
Tekoäly
Tekoälytutkimus suunnittelee erilliset äänenvoimakkuuden säätimet dialogille, musiikille ja äänitehosteille

Uusi Mitsubishin johtama tutkimusyhteistyö tutkii mahdollisuutta poimia kolme erillistä ääniraitaa alkuperäisestä äänilähteestä ja jakaa ääniraita puheeksi, musiikiksi ja äänitehosteiksi (eli ympäristön meluksi).
Koska tämä on jälkikäsittelykehys, se tarjoaa mahdollisuuden myöhempien sukupolvien multimedian katselualustoille, mukaan lukien kuluttajalaitteet, tarjota kolmipisteisiä äänenvoimakkuuden säätimiä, joiden avulla käyttäjä voi nostaa dialogin äänenvoimakkuutta tai vähentää ääniraidan äänenvoimakkuutta. .
Alla olevassa lyhyessä pätkässä tutkimuksen oheisesta videosta (katso koko video artikkelin lopusta) näemme, että ääniraidan eri puolia korostetaan, kun käyttäjä vetää säädintä kolmion poikki, jossa jokainen kolmesta äänikomponentista on yhdessä kulmassa. :
Lyhyt pätkä artikkelin mukana tulevasta videosta (katso upotus artikkelin lopussa). Kun käyttäjä vetää kohdistinta kohti yhtä kolmesta poimitusta kolmiokäyttöliittymässä (oikealla), ääni korostaa kolmiosaisen ääniraidan tätä osaa. Vaikka pidemmässä videossa mainitaan useita lisäesimerkkejä YouTubesta, ne eivät näytä olevan tällä hetkellä saatavilla. Lähde: https://vimeo.com/634073402
- paperi on oikeutettu Cocktail-haarukkaongelma: kolmen varren äänen erottelu todellisille ääniraidoilla, ja tulee tutkijoilta Mitsubishi Electric Research Laboratoriesista (MERL) Cambridgessa, MA:ssa ja älykkäiden järjestelmien suunnittelun laitokselta Indianan yliopistossa Illinoisissa.
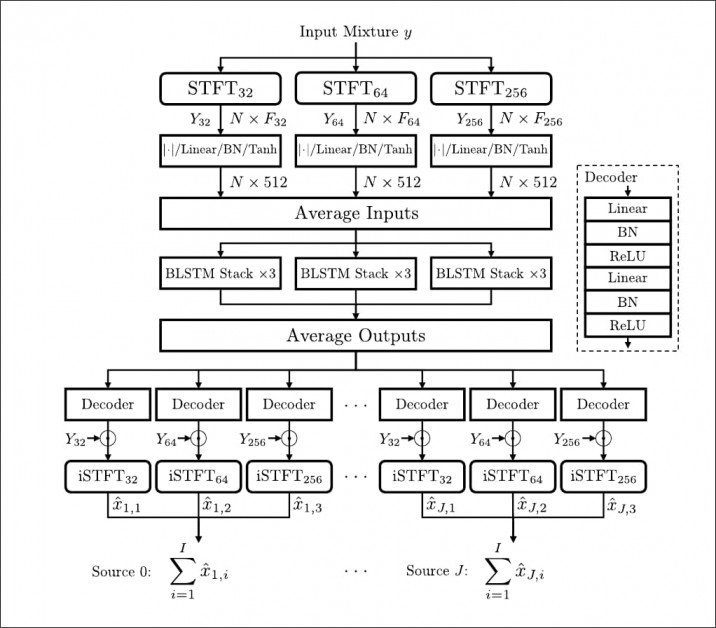
Ääniraidan puolien erottaminen
Tutkijat ovat nimenneet haasteen Cocktail Party -ongelmaksi, koska se sisältää ääniraidan voimakkaasti kietoutuneiden elementtien eristämisen, mikä luo haarukkaa muistuttavan tiekartan (katso kuva alla). Käytännössä monikanavaisissa (eli stereoissa ja muissa) ääniraidoissa voi olla erityyppistä sisältöä, kuten dialogia, musiikkia ja tunnelmaa, varsinkin kun dialogilla on taipumus hallitsevat keskikanavaa Dolby 5.1 -sekoituksissa. Tällä hetkellä kuitenkin. erittäin aktiivinen äänen erottelun tutkimuskenttä keskittyy näiden säikeiden kaappaamiseen yhdestä, leivotusta ääniraidasta, kuten nykyinen tutkimus.

Cocktail Fork – tuottaa kolme erillistä ääniraitaa yhdistetystä ja yhdestä ääniraidasta. Lähde: https://arxiv.org/pdf/2110.09958.pdf
Viimeaikaiset tutkimukset ovat keskittyneet puheen poimimiseen eri ympäristöissä, usein puheäänen vaimentamiseksi luonnollisen kielenkäsittelyjärjestelmän (NLP) myöhempää käyttöä varten, mutta myös eristäminen arkiston lauluäänistä joko synteettisten versioiden luomiseksi todellisesta (jopa kuollut) laulajia tai helpottaa Karaoke-tyylinen musiikin eristäminen.
