
Nopea suunnittelu
ChatGPT ja Advanced Prompt Engineering: AI Evolutionin ohjaaminen

OpenAI on auttanut kehittämään vallankumouksellisia työkaluja, kuten OpenAI Gym, joka on suunniteltu harjoitusvahvistusalgoritmeille, ja GPT-n-malleja. Valokeilassa on myös DALL-E, tekoälymalli, joka luo kuvia tekstisyötteistä. Yksi tällainen malli, joka on kerännyt huomattavaa huomiota, on OpenAI ChatGPT, loistava esimerkki suurten kielimallien alalla.
GPT-4: Prompt Engineering
ChatGPT on muuttanut chatbot-maisemaa tarjoamalla ihmisen kaltaisia vastauksia käyttäjien syötteisiin ja laajentamalla sovelluksiaan eri aloilla – ohjelmistokehityksestä ja testauksesta yritysviestintään ja jopa runojen luomiseen.
Yritysten ja yksityishenkilöiden käsissä esimerkiksi GPT-4 voisi toimia ehtymättömänä tietovarastona, joka olisi taitava aineista matematiikasta ja biologiasta oikeustieteisiin. Tällaiset kehittyneet ja helppokäyttöiset tekoälymallit ovat valmiita määrittelemään uudelleen työn, oppimisen ja luovuuden tulevaisuuden.

Generatiiviset mallit, kuten GPT-4, voivat tuottaa uutta tietoa olemassa olevien syötteiden perusteella. Tämän erottavan ominaisuuden avulla he voivat suorittaa erilaisia tehtäviä, mukaan lukien tekstin, kuvien, musiikin ja videoiden luomisen.
ChatGPT- ja OpenAI-mallien yhteydessä kehote on syöte, jonka käyttäjät antavat malleille, yleensä tekstin muodossa. Kehotteet toimivat ensisijaisena keinona hallita näiden mallien tuottamaa tulosta, mikä tekee niistä ratkaisevan tärkeitä onnistuneille ja olennaisille keskusteluille.
Nopean laadun vaikutus
Hyvin määriteltyjen kehotteiden käyttäminen on avain hyödyllisiin ja merkityksellisiin keskusteluihin tekoälyjärjestelmien kanssa. Huonosti määritellyt kehotteet voivat johtaa tulokseen, josta ei ole hyötyä käyttäjälle, ja ne voivat jopa johtaa harhaanjohtavaan sisältöön.
Havainnollistaaksesi kehotteen laadun vaikutusta, verrataan kahta erilaista ChatGPT:lle annettua kehotetta. Ensimmäinen kehote, huonosti määritelty ja olettaa aiempaa tietoa, tuottaa käyttäjälle mahdollisesti hyödyttömän vastauksen. Toisaalta toinen kehote tarjoaa enemmän kontekstia ja esimerkkejä, mikä varmistaa osuvamman ja ymmärrettävämmän vastauksen.
Kysely 1: "Kerro minulle konvoluutiohermoverkoista."
Vastaus 1: "Konvoluutiohermoverkot (CNN) ovat monikerroksisia perceptroniverkkoja, jotka koostuvat täysin yhdistetyistä kerroksista ja yhdistävistä kerroksista. Niitä käytetään yleisesti kuvantunnistustehtävissä. Prosessi sisältää suodattimien käyttämisen syötettyihin kuviin ja niiden pienentämisen yhdistämällä tasoja."
Kysely 2: "Haluan oppia konvoluutiohermoverkoista, mutta minulla ei ole aiempaa tietoa keinotekoisista hermoverkoista. Voitko antaa aloittelijaystävällisen selityksen ja esimerkin siitä, kuinka CNN:itä käytetään kuvantunnistuksessa?"
Vastaus 2: "Konvoluutiohermoverkot (CNN) ovat eräänlainen hermoverkko, jota käytetään ensisijaisesti kuvantunnistustehtäviin. Toisin kuin muut hermoverkot, ne hyödyntävät konvoluutiokerroksia ja yhdistäviä kerroksia kuvien käsittelyyn. Kuvittele, että sinulla on kuva kissasta. CNN:t voivat tunnistaa kuvan eri piirteitä, kuten viikset, korvat ja hännän, käyttämällä suodattimia ja pienentämällä kuvan näytteistystä yhdistämällä tasoja. Tämä prosessi tekee CNN:istä erittäin tehokkaita kuvien kohteiden tunnistamisessa."
