-kuvan synteesikenttä kehittyy eksponentiaalisella nopeudella, nykyisten tarjousten lähtösisältö merkitsee itseään tehokkaasti vesileimoimalla omia rakenteellisia (ja hyvin ennustettavia) puutteitaan ja epäkeskisuuksiaan – joista monet todennäköisesti korjataan. Stable Diffusionin tapauksessa ainakin vapauttamalla paremmin toimiva 1.5 tarkistuspiste (eli 4 Gt:n koulutettu malli, joka antaa virtaa järjestelmään).
Samaan aikaan Stability on jo ilmoittanut, että sillä on selkeä tiekartta järjestelmän V2:lle ja V3:lle. Ottaen huomioon viimeisten kolmen kuukauden uutisotsikoita herättävät tapahtumat, kaikki OpenAI:n ja muiden kilpailevien toimijoiden aiheuttama yritystorpor kuvasynteesitilassa on todennäköisesti haihtunut, mikä tarkoittaa, että voimme odottaa yhtä ripeää kehitystä myös suljetun lähdekoodin kuvasynteesitila.
Julkaistu ensimmäisen kerran 14.















