Inteligencia artificial
Crear una Red Adversaria Generativa Personalizada con Bocetos

Los investigadores de Carnegie Mellon y MIT han desarrollado una nueva metodología que permite a un usuario crear sistemas de creación de imágenes de Red Adversaria Generativa (GAN) personalizados simplemente dibujando bocetos indicativos.
Un sistema de este tipo podría permitir que un usuario final cree sistemas de generación de imágenes capaces de generar imágenes muy específicas, como animales particulares, tipos de edificios e incluso personas individuales. Actualmente, la mayoría de los sistemas de generación de GAN producen una salida amplia y bastante aleatoria, con una capacidad limitada para especificar características particulares, como la raza de un animal, los tipos de cabello en las personas, los estilos de arquitectura o las identidades faciales reales.
El enfoque, descrito en el artículo Dibujar tu propia GAN, utiliza una nueva interfaz de dibujo como una función de “búsqueda” efectiva para encontrar características y clases en bases de datos de imágenes que pueden contener miles de tipos de objetos, incluyendo muchos subtipos que no son relevantes para la intención del usuario. La GAN se entrena luego en este subconjunto filtrado de imágenes.
Al dibujar el tipo de objeto específico con el que el usuario desea calibrar la GAN, las capacidades generativas del marco se especializan en esa clase. Por ejemplo, si un usuario desea crear un marco que genere un tipo específico de gato (en lugar de cualquier gato viejo, como se puede obtener con This Cat Does Not Exist), sus bocetos de entrada sirven como un filtro para descartar clases no relevantes de gatos.

Fuente: https://peterwang512.github.io/GANSketching/
La investigación está liderada por Sheng Yu-Wang de la Universidad Carnegie Mellon, junto con su colega Jun-Yan Zhu, y David Bau del Laboratorio de Ciencia y Inteligencia Artificial de MIT.
El método en sí se llama “dibujado de GAN”, y utiliza los bocetos de entrada para cambiar directamente los pesos de un modelo de GAN de “plantilla” para apuntar específicamente al dominio o subdominio identificado a través de pérdida adversaria entre dominios.
Se exploraron diferentes métodos de regularización para asegurarse de que la salida del modelo sea diversa, mientras se mantiene una alta calidad de imagen. Los investigadores crearon aplicaciones de ejemplo que pueden interpolarse en el espacio latente y realizar procedimientos de edición de imágenes.
Este [$class] no existe
Los sistemas de generación de imágenes basados en GAN se han convertido en una moda, si no en un meme, en los últimos años, con una proliferación de proyectos capaces de generar imágenes de cosas no existentes, incluyendo personas, apartamentos de alquiler, aperitivos, pies, caballos, políticos e insectos, entre muchos otros.
Los sistemas de síntesis de imágenes basados en GAN se crean compilando o curando conjuntos de datos extensos que contienen imágenes del dominio objetivo, como caras o caballos; entrenando modelos que generalizan una serie de características en las imágenes de la base de datos; e implementando módulos generadores que pueden producir ejemplos aleatorios basados en las características aprendidas.