Vertaamalla näitä kahta vastausta on selvää, että hyvin määritelty kehote johtaa asiaankuuluvampaan ja käyttäjäystävällisempään vastaukseen. Nopea suunnittelu ja suunnittelu ovat kasvavia tieteenaloja, joiden tavoitteena on optimoida ChatGPT:n kaltaisten AI-mallien tulostuslaatu.
Tämän artikkelin seuraavissa osissa perehdymme laajojen kielimallien (LLM) jalostukseen tarkoitettujen edistyneiden menetelmien, kuten nopean suunnittelutekniikan ja taktiikoiden, alueeseen. Näitä ovat muutaman kuvan oppiminen, ReAct, ajatusketju, RAG ja paljon muuta.
Kehittyneet suunnittelutekniikat
Ennen kuin jatkamme, on tärkeää ymmärtää LLM:ien keskeinen ongelma, jota kutsutaan "hallusinaatioiksi". LLM:ien kontekstissa "hallusinaatiot" merkitsevät näiden mallien taipumusta tuottaa tuloksia, jotka saattavat tuntua kohtuullisilta, mutta jotka eivät ole juurtuneet tosiasialliseen todellisuuteen tai annettuun syöttökontekstiin.
Tämä ongelma korostettiin voimakkaasti äskettäisessä oikeusjutussa, jossa puolustusasianajaja käytti ChatGPT juridista tutkimusta varten. Tekoälytyökalu, joka horjui hallusinaatioongelmansa vuoksi, viittasi olemattomiin oikeustapauksiin. Tällä virheellä oli merkittäviä seurauksia, mikä aiheutti hämmennystä ja heikensi uskottavuutta menettelyn aikana. Tämä tapaus on jyrkkä muistutus siitä, että tekoälyjärjestelmien "hallusinaatioihin" on puututtava kiireellisesti.
Nopeiden suunnittelutekniikoiden tutkimisemme tavoitteena on parantaa näitä LLM:ien näkökohtia. Parannamme niiden tehokkuutta ja turvallisuutta tasoittelemme tietä innovatiivisille sovelluksille, kuten tiedon talteenotolle. Lisäksi se avaa ovet LLM-yritysten saumaiseen integrointiin ulkoisten työkalujen ja tietolähteiden kanssa, mikä laajentaa niiden mahdollisia käyttötarkoituksia.
Nolla- ja harvoin oppiminen: Optimointi esimerkkien avulla
Generative Pretraained Transformers (GPT-3) oli tärkeä käännekohta generatiivisten tekoälymallien kehittämisessä, koska se esitteli käsitteen "muutaman laukauksen oppiminen.' Tämä menetelmä oli pelin muuttaja, koska se pystyi toimimaan tehokkaasti ilman kattavaa hienosäätöä. GPT-3-kehystä käsitellään asiakirjassa "Kielimallit ovat vain harvoja oppijoita", jossa kirjoittajat osoittavat, kuinka malli toimii erinomaisesti erilaisissa käyttötapauksissa ilman, että tarvitaan mukautettuja tietojoukkoja tai koodia.
Toisin kuin hienosäätö, joka vaatii jatkuvaa ponnistelua vaihtelevien käyttötapausten ratkaisemiseksi, muutaman otoksen mallit osoittavat helpommin mukautettavissa laajempaan sovellusvalikoimaan. Vaikka hienosäätö saattaa joissain tapauksissa tarjota vankkoja ratkaisuja, se voi olla mittakaavassa kallista, mikä tekee muutaman otoksen mallien käytöstä käytännöllisemmän lähestymistavan, varsinkin kun se on integroitu nopeaan suunnitteluun.
Kuvittele, että yrität kääntää englantia ranskaksi. Muutaman otoksen oppimisessa tarjoat GPT-3:lle muutamia käännösesimerkkejä, kuten "merisaukko -> loutre de mer". GPT-3, joka on edistynyt malli, pystyy jatkossakin tarjoamaan tarkkoja käännöksiä. Nolla-shot-oppimisessa et antaisi esimerkkejä, ja GPT-3 pystyisi silti kääntämään englannin ranskaksi tehokkaasti.
