Inteligencia artificial
No, no estaban limitando a Claude – En realidad era peor

Está bien, hablemos sobre lo que ha estado sucediendo con Claude, porque si lo ha estado utilizando durante el último mes, probablemente haya notado que algo estaba mal.
Durante las últimas seis semanas, los usuarios de Claude han estado perdiendo la cabeza. A principios de agosto, las quejas comenzaron a inundar Reddit, X y foros de desarrolladores. Los problemas estaban por todas partes:
- El código que solía funcionar perfectamente de repente se rompió
- Claude afirmaba que había realizado cambios en los archivos cuando en realidad no lo había hecho
- Caracteres tailandeses o chinos aleatorios aparecían en respuestas en inglés
- Las instrucciones eran completamente ignoradas
- La misma solicitud daba respuestas de calidad muy diferentes
- Los usuarios de Claude Code decían que se sentía “lobotomizado” en comparación con antes
Las quejas se volvieron tan malas que a finales de agosto, la gente estaba convencida de que Anthropic estaba secretamente limitando a Claude para ahorrar dinero. Las teorías de la conspiración estaban por todas partes – tal vez estaban reduciendo la calidad durante las horas pico, tal vez habían cambiado silenciosamente a un modelo más barato, tal vez esta era una degradación intencional para gestionar los costos del servidor.
Los usuarios estaban pagando por Claude Pro y obteniendo lo que se sentía como Claude Lite. Los desarrolladores que habían construido flujos de trabajo alrededor de Claude estaban viendo cómo su productividad se desplomaba. Con eso dicho, algunos usuarios no experimentaban ningún problema en absoluto, lo que hacía que todo fuera más confuso.
Anthropic finalmente admite: Sí, tuvimos problemas
Después de semanas de quejas de los usuarios y una creciente frustración, Anthropic acaba de publicar un masivo informe técnico post-mortem que básicamente dice: “Tenían razón. Claude estaba roto. Esto es lo que sucedió.”
Y la respuesta es interesante.
Resulta que no fue un problema. Fueron tres errores de infraestructura completamente separados, todos ocurriendo al mismo tiempo, creando una tormenta perfecta de degradación de la IA. No estaban limitando. No estaban cortando esquinas. Simplemente tenían tres cosas rotas simultáneamente de maneras que les tomaron seis semanas entender y arreglar.
Déjame desglosar exactamente lo que salió mal, porque esto es realmente una mirada útil a cómo pueden fallar estos sistemas de IA de maneras que nadie anticipa.
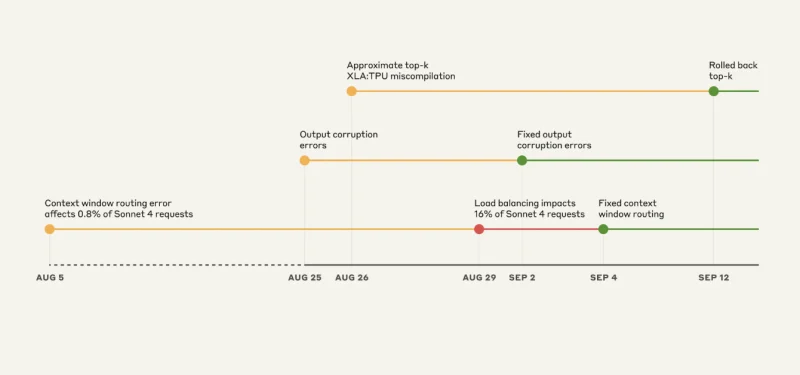
El colapso de los tres errores: Una cronología del caos
Fuente: Anthropic
Error #1: El problema del servidor equivocado
Esto es casi divertido si no hubieras sido tú quien lo experimentó. Claude Sonnet 4 estaba diseñado para manejar 200,000 contextos de tokens. Pero a partir del 5 de agosto, algunas solicitudes se estaban enrutando a servidores configurados para 1 millón de contextos de tokens.
Inicialmente, solo el 0,8% de las solicitudes se vieron afectadas. No es gran cosa, ¿verdad? Mal.
El 29 de agosto, una actualización de routine del equilibrador de carga convirtió este problema menor en un problema mayor. De repente, en el pico, el 16% de las solicitudes de Sonnet 4 se estaban enrutando a los servidores equivocados. Y la routa era “pegajosa”. Una vez que te enrutaras mal, seguías siendo enrutado mal.
El impacto:
- Aproximadamente el 30% de los usuarios de Claude Code que estaban activos durante la ventana tuvieron al menos una solicitud mal enrutada
- Los tiempos de respuesta se desplomaron para los usuarios afectados
- El mismo usuario experimentaría el problema repetidamente mientras que otros no tenían problemas
Error #2: El generador de caracteres aleatorios
El 25 de agosto, Anthropic desplegó una configuración incorrecta en sus servidores TPU. El resultado fue que Claude comenzó a insertar aleatoriamente caracteres tailandeses y chinos en respuestas en inglés.
Imagina pedirle a Claude que depure tu código Python y obtener esto:
def calculate_total(items)
total = 0
for item in items
總計 += item.price # <- ¿Qué?
return ผลรวม
Esto afectó:
- Opus 4.1 y Opus 4: 25-28 de agosto
- Sonnet 4: 25 de agosto – 2 de septiembre
La causa técnica fue un error de generación de tokens que asignó una alta probabilidad a caracteres que no tenían negocio allí. Literalmente rompió el mecanismo fundamental de cómo Claude selecciona la próxima palabra para decir.