Salida de bocetos en DeepFacePencil, que permite a los usuarios crear caras fotorealistas a partir de bocetos. Muchos proyectos similares de boceto a imagen existen. Fuente: https://arxiv.org/pdf/2008.13343.pdf
Las características de alta dimensión son las primeras en concretarse durante el proceso de entrenamiento, y son equivalentes a los primeros trazos amplios de color de un pintor en una tela. Estas características de alta dimensión eventualmente se correlacionarán con características más detalladas (es decir, el brillo del ojo y los bigotes afilados de un gato, en lugar de un simple blob beige que representa la cabeza).
Sé lo que quieres decir…
Al mapear la relación entre estas formas seminales anteriores y las interpretaciones detalladas que se obtienen mucho más tarde en el proceso de entrenamiento, es posible inferir relaciones entre imágenes “vagas” y “específicas”, lo que permite a los usuarios crear imágenes complejas y fotorealistas a partir de bocetos toscos.
Recientemente, NVIDIA lanzó una versión de escritorio de su investigación a largo plazo GauGAN sobre generación de paisajes basada en GAN, que demuestra fácilmente este principio:
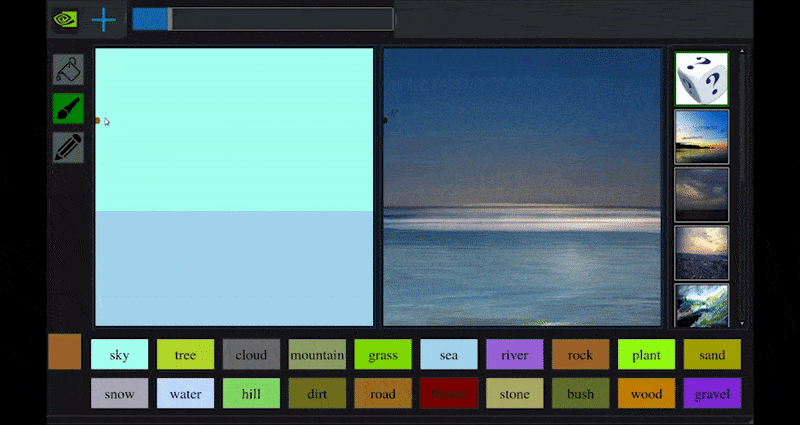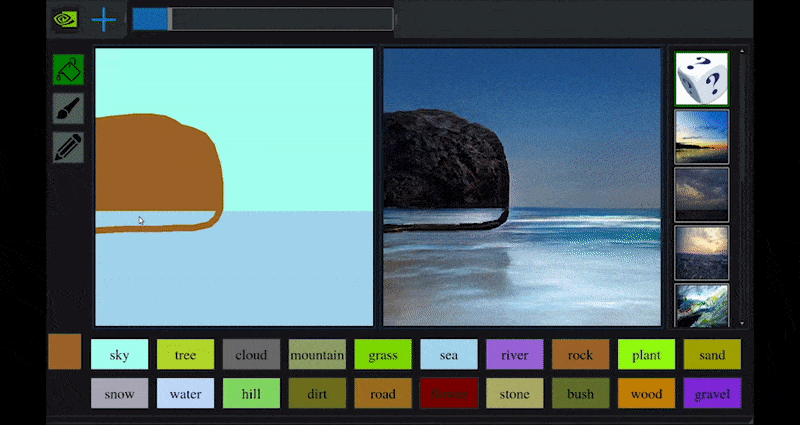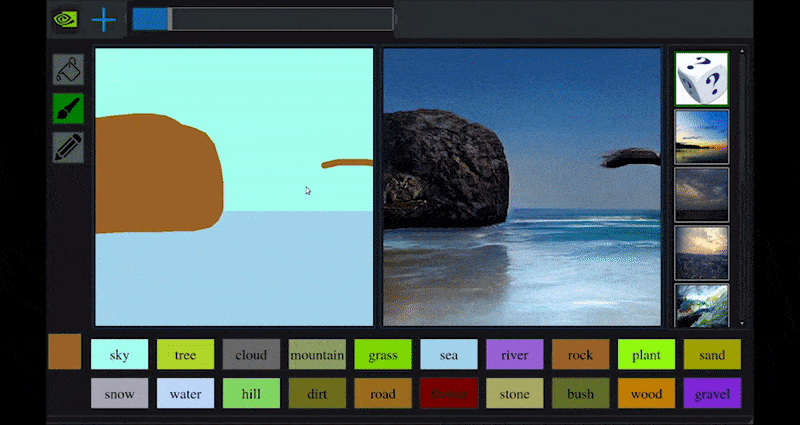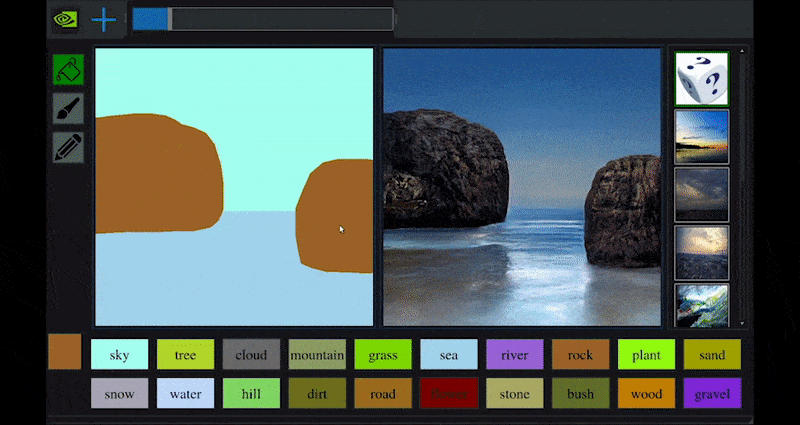
Approximaciones de bocetos se traducen en ricas imágenes escénicas a través de NVIDIA’s GauGAN, y ahora la aplicación NVIDIA Canvas. Fuente: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
De manera similar, múltiples sistemas como DeepFacePencil han utilizado el mismo principio para crear generadores de imágenes fotorealistas inducidos por bocetos para varios dominios.