Termi "harvojen oppiminen" tulee ajatuksesta, että mallille annetaan rajoitettu määrä esimerkkejä, joista "oppia". On tärkeää huomata, että "oppiminen" ei tässä yhteydessä tarkoita mallin parametrien tai painojen päivittämistä, vaan se vaikuttaa mallin suorituskykyyn.

GPT-3-paperissa esitelty vähän oppimista
Nolla-shot-oppiminen vie tämän konseptin askeleen pidemmälle. Nolla-shot-oppimisessa mallissa ei ole esimerkkejä tehtävien suorittamisesta. Mallin odotetaan toimivan hyvin sen alkukoulutuksen perusteella, mikä tekee tästä menetelmästä ihanteellisen avoimen verkkotunnuksen kysymysvastausskenaarioihin, kuten ChatGPT:hen.
Monissa tapauksissa malli, joka on taitava nollasta oppimiseen, voi toimia hyvin, kun sille tarjotaan muutaman otoksen tai jopa yksittäisen otoksen esimerkkejä. Tämä kyky vaihtaa nolla-, yksittäis- ja muutaman otoksen oppimisskenaarioiden välillä korostaa suurten mallien mukautumiskykyä ja parantaa niiden mahdollisia sovelluksia eri aloilla.
Nolla-oppimismenetelmistä on tulossa yhä yleisempiä. Näille menetelmille on tunnusomaista niiden kyky tunnistaa koulutuksen aikana näkymättömiä esineitä. Tässä on käytännön esimerkki Few-Shot Promptista:
"Translate the following English phrases to French:
'sea otter' translates to 'loutre de mer'
'sky' translates to 'ciel'
'What does 'cloud' translate to in French?'"
Tarjoamalla mallille muutama esimerkki ja esittämällä sitten kysymyksen voimme ohjata mallia tehokkaasti luomaan haluttu tulos. Tässä tapauksessa GPT-3 todennäköisesti kääntäisi oikein sanan "pilvi" ranskaksi "nuage".
Tutustumme tarkemmin nopean suunnittelun eri vivahteisiin ja sen keskeiseen rooliin mallin suorituskyvyn optimoinnissa päättelyn aikana. Tarkastellaan myös, kuinka sitä voidaan käyttää tehokkaasti kustannustehokkaiden ja skaalautuvien ratkaisujen luomiseen useissa eri käyttötapauksissa.
Kun tutkimme edelleen GPT-mallien nopeiden suunnittelutekniikoiden monimutkaisuutta, on tärkeää korostaa viimeistä viestiämme "Tärkeä opas nopeaan suunnitteluun ChatGPT:ssä'. Tämä opas tarjoaa käsityksiä strategioista, joilla AI-malleja ohjataan tehokkaasti lukemattomissa käyttötapauksissa.
Aiemmissa keskusteluissamme syventyimme suurten kielimallien (LLM) perustavanlaatuisiin kehotusmenetelmiin, kuten nolla- ja muutaman laukauksen oppimiseen, sekä ohjekehotuksiin. Näiden tekniikoiden hallitseminen on ratkaisevan tärkeää, jotta voit navigoida nopean suunnittelun monimutkaisemmissa haasteissa, joita tutkimme täällä.
Harva oppiminen voi olla rajoitettu useimpien LLM:ien rajoitetun kontekstin vuoksi. Lisäksi ilman asianmukaisia suojatoimia LLM:t voidaan johtaa harhaan tuottamaan mahdollisesti haitallisia tuloksia. Lisäksi monet mallit kamppailevat päättelytehtävien tai monivaiheisten ohjeiden noudattamisen kanssa.
Nämä rajoitteet huomioon ottaen haasteena on saada LLM:t selviytymään monimutkaisista tehtävistä. Ilmeinen ratkaisu voisi olla kehittyneempien LLM-yritysten kehittäminen tai olemassa olevien hiominen, mutta se voi vaatia huomattavia ponnisteluja. Joten herää kysymys: kuinka voimme optimoida nykyiset mallit parempaa ongelmanratkaisua varten?
Yhtä kiehtovaa on tutkia, kuinka tämä tekniikka liittyy luoviin sovelluksiin Unite AI: ssa.Tekoälytaiteen hallitseminen: Tiivis opas keskimatkaan ja nopeaan suunnitteluun', joka kuvaa kuinka taiteen ja tekoälyn fuusio voi johtaa kunnioitusta herättävään taiteeseen.
