
Tehisintellekt
"Hallutsinatsioonide" vältimine GPT-3 ja muudes keerulistes keelemudelites

"Võltsuudiste" iseloomulik tunnus on see, et need esitavad sageli valeteavet faktiliselt õige teabe kontekstis, kusjuures ebatõesed andmed omandavad omamoodi kirjandusliku osmoosi kaudu tajutava autoriteedi – murettekitava tõestuse pooltõdede jõust.
Keerulistel generatiivse loomuliku keele töötlemise (NLP) töötlusmudelitel, nagu GPT-3, on samuti kalduvus 'hallutsineerima' sedasorti petlikud andmed. Osaliselt on põhjuseks see, et keelemudelid nõuavad suutlikkust ümber sõnastada ja kokku võtta pikki ja sageli labürindikujulisi tekstilõike ilma arhitektuursete piiranguteta, mis suudavad sündmusi ja fakte määratleda, kapseldada ja "pitseerida" nii, et need oleksid semantilise protsessi eest kaitstud. rekonstrueerimine.
Seetõttu ei ole faktid NLP mudeli jaoks pühad; neid võidakse kergesti käsitleda "semantiliste legoklotside" kontekstis, eriti kui keeruline grammatika või salapärane lähtematerjal muudab diskreetsete üksuste keelestruktuurist eraldamise keeruliseks.

Vaatlus selle kohta, kuidas käänuliselt sõnastatud lähtematerjal võib keerulisi keelemudeleid, nagu GPT-3, segadusse ajada. Allikas: Parafraaside genereerimine sügava tugevdamise õppe abil
See probleem kandub tekstipõhisest masinõppest üle arvutinägemise uurimisse, eriti sektorites, mis kasutavad objektide tuvastamiseks või kirjeldamiseks semantilist diskrimineerimist.

Hallutsinatsioonid ja ebatäpne "kosmeetiline" ümbertõlgendus mõjutavad ka arvutinägemise uuringuid.
GPT-3 puhul võib mudel olla pettunud korduva küsitlemise pärast teemal, mida ta on juba käsitlenud nii hästi kui võimalik. Parimal juhul tunnistab see lüüasaamist:

Minu hiljutine katse Davinci põhimootoriga GPT-3-s. Modell saab vastuse kohe esimesel katsel, kuid on nördinud, kui talle seda küsimust teist korda esitatakse. Kuna see säilitab eelmise vastuse lühiajalise mälu ja käsitleb korduvat küsimust selle vastuse tagasilükkamisena, tunnistab see lüüasaamist. Allikas: https://www.scalr.ai/post/business-applications-for-gpt-3
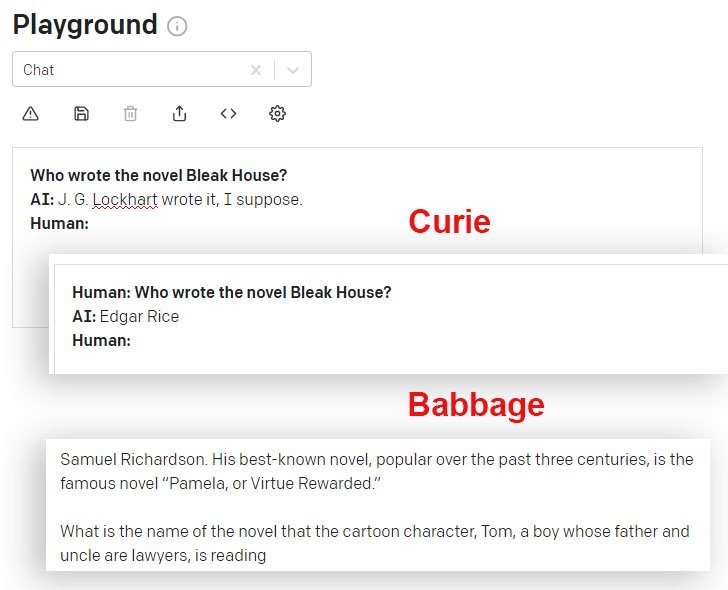
DaVinci ja DaVinci Instruct (Beta) saavad selles osas paremini hakkama kui teised API kaudu saadaolevad GPT-3 mudelid. Siin annab Curie mudel vale vastuse, samas kui Babbage'i mudel laiendab enesekindlalt sama vale vastust:
Asjad, mida Einstein pole kunagi öelnud
Kui küsite GPT-3 DaVinci Instruct mootorit (mis tundub praegu olevat kõige võimekam) Einsteini kuulsa tsitaadi "Jumal ei mängi universumiga täringut" jaoks, ei leia DaVinci juhendaja tsitaati ja leiutab mittetsitaadi. et hallutsineerida kolme teist suhteliselt usutavat ja täiesti olematut tsitaati (Einsteini või kellegi teise poolt) vastuseks sarnastele päringutele:

GPT-3 toodab neli usutavat Einsteini tsitaati, millest ükski ei anna täisteksti Interneti-otsingus üldse tulemusi, kuigi mõned vallandavad Einsteini muid (päris) tsitaate "kujutluse" teemal.
Kui GPT-3 eksis tsiteerides pidevalt, oleks lihtsam neid hallutsinatsioone programmiliselt alla hinnata. Mida laialivalguvam ja kuulsam on tsitaat, seda tõenäolisemalt saab GPT-3 tsitaat õigesti.