Error #3: El error del compilador invisible
Este es el más aterrador desde una perspectiva de ingeniería. Había un error latente en el compilador XLA de Google que había estado dormido. Cuando Anthropic desplegó código para mejorar la selección de tokens el 25 de agosto, accidentalmente lo activaron.
Lo que hizo este error fue genuinamente extraño – haría que Claude excluyera involuntariamente el token más probable al generar texto. Claude sabía la respuesta correcta pero estaba físicamente impedido para decirla.
La parte realmente desordenada es que habían trabajado alrededor de este error en diciembre de 2024 sin darse cuenta. Cuando “arreglaron” lo que pensaban que era la causa raíz en agosto, eliminaron el trabajo alrededor y desencadenaron el problema real.
Por qué tardó seis semanas en arreglar
Puedes estar preguntándote: ¿cómo es que una empresa como Anthropic, con ingenieros de clase mundial, tarda seis semanas en figurarlo?
La respuesta revela justo lo complejos que son estos sistemas en realidad:
1. Los controles de privacidad bloquearon la depuración
“Nuestros controles internos de privacidad y seguridad limitan cómo y cuándo los ingenieros pueden acceder a las interacciones del usuario con Claude, en particular cuando esas interacciones no se informan como comentarios.”
Literalmente no podían ver qué se estaba rompiendo a menos que los usuarios lo informaran explícitamente con comentarios. Bueno para la privacidad, terrible para la depuración.
2. Los errores se escondieron
Claude a menudo se recuperaba de errores individuales, haciendo que la degradación pareciera variación normal en lugar de falla sistemática. Sus benchmarks y evaluaciones no estaban capturando porque el modelo se autocorregiría lo suficiente para aprobar las pruebas.
3. Caos multiplataforma
Claude se ejecuta en AWS Trainium, NVIDIA GPUs y Google TPUs – tres plataformas de hardware completamente diferentes. Cada error se manifestó de manera diferente en cada plataforma:
- AWS Bedrock: 0,18% de las solicitudes de Sonnet 4 afectadas en el pico
- Google Vertex AI: Por debajo del 0,0004% afectado
- API directa: Hasta el 16% afectado
Esto hizo que pareciera que había múltiples problemas no relacionados en lugar de tres errores específicos.
4. Síntomas superpuestos
Con tres errores activos simultáneamente, los síntomas estaban por todas partes. Un usuario podría obtener caracteres tailandeses, otro podría obtener respuestas degradadas, un tercero podría ver un rendimiento perfecto. No había un patrón claro que seguir.
Qué significa esto realmente para la confiabilidad de la IA
Esta saga revela algo crucial sobre el estado actual de los sistemas de IA: son mucho más frágiles de lo que parecen.
No solo estamos hablando del modelo de IA en sí. Estamos hablando de:
- Infraestructura de enrutamiento que puede enviar solicitudes al lugar equivocado
- Implementaciones específicas de hardware que se comportan de manera diferente
- Errores del compilador que pueden estar dormidos durante meses
- Equilibradores de carga que pueden amplificar problemas menores en interrupciones mayores
Un error de configuración, un error del compilador, un error de enrutamiento – y de repente tu asistente de IA se olvida de cómo codificar o comienza a hablar idiomas que no debería.
¿Está realmente arreglado?
Anthropic dice que ha resuelto los tres problemas a partir del 16 de septiembre. Han:
- Arreglado la lógica de enrutamiento
- Revertido las configuraciones problemáticas
- Cambiado de operaciones top-k aproximadas a exactas (asumiendo un golpe en el rendimiento por la precisión)
- Agregado monitoreo de producción continuo
Pero los usuarios todavía están informando problemas. Algunos desarrolladores afirman que Claude Code todavía se siente degradado en comparación con su rendimiento anterior. Ya sea que:
- Efectos residuales de los errores
- Nuevos problemas que no han sido identificados
- Sesgo psicológico después de semanas de problemas
- O degradación real continuada
…no lo sabemos todavía.
La parte inferior
Esta situación es un caso de estudio perfecto de cómo pueden fallar los sistemas de IA complejos de maneras completamente inesperadas. Tres errores separados, todos activados dentro de semanas, crearon una percepción de degradación de calidad masiva que tomó seis semanas diagnosticar y arreglar.
Podemos dar algún crédito a Anthropic por la transparencia. Publicar un informe técnico post-mortem detallado es más de lo que la mayoría de las empresas harían. Pero también muestra cuánto puede salir mal bajo el capó de estos sistemas en los que estamos cada vez más dependientes.
Para cualquiera que esté construyendo sobre Claude o cualquier LLM: necesitas redundancia, validación y planes de respaldo. Porque como acabamos de ver, incluso los mejores sistemas de IA pueden tener tres problemas diferentes simultáneamente, y puede tomar semanas antes de que alguien figure out qué está sucediendo realmente.
La infraestructura que soporta estos modelos de IA es tan importante como los modelos en sí. Y ahora, esa infraestructura está mostrando algunos dolores de crecimiento graves.