Ajatusketjun kehotus
Ajatusketjun kehotus hyödyntää suurten kielimallien (LLM) luontaisia autoregressiivisiä ominaisuuksia, jotka ovat erinomaisia tietyn sekvenssin seuraavan sanan ennustamisessa. Kehottamalla mallia selvittämään ajatteluprosessiaan, se saa aikaan perusteellisemman, järjestelmällisemmän ideoiden generoinnin, joka pyrkii olemaan tiiviisti linjassa tarkan tiedon kanssa. Tämä kohdistus johtuu mallin taipumuksesta käsitellä ja välittää tietoa harkitusti ja järjestyneellä tavalla, kuten ihmisasiantuntija kävelee kuuntelijan läpi monimutkaisen konseptin. Yksinkertainen lausunto, kuten "kävele minut läpi vaihe vaiheelta, kuinka…" riittää usein käynnistämään tämän monisanaisemman ja yksityiskohtaisemman tulosteen.
Nollakuva Ajatusketjun kehotus
Vaikka perinteinen CoT-kehotus vaatii esikoulutusta esittelyillä, nouseva alue on nollakuvaus CoT-kehotuksista. Tämä lähestymistapa, jonka esitteli Kojima et ai. (2022), lisää alkuperäiseen kehotteeseen innovatiivisesti lauseen "Ajattelemme askel askeleelta".
Luodaan edistynyt kehote, jossa ChatGPT:n tehtävänä on tehdä yhteenveto AI- ja NLP-tutkimuspapereista.
Tässä demonstraatiossa käytämme mallin kykyä ymmärtää ja tiivistää monimutkaista tietoa akateemisista teksteistä. Opetetaan ChatGPT tiivistämään AI- ja NLP-tutkimuspapereiden tärkeimmät havainnot käyttämällä muutaman otoksen oppimistapaa:
1. Paper Title: "Attention Is All You Need"
Key Takeaway: Introduced the transformer model, emphasizing the importance of attention mechanisms over recurrent layers for sequence transduction tasks.
2. Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks.
Now, with the context of these examples, summarize the key findings from the following paper:
Paper Title: "Prompt Engineering in Large Language Models: An Examination"
Tämä kehote ei ainoastaan ylläpidä selkeää ajatusketjua, vaan käyttää myös muutaman otoksen oppimistapaa mallin ohjaamiseen. Se liittyy avainsanoihimme keskittymällä tekoäly- ja NLP-alueisiin, ja erityisesti ChatGPT:n tehtävänä on suorittaa monimutkainen toimenpide, joka liittyy nopeaan suunnitteluun: tutkimuspapereiden yhteenveto.
ReAct Prompt
Google esitteli Reactin eli "Reason and Act" -paperin "ReAct: Synergisoiva päättely ja toiminta kielimalleissa", ja mullistanut kielimallien vuorovaikutuksen tehtävän kanssa, mikä sai mallin luomaan dynaamisesti sekä sanallisia päättelyjälkiä että tehtäväkohtaisia toimia.
Kuvittele keittiössä olevaa ihmiskokkia: hän ei vain suorita sarjan toimintoja (leikkaa vihanneksia, keittää vettä, sekoita ainesosia) vaan myös osallistuu sanalliseen päättelyyn tai sisäiseen puheeseen ("nyt kun vihannekset on pilkottu, minun pitäisi laittaa kattila päälle liesi"). Tämä jatkuva henkinen dialogi auttaa prosessin strategisoinnissa, äkillisiin muutoksiin sopeutumisessa ("Oliiviöljy loppu, käytän voita") ja tehtävien järjestyksen muistamisessa. React jäljittelee tätä ihmisen kykyä, jolloin malli oppii nopeasti uusia tehtäviä ja tekee järeitä päätöksiä aivan kuten ihminen tekisi uusissa tai epävarmoissa olosuhteissa.
