
Tehisintellekt
AI-põhine uudisteartiklite eelarvamuste kontrollija, saadaval Pythonis

Kanada, India, Hiina ja Austraalia teadlased on teinud koostööd, et koostada vabalt saadaolev Pythoni pakett, mida saab tõhusalt kasutada uudiste koopiates ebaausa keele tuvastamiseks ja asendamiseks.
Süsteem, pealkirjaga Dbias, kasutab erinevaid masinõppetehnoloogiaid ja andmebaase, et arendada kolmeastmelist ringikujulist töövoogu, mida saab täpsustada kallutatud tekst kuni see tagastab erapooletu või vähemalt neutraalsema versiooni.

Dbias teisendab kallutatud uudistelõigu laaditud keele vähem sütitavaks versiooniks. Allikas: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
Süsteem kujutab endast korduvkasutatavat ja iseseisvat torujuhet, mida saab installitud Pipi kaudu Hugging Face'ist ja integreeritakse olemasolevatesse projektidesse täiendava etapi, lisandmoodulina või pistikprogrammina.
Aprillis rakendati sarnaseid funktsioone Google Docsis sattus kriitika alla, eriti selle redigeerimise puudumise tõttu. Teisest küljest saab Dbiast valikulisemalt koolitada mis tahes lõppkasutaja soovitud uudistekorpuse põhjal, säilitades võimaluse töötada välja õigluse kohandamise juhised.
Kriitiline erinevus seisneb selles, et Dbiase torujuhe on mõeldud „laaditud keele” (sõnad, mis lisavad faktilisele suhtlusele kriitilise kihi) automaatselt teisendamiseks neutraalseks või proosaliseks keeleks, selle asemel, et kasutajat pidevalt koolitada. Põhimõtteliselt määratleb lõppkasutaja eetilised filtrid ja koolitab süsteemi vastavalt; Google Docsi lähenemisviisi puhul koolitab süsteem kasutajat ühepoolselt.
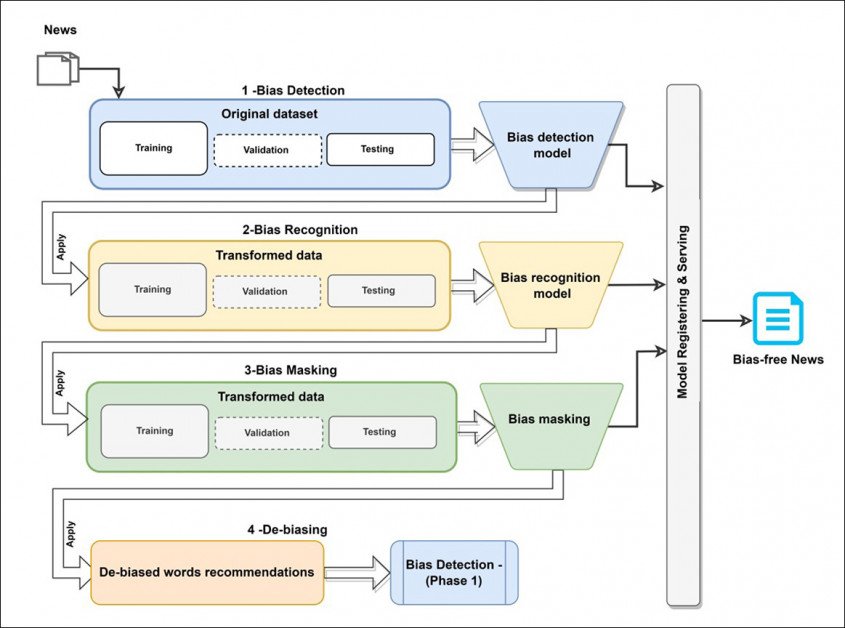
Dbiase töövoo kontseptuaalne arhitektuur.
Teadlaste sõnul on Dbias esimene tõeliselt konfigureeritav kallutatuse tuvastamise pakett, erinevalt valmiskomplekteerimisprojektidest, mis on seda loomuliku keele töötlemise (NLP) alamsektorit siiani iseloomustanud.
. uus paber on pealkirjaga Lähenemisviis uudisteartiklite õigluse tagamiseksja pärineb Toronto ülikooli, Toronto Metropolitani ülikooli, Bangalore'i keskkonnaressursside juhtimise, Hiina DeepBlue teaduste akadeemia ja Sydney ülikooli kaastöötajatelt.
Meetod
Dbiase esimene moodul on Kallutatuse tuvastamine, mis võimendab DistilBERT pakett – väga optimeeritud versioon Google'i üsna masinamahukast BERT. Projekti jaoks viidi DistilBERT Media Bias Annotation (MBIC) andmestik.