Tietojoukko jokaiselle osa-alueelle
Tähän mennessä tämänkaltaisen tekoälytekniikan käyttöä ei ole juurikaan harkittu, jotta käyttäjät voivat hallita paremmin ääniraidan sekoitusta. Siksi tutkijat ovat virallistaneet ongelman ja luoneet uuden tietojoukon avuksi meneillään olevaan monityyppisten ääniraitojen erottelun tutkimukseen sekä testaamaan sitä erilaisilla olemassa olevilla äänen erottelukehyksillä.
Uusi tietojoukko, jonka kirjoittajat ovat kehittäneet, on ns Jaa ja remasteroi (DnR), ja se on johdettu aikaisemmista tietojoukoista LibriSpeech, Ilmainen musiikkiarkisto ja Freesound Dataset 50k (FSD50K). Niille, jotka haluavat työskennellä DnR:n kanssa tyhjästä, tietojoukko on rekonstruoitava kolmesta lähteestä; muutoin se tulee pian saataville Zenodossa, kirjoittajat väittävät. Kuitenkin kirjoitushetkellä tarjottu GitHub-linkki lähteen poiminta-apuohjelmat eivät ole tällä hetkellä aktiivisia, joten kiinnostuneiden on ehkä odotettava jonkin aikaa.
Tutkijat ovat havainneet, että CrossNet un-mix (XUMX) Sonyn toukokuussa ehdottama arkkitehtuuri toimii erityisen hyvin DnR:n kanssa.
Sonyn CrossNet-arkkitehtuuri.
Kirjoittajat väittävät, että heidän koneoppimismallinsa toimivat hyvin YouTuben ääniraitojen kanssa, vaikka julkaisussa esitetyt arviot perustuvat synteettiseen dataan, ja toimitettu päätukivideo (upotettu alla) on tällä hetkellä ainoa, joka näyttää olevan saatavilla.
Kukin kolme käytettyä tietojoukkoa sisältävät kokoelman sellaisia lähtöjä, jotka on erotettava ääniraidosta: FSD50K on täynnä äänitehosteita, ja se sisältää 50,000 44.1 200 kHz:n monoääniotosta, jotka on merkitty 100,000 luokkatunnisteella Googlen AudioSet-ontologiasta; Free Music Archive sisältää 161 25,000 stereokappaletta, jotka kattavat 50 musiikkigenreä, vaikka kirjoittajat ovat käyttäneet 100 44.1 kappaleen sisältävää osajoukkoa FSD3K:n rinnalle; ja LibriSpeech tarjoaa DnR:lle XNUMX tuntia äänikirjanäytteitä XNUMX kHz mpXNUMX-äänitiedostoina.
Tuleva työ
Kirjoittajat odottavat jatkotyöskentelyä tietojoukon parissa ja erillisten mallien yhdistelmää, joka on kehitetty lisätutkimukseen puheentunnistuksen ja äänen luokittelun kehyksissä, jotka sisältävät automaattisen tekstityksen luomisen puheille ja ei-puheäänille. He aikovat myös arvioida mahdollisuuksia uudelleenmiksaamiseen, jotka voivat vähentää havaintovirheitä, mikä on edelleen keskeinen ongelma jaettaessa yhdistettyä ääniraitaa sen komponentteihin.
Tällainen erottelu voisi tulevaisuudessa olla saatavilla kulutushyödykkeenä älytelevisioissa, joissa on erittäin optimoituja päättelyverkkoja, vaikka näyttää todennäköiseltä, että varhaiset toteutukset vaatisivat jonkin verran esikäsittelyaikaa ja tallennustilaa. Samsung jo käyttötarkoituksiin paikallisia hermoverkkoja skaalausta varten, kun taas Sonyn Kognitiivinen prosessori XR, jota käytetään yrityksen Bravia-valikoimassa, analysoi ja tulkitsee ääniraidat livenä kevyen integroidun tekoälyn kautta.
Vaatii parempaa hallintaa ääniraidan sekoituksessa toistua ajoittain, ja suurin osa tarjottuja ratkaisuja joudutaan käsittelemään sitä tosiasiaa, että ääniraita on jo pomppinut alas nykyisten standardien (ja katsojien haluamia olettamuksia) mukaisesti elokuva- ja tv-alalla.
Eräs katsoja, jota harmitti elokuvien ääniraitojen eri osien äänenvoimakkuustasojen järkyttävä ero, tuli tarpeeksi epätoivoiseksi kehittää laitteistopohjainen automaattinen äänenvoimakkuuden säädin, joka pystyy tasoittava äänenvoimakkuus elokuviin ja televisioon.
Vaikka älytelevisiot tarjoavat a monenlaisia menetelmiä yrittääkseen lisätä dialogin äänenvoimakkuutta musiikin suurenmoisia äänenvoimakkuustasoja vastaan, he kaikki kamppailevat miksausaikana tehtyjä päätöksiä vastaan ja luultavasti myös sisällöntuottajien visioita vastaan, jotka haluavat yleisön kokevan heidän ääniraidansa juuri sellaisina kuin ne on asetettu.
Sisällöntuottajat näyttävät vastustavan tätä mahdollista lisäystä "remix-kulttuuriin", koska useat alan huipputekijät ovat jo ilmaisseet tyytymättömyytensä TV-pohjaisiin jälkikäsittelyalgoritmeihin. kuten liikkeen tasoitus.