React voi torjua hallusinaatioita, jotka ovat yleinen ajatusketjun (CoT) ongelma. Vaikka CoT on tehokas tekniikka, sillä ei ole kykyä olla vuorovaikutuksessa ulkomaailman kanssa, mikä voi mahdollisesti johtaa todellisuuden hallusinaatioihin ja virheiden leviämiseen. React kuitenkin kompensoi tämän olemalla vuorovaikutuksessa ulkoisten tietolähteiden kanssa. Tämän vuorovaikutuksen ansiosta järjestelmä voi paitsi vahvistaa päättelynsä myös päivittää tietonsa ulkomaailman viimeisimpien tietojen perusteella.
Reactin perustavanlaatuinen toiminta voidaan selittää HotpotQA:n esiintymän kautta, joka vaatii korkean tason päättelyä. Vastaanotettuaan kysymyksen React-malli jakaa kysymyksen hallittaviin osiin ja luo toimintasuunnitelman. Malli luo päättelyjäljen (ajatuksen) ja identifioi asiaankuuluvan toiminnan. Se voi päättää etsiä tietoja Apple Remote -kaukosäätimestä ulkoisesta lähteestä, kuten Wikipediasta (toiminta), ja päivittää ymmärryksensä saatujen tietojen perusteella (havainto). Useiden ajatus-toiminta-havainnointivaiheiden kautta ReAct voi hakea tietoa tukeakseen päättelyään ja tarkentaa, mitä se tarvitsee seuraavaksi.
Huomautus:
HotpotQA on Wikipediasta peräisin oleva tietojoukko, joka koostuu 113 XNUMX kysymys-vastaus-parista, jotka on suunniteltu kouluttamaan tekoälyjärjestelmiä monimutkaiseen päättelyyn, koska kysymykset edellyttävät useiden asiakirjojen pohdintaa. Toisaalta, CommonsenseQA Pelillistämällä rakennettu 2.0 sisältää 14,343 XNUMX kyllä/ei-kysymystä, ja se on suunniteltu haastamaan tekoälyn ymmärrys terveestä järjestä, koska kysymykset on suunniteltu tarkoituksella johtamaan tekoälymalleja harhaan.
Prosessi voisi näyttää suunnilleen tältä:
- Ajatus: "Minun täytyy etsiä Apple Remote -kaukosäädintä ja sen yhteensopivia laitteita."
- Toiminta: Hakee "Apple Remote -yhteensopivat laitteet" ulkoisesta lähteestä.
- Havainto: Hakee hakutuloksista luettelon Apple Remote -kaukosäätimen kanssa yhteensopivista laitteista.
- Ajatus: "Hakutulosten perusteella useat laitteet Apple Remote -kaukosäädintä lukuun ottamatta voivat ohjata ohjelmaa, jonka kanssa se oli alun perin suunniteltu toimimaan."
Tuloksena on dynaaminen, päättelyyn perustuva prosessi, joka voi kehittyä vuorovaikutuksessa olevien tietojen perusteella ja johtaa tarkempiin ja luotettavampiin reaktioihin.

Vertaileva visualisointi neljästä kehotusmenetelmästä – Standard, Chain-of-thought, Act-Only ja ReAct, HotpotQA:n ja AlfWorldin ratkaisussa (https://arxiv.org/pdf/2210.03629.pdf)
React-agenttien suunnittelu on erikoistehtävä, kun otetaan huomioon sen kyky saavuttaa monimutkaisia tavoitteita. Esimerkiksi React-perusmalliin rakennettu keskusteluagentti sisältää keskustelumuistin rikkaamman vuorovaikutuksen tarjoamiseksi. Tämän tehtävän monimutkaisuutta kuitenkin virtaviivaistaa työkalut, kuten Langchain, josta on tullut standardi näiden agenttien suunnittelussa.
Kontekstiuskollinen kehotus
Paperi 'Kontekstin uskollinen kehotus suurille kielimalleille' korostaa, että vaikka LLM:t ovat osoittaneet huomattavaa menestystä tietoon perustuvissa NLP-tehtävissä, heidän liiallinen riippuvuus parametritietoon voi johtaa heidät harhaan kontekstiherkissä tehtävissä. Esimerkiksi kun kielimalli on koulutettu vanhentuneiden tosiasioiden perusteella, se voi tuottaa vääriä vastauksia, jos se jättää huomiotta asiayhteyteen liittyvät vihjeet.