MBIC koosneb uudisteartiklitest erinevatest meediaallikatest, sealhulgas Huffington Post, USA Today ja MSNBC. Teadlased kasutasid andmestiku laiendatud versiooni.
Kuigi algandmeid kommenteerisid rahvahulga hankinud töötajad (meetod, mis tuli tule alla 2021. aasta lõpus), suutsid uue artikli uurijad tuvastada andmekogus täiendavaid märgistamata kallutatuse juhtumeid ja lisada need käsitsi. Rassi, hariduse, etnilise kuuluvuse, keele, religiooni ja sooga seotud eelarvamuste tuvastatud esinemissagedus.
Järgmine moodul, Eelarvamuste tuvastamine, kasutab Nimega üksuse tunnustamine (NER), et eraldada sisendtekstist kallutatud sõnad. Paberis on kirjas:
"Näiteks uudise "Ära osta pseudoteaduslikku hüpet tornaadode ja kliimamuutuste kohta" on eelnev eelarvamuste tuvastamise moodul klassifitseerinud kallutatud ja kallutatud tuvastusmoodul suudab nüüd tuvastada termini "pseudoteaduslik haip". kallutatud sõnana.'
NER pole spetsiaalselt selle ülesande jaoks loodud, kuid seda on kasutatud enne eelarvamuste tuvastamiseks, eriti a 2021 projekt Ühendkuningriigi Durhami ülikoolist.
Selles etapis kasutasid teadlased RoBERTa kombineerituna SpaCy English Transformer NER torujuhtmega.

Järgmine etapp, Eelarvamuste maskeerimine, hõlmab tuvastatud kallutatuse sõnade uudset mitut maski, mis toimib järjestikku mitme tuvastatud kallutatud sõna korral.

Laaditud keel asendatakse Dbiase kolmandas etapis pragmaatilise keelega. Pange tähele, et "suu andmine" ja "kasutamine" võrduvad sama tegevusega, kuigi esimest peetakse pilkavaks.
Vajadusel saadetakse selle etapi tagasiside edasiseks hindamiseks tagasi konveieri algusesse, kuni on loodud mitu sobivat alternatiivset fraasi või sõna. Selles etapis kasutatakse maskeeritud keele modelleerimist (MLM) piki a 2021 koostöö mida juhib Facebook Research.
Tavaliselt maskeerib MLM-i ülesanne juhuslikult 15% sõnadest, kuid Dbias töövoog käsib protsessil kasutada sisendiks tuvastatud kallutatud sõnu.
Arhitektuur rakendati ja koolitati rakenduses Google Colab Pro seadmel NVIDIA P100 koos 24 GB VRAM-iga 16 partiisuuruses, kasutades vaid kahte silti (erapooletu ja erapooletu).
Testid
Teadlased testisid Dbiast viie võrreldava lähenemisviisi vastu: LG-TFIDF koos Logistiline regressioon ja TfidfVektorizer (TFIDF) sõna manustamine; LG-ELMO; MLP-ELMO (edasisuunaline tehisnärvivõrk, mis sisaldab ELMO manuseid); BERT; ja RoBERTa.
Testides kasutatud mõõdikud olid täpsus (ACC), täpsus (PREC), meeldetuletus (Rec) ja F1 skoor. Kuna teadlastel ei olnud teadmisi ühestki olemasolevast süsteemist, mis suudaks kõiki kolme ülesannet ühe torujuhtmega täita, tehti konkureerivate raamistike jaoks loobumine, hinnates ainult Dbiase peamisi ülesandeid - eelarvamuste tuvastamist ja tuvastamist.

Dbiase katsete tulemused.
Dbias suutis ületada tulemusi kõigist konkureerivatest raamistikest, sealhulgas suurema töötlemisalajäljega raamistikest
Dokumendis öeldakse:
"Tulemus näitab ka seda, et sügavad neuraalsed manused võivad üldiselt ületada traditsioonilisi manustamismeetodeid (nt TFIDF) eelarvamuste klassifitseerimise ülesandes. Seda näitab sügavate närvivõrkude manustamise (st ELMO) parem jõudlus võrreldes TFIDF-i vektoriseerimisega, kui seda kasutatakse LG-ga.
"See on ilmselt tingitud sellest, et sügavad neuraalsed manused suudavad paremini tabada tekstis olevate sõnade konteksti erinevates kontekstides. Sügavad neuraalsed manused ja sügavad närvimeetodid (MLP, BERT, RoBERTa) toimivad samuti paremini kui traditsiooniline ML-meetod (LG).
Teadlased märgivad ka, et trafol põhinevad meetodid ületavad konkureerivaid meetodeid eelarvamuste tuvastamisel.
Täiendav test hõlmas Dbiase ja SpaCy Core Webi erinevate maitsete võrdlemist, sealhulgas core-sm (väike), core-md (keskmine) ja core-lg (suur). Dbias suutis juhatust juhtida ka järgmistel katsetel:

Uurijad järeldavad, et kallutatuse tuvastamise ülesanded näitavad üldiselt paremat täpsust suuremates ja kallimates mudelites, kuna nad arvavad, et parameetrite ja andmepunktide arv on suurenenud. Samuti märgivad nad, et tulevase töö tõhusus selles valdkonnas sõltub suurematest jõupingutustest kvaliteetsete andmekogumite märkimiseks.
Mets ja puud
Loodetavasti integreeritakse selline peeneteraline eelarvamuste tuvastamise projekt lõpuks kallutatust otsivatesse raamistikesse, mis suudavad võtta vähem lühinägelikku vaadet ja võtta arvesse, et mis tahes konkreetse loo kajastamine on iseenesest kallutamine, mis võib olla potentsiaalne. mille põhjuseks on rohkem kui lihtsalt teatatud vaatamiste statistika.
Esmakordselt avaldatud 14. juulil 2022.