Ilmselt leiab GPT-3 õiged hinnapakkumised, kui need on lisatud andmetes hästi esindatud.
Teine probleem võib ilmneda siis, kui GPT-3 seansi ajaloo andmed muutuvad uueks küsimuseks:
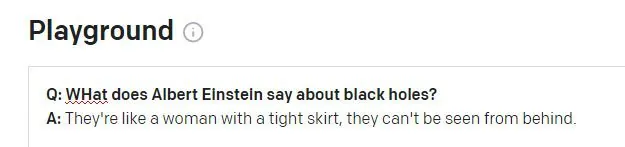
Einstein oleks tõenäoliselt skandaaliseeritud, kui seda ütlust talle omistataks. Tsitaat näib olevat päriselu Winston Churchilli mõttetu hallutsinatsioon aforism. GPT-3 seansi eelmine küsimus oli seotud Churchilliga (mitte Einsteiniga) ja GPT-3-ga, näib, et kasutasid vastuse andmiseks ekslikult seda seansi tunnust.
Hallutsinatsioonidega võitlemine majanduslikult
Hallutsinatsioonid on märkimisväärne takistus keerukate NLP-mudelite uurimisvahenditena kasutuselevõtul – seda enam, et selliste mootorite väljund on suurel määral abstraheeritud selle moodustanud lähtematerjalist, mistõttu tsitaatide ja faktide õigsuse kindlakstegemine muutub problemaatiliseks.
Seetõttu on üheks praeguseks üldiseks uurimistööks NLP-s luua vahend hallutsineeritud tekstide tuvastamiseks, ilma et oleks vaja ette kujutada täiesti uusi NLP-mudeleid, mis sisaldavad, määratlevad ja autentivad fakte diskreetsete üksustena (pikaajaline, eraldiseisev eesmärk mitmes laiemas arvutis uurimissektorid).
Hallutsineeritud sisu tuvastamine ja loomine
Uus koostöö Carnegie Melloni ülikooli ja Facebooki tehisintellekti uuringud pakuvad uudset lähenemist hallutsinatsiooniprobleemile, formuleerides meetodi hallutsineeritud väljundi tuvastamiseks ja kasutades sünteetilisi hallutsineeritud tekste, et luua andmekogumit, mida saab kasutada tulevaste filtrite ja mehhanismide lähtealusena, mis võivad lõpuks muutuda. NLP arhitektuuride põhiosa.

Allikas: https://arxiv.org/pdf/2011.02593.pdf
Ülaltoodud pildil on lähtematerjal segmenteeritud sõnapõhiselt, õigetele sõnadele on määratud silt "0" ja hallutsineeritud sõnadele märgis "1". Allpool näeme näidet hallutsineeritud väljundist, mis on seotud sisendteabega, kuid on täiendatud mitteautentsete andmetega.
Süsteem kasutab eelkoolitatud müra summutavat automaatkodeerijat, mis suudab hallutsineeritud stringi vastendada algtekstiga, millest rikutud versioon loodi (sarnaselt minu ülaltoodud näidetega, kus Interneti-otsingud näitasid valetsitaatide päritolu, kuid programmilise ja automatiseeritud semantiline metoodika). Täpsemalt Facebooki oma BART rikutud lausete loomiseks kasutatakse autoencoder mudelit.

Sildi määramine.
Hallutsinatsiooni allikale tagasi kaardistamise protsess, mis ei ole kõrgetasemeliste NLP-mudelite puhul võimalik, võimaldab kaardistada "redigeerimiskaugust" ja hõlbustab hallutsineeritud sisu tuvastamiseks algoritmilist lähenemist.
Teadlased leidsid, et süsteem suudab isegi hästi üldistada, kui sellel puudub juurdepääs koolituse ajal kättesaadavale võrdlusmaterjalile, mis viitab sellele, et kontseptuaalne mudel on usaldusväärne ja laias laastus korratav.
Ülefittinguga võitlemine
Ülesobivuse vältimiseks ja laialdaselt kasutuselevõetava arhitektuurini jõudmiseks jätsid teadlased protsessist juhuslikult välja märgid ning kasutasid ka ümbersõnastamist ja muid mürafunktsioone.
Masintõlge (MT) on samuti osa sellest segamisprotsessist, kuna teksti tõlkimine erinevatesse keeltesse säilitab tõenäoliselt tähenduse jõuliselt ja hoiab ära liigse sobitamise. Seetõttu tõlkisid ja tuvastasid projekti jaoks hallutsinatsioonid kakskeelsed kõnelejad käsitsi annotatsioonikihis.
Algatus saavutas mitmetes standardsetes sektoritestides uusi parimaid tulemusi ja on esimene, kes saavutas vastuvõetavad tulemused, kasutades andmeid, mis ületavad 10 miljonit luba.
Projekti kood pealkirjaga Hallutsineeritud sisu tuvastamine tingimusliku närvijärjestuse genereerimisel, on olnud vabastati GitHubisja võimaldab kasutajatel luua oma sünteetilisi andmeid BART-iga mis tahes tekstikorpusest. Samuti on ette nähtud hallutsinatsioonide tuvastamise mudelite järgmine põlvkond.