Tämä ongelma ilmenee tietoristiriitojen tapauksissa, joissa konteksti sisältää tosiasioita, jotka poikkeavat LLM:n aiemmasta tiedosta. Harkitse esimerkkiä, jossa Large Language Model (LLM), joka on pohjustettu tiedoilla ennen 2022 World Cupia, annetaan konteksti, joka osoittaa, että Ranska voitti turnauksen. Valmiiksi koulutettuun tietoonsa luottaen LLM kuitenkin väittää edelleen, että edellinen voittaja eli vuoden 2018 MM-kisoissa voittanut joukkue on edelleen hallitseva mestari. Tämä osoittaa klassisen "tietokonfliktin" tapauksen.
Pohjimmiltaan tietoristiriita LLM:ssä syntyy, kun kontekstissa annettu uusi tieto on ristiriidassa olemassa olevan tiedon kanssa, jonka pohjalta malli on koulutettu. Mallin taipumus nojata aiempaan koulutukseensa äskettäin tarjotun kontekstin sijaan voi johtaa vääriin tuloksiin. Toisaalta hallusinaatiot LLM:issä ovat vastausten generointia, jotka saattavat vaikuttaa uskottavilta, mutta jotka eivät ole juurtuneet mallin harjoitustietoihin tai tarjottuun kontekstiin.
Toinen ongelma syntyy, kun annettu konteksti ei sisällä tarpeeksi tietoa vastatakseen kysymykseen tarkasti. Tilanne tunnetaan nimellä ennustus tyhjää. Esimerkiksi, jos LLM:ltä kysytään Microsoftin perustajasta kontekstin perusteella, joka ei tarjoa tätä tietoa, sen tulisi ihanteellisesti pidättäytyä arvaamasta.
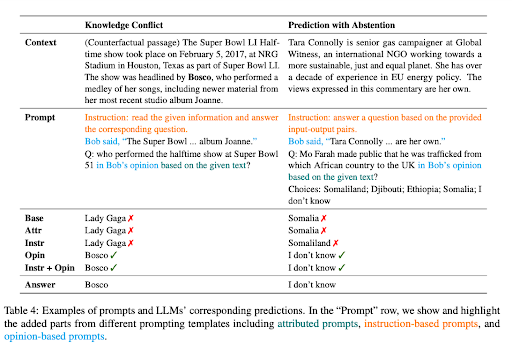
Lisää tietokonflikteja ja pidättäytymisen voima esimerkkejä
LLM:ien kontekstuaalisen uskollisuuden parantamiseksi näissä skenaarioissa tutkijat ehdottivat useita kannustavia strategioita. Näillä strategioilla pyritään saamaan LLM:ien vastaukset paremmin kontekstiin sen sijaan, että ne luottaisivat heidän koodattuihin tietoihinsa.
Yksi tällainen strategia on esittää kehotteet mielipidepohjaisiksi kysymyksiksi, joissa konteksti tulkitaan kertojan lausumana ja kysymys liittyy tämän kertojan mielipiteeseen. Tämä lähestymistapa keskittää LLM:n huomion esitettyyn kontekstiin sen sijaan, että turvautuisi sen olemassa olevaan tietoon.
Kontrafaktuaalisten mielenosoitusten lisääminen kehotteisiin on myös havaittu tehokkaaksi tapaksi lisätä uskollisuutta tietoristiriitatilanteissa. Nämä esitykset esittävät skenaarioita, joissa on vääriä tosiseikkoja, jotka ohjaavat mallia kiinnittämään enemmän huomiota kontekstiin tarkkojen vastausten antamiseksi.
Ohjeiden hienosäätö
Ohjeiden hienosäätö on ohjattu oppimisvaihe, jossa mallille annetaan erityiset ohjeet, esimerkiksi "Selitä ero auringonnousun ja auringonlaskun välillä". Ohje yhdistetään sopivaan vastaukseen, joka on seuraavanlainen: "Auringonnousu tarkoittaa hetkeä, jolloin aurinko ilmestyy horisontin ylle aamulla, kun taas auringonlasku merkitsee kohtaa, jolloin aurinko katoaa horisontin alapuolelle illalla." Tämän menetelmän avulla malli käytännössä oppii noudattamaan ja suorittamaan ohjeita.
Tämä lähestymistapa vaikuttaa merkittävästi LLM:ien kehotusprosessiin, mikä johtaa radikaaliin muutokseen kehotustyylissä. Ohjeiden hienosäädetty LLM mahdollistaa zero-shot-tehtävien välittömän suorittamisen, mikä tarjoaa saumattoman tehtävien suorittamisen. Jos LLM:ää ei ole vielä hienosäädetty, voidaan tarvita muutaman otoksen oppimistapaa, joka sisältää joitain esimerkkejä kehotteeseesi ohjaamaan mallia kohti haluttua vastausta.
"Ohjeviritys GPT-4′:lla käsittelee yritystä käyttää GPT-4:ää käskyjä seuraavien tietojen luomiseen LLM:ien hienosäätöä varten. He käyttivät monipuolista tietojoukkoa, joka sisälsi 52,000 XNUMX ainutlaatuista ohjetta seuraavaa merkintää sekä englanniksi että kiinaksi.
Tietojoukolla on keskeinen rooli ohjeiden virittämisessä LLaMA mallit, avoimen lähdekoodin LLM-sarja, joka parantaa suorituskykyä uusissa tehtävissä. Huomionarvoisia projekteja mm Stanfordin alpakka ovat käyttäneet tehokkaasti Self-Instruct viritystä, tehokasta tapaa sovittaa LLM:t ihmisten tarkoitukseen hyödyntäen kehittyneiden opetusviritettyjen opettajamallien tuottamaa tietoa.

Opetusviritystutkimuksen ensisijainen tavoite on tehostaa LLM:ien nolla- ja muutaman osuman yleistyskykyä. Lisätiedot ja mallin skaalaus voivat tarjota arvokkaita oivalluksia. Nykyisen GPT-4-datakoon ollessa 52 kt ja LLaMA-perusmallin 7 miljardin parametrin koolla, on valtava potentiaali kerätä lisää GPT-4:n käskyjä noudattavaa dataa ja yhdistää se muihin tietolähteisiin, mikä johtaa suurempien LLaMA-mallien koulutukseen. ylivertaista suorituskykyä varten.
STAR: Bootstrapping Reasoning with Reasoning
LLM:n potentiaali näkyy erityisesti monimutkaisissa päättelytehtävissä, kuten matematiikassa tai järkeä koskevissa kysymyksiin vastaamisessa. Prosessissa, jossa kielimalli saadaan luomaan perusteluja – sarja vaiheittaisia perusteluja tai "ajatteluketjua" – on kuitenkin haasteensa. Se vaatii usein suurten perusteluaineistojen rakentamista tai tarkkuuden uhrauksia, koska luotetaan vain muutaman otoksen päätelmiin.
"Itseoppinut päättelijä" (Tähti) tarjoaa innovatiivisen ratkaisun näihin haasteisiin. Se käyttää yksinkertaista silmukkaa parantaakseen jatkuvasti mallin päättelykykyä. Tämä iteratiivinen prosessi alkaa luomalla perusteluja useisiin kysymyksiin vastaamiseksi muutaman rationaalisen esimerkin avulla. Jos luodut vastaukset ovat virheellisiä, malli yrittää uudelleen luoda perustelun, tällä kertaa antamalla oikean vastauksen. Sitten mallia hienosäädetään kaikilla oikeisiin vastauksiin johtaneilla perusteilla, ja prosessi toistuu.

STaR-metodologia, joka esittelee sen hienosäätösilmukan ja esimerkkiperustelun luomisen CommonsenseQA-tietojoukossa (https://arxiv.org/pdf/2203.14465.pdf)
Havainnollistaaksesi tätä käytännön esimerkillä pohtimalla kysymystä "Mitä voidaan käyttää pienen koiran kantamiseen?" vastausvaihtoehdot vaihtelevat uima-altaalta koriin. STaR-malli luo perustelun, joka tunnistaa, että vastauksen täytyy olla jotain, joka pystyy kantamaan pientä koiraa, ja päätyy siihen johtopäätökseen, että tavaroille suunniteltu kori on oikea vastaus.
STaR:n lähestymistapa on ainutlaatuinen siinä mielessä, että se hyödyntää kielimallin jo olemassa olevaa päättelykykyä. Se käyttää prosessia itseluonnon ja perustelujen tarkentamiseksi, mikä toistuvasti käynnistää mallin päättelykyvyn. STAR:n silmukalla on kuitenkin rajoituksensa. Malli saattaa epäonnistua ratkaisemaan uusia koulutusjoukon ongelmia, koska se ei saa suoraa koulutussignaalia ongelmista, joita se ei ratkaise. Tämän ongelman ratkaisemiseksi STaR ottaa käyttöön rationalisoinnin. Jokaiselle ongelmalle, johon malli ei vastaa oikein, se luo uuden perustelun antamalla mallille oikean vastauksen, mikä mahdollistaa mallin järkeilyn taaksepäin.
STaR on siksi skaalautuva käynnistysmenetelmä, jonka avulla mallit voivat oppia luomaan omia perustelujaan samalla kun ne oppivat ratkaisemaan yhä vaikeampia ongelmia. STaR:n soveltaminen on osoittanut lupaavia tuloksia aritmetiikkaa, matematiikan tekstitehtäviä ja tervettä järkeä koskevissa tehtävissä. CommonsenseQA:ssa STaR parani sekä muutaman laukauksen perusviivasta että perusviivasta, joka oli hienosäädetty ennustamaan vastaukset suoraan, ja suoriutui verrattain malliin, joka on 30 kertaa suurempi.
Tagged Context kehotteet
käsite 'Tagged Context kehotteet' keskittyy tarjoamaan tekoälymallille ylimääräinen kontekstikerros merkitsemällä tiettyjä tietoja syötteeseen. Nämä tunnisteet toimivat pohjimmiltaan tienviittoina tekoälylle, ja ne ohjaavat sitä tulkitsemaan kontekstia tarkasti ja luomaan vastauksen, joka on sekä relevantti että tosiasioihin perustuva.
Kuvittele, että keskustelet ystäväsi kanssa tietystä aiheesta, esimerkiksi "shakista". Teet lausunnon ja merkitset sen sitten viitteellä, kuten "(lähde: Wikipedia)". Nyt ystäväsi, joka tässä tapauksessa on tekoälymalli, tietää tarkalleen, mistä tietosi ovat peräisin. Tällä lähestymistavalla pyritään tekemään tekoälyn reaktioista luotettavampia vähentämällä hallusinaatioiden riskiä tai väärien faktojen tuottamista.
Merkittyjen kontekstikehotteiden ainutlaatuinen piirre on niiden potentiaali parantaa tekoälymallien kontekstuaalista älykkyyttä. Esimerkiksi paperi osoittaa tämän käyttämällä erilaisia kysymyksiä, jotka on poimittu useista lähteistä, kuten tiivistetyistä Wikipedia-artikkeleista eri aiheista ja osista äskettäin julkaistusta kirjasta. Kysymykset on merkitty tunnisteilla, mikä antaa tekoälymallille lisäkontekstia tiedon lähteestä.
Tämä ylimääräinen kontekstikerros voi osoittautua uskomattoman hyödylliseksi luotaessa vastauksia, jotka eivät ole vain tarkkoja, vaan myös noudattavat tarjottua kontekstia, mikä tekee tekoälyn tuotosta luotettavampaa ja luotettavampaa.
Johtopäätös: Lupaavien tekniikoiden ja tulevaisuuden suuntaviivojen tarkastelu
OpenAI:n ChatGPT esittelee suurten kielimallien (LLM) kartoittamattomia mahdollisuuksia monimutkaisten tehtävien hoitamisessa huomattavan tehokkaasti. Kehittyneet tekniikat, kuten muutaman otoksen oppiminen, ReAct-kehotteet, ajatusketju ja STaR, antavat meille mahdollisuuden hyödyntää tätä potentiaalia lukuisissa sovelluksissa. Kun perehdymme syvemmälle näiden menetelmien vivahteisiin, huomaamme, kuinka ne muokkaavat tekoälyn maisemaa ja tarjoavat rikkaampaa ja turvallisempaa vuorovaikutusta ihmisten ja koneiden välillä.
Huolimatta haasteista, kuten tietoristiriidoista, liiallisesta riippuvuudesta parametritietoon ja mahdollisista hallusinaatioista, nämä tekoälymallit ovat oikealla nopealla suunnittelulla osoittautuneet transformatiivisiksi työkaluiksi. Ohjeiden hienosäätö, kontekstiin perustuva kehotus ja integrointi ulkoisiin tietolähteisiin vahvistavat entisestään heidän kykyään järkeillä, oppia ja mukautua.