La arquitectura de DeepFacePencil.
Simplificando Boceto-a-Imagen
El enfoque de GAN Sketching busca eliminar la formidable carga de recopilación y curación de datos que normalmente se involucra en el desarrollo de marcos de imagen de GAN, utilizando la entrada del usuario para definir qué subconjunto de imágenes debe constituir los datos de entrenamiento.
El sistema ha sido diseñado para requerir solo un pequeño número de bocetos de entrada para calibrar el marco. El sistema efectivamente invierte la funcionalidad de PhotoSketch, una iniciativa de investigación conjunta de 2019 por investigadores de Carnegie Mellon, Adobe, Uber ATG y Argo AI, que se incorpora en el nuevo trabajo. PhotoSketch fue diseñado para crear bocetos artísticos a partir de imágenes, y ya contiene el mapeo efectivo de relaciones de creación de imágenes vagas a específicas.
Para la parte de generación del proceso, el nuevo método solo modifica los pesos de StyleGAN2. Dado que los datos de imagen que se utilizan son solo un subconjunto de los datos totales disponibles, modificar solo la red de mapeo obtiene resultados deseables.
El método se evaluó en una serie de subdominios populares, incluyendo ecuestre, iglesias y gatos.

El conjunto de datos LSUN de la Universidad de Princeton de 2016 se utilizó como material principal para derivar subdominios objetivo. Para establecer un sistema de mapeo de bocetos que sea robusto a las excentricidades de la entrada del usuario en el mundo real, el sistema se entrena en imágenes del conjunto de datos QuickDraw desarrollado por Microsoft entre 2021-2016.
Aunque el mapeo de bocetos entre PhotoSketch y QuickDraw son bastante diferentes, los investigadores encontraron que su marco tiene éxito en combinarlos con facilidad en poses relativamente simples, aunque las poses más complicadas (como gatos acostados) resultan más desafiantes, mientras que la entrada del usuario muy abstracta (es decir, dibujos demasiado toscos) también obstaculiza la calidad de los resultados.

Espacio Latente y Edición de Imágenes Naturales
Los investigadores desarrollaron dos aplicaciones basadas en el trabajo principal: edición de espacio latente y edición de imágenes. La edición de espacio latente ofrece controles de usuario interpretables que se facilitan en el momento del entrenamiento, y permiten un amplio grado de variación mientras se mantienen fieles al dominio objetivo, y agradables y consistentes en las variaciones.

Interpolación suave del espacio latente con los modelos personalizados de GAN Sketching.
El componente de edición de espacio latente fue alimentado por el proyecto GANSpace de 2020, una iniciativa conjunta de la Universidad Aalto, Adobe y NVIDIA.
Una sola imagen también se puede alimentar al modelo personalizado, facilitando la edición de imágenes naturales. En esta aplicación, una sola imagen se proyecta al GAN personalizado, no solo permitiendo la edición directa, sino también preservando la edición de espacio latente de alto nivel, si esto también se ha utilizado.

Aquí, una imagen real se ha utilizado como entrada al GAN (modelo de gato), que edita la entrada para que coincida con los bocetos presentados. Esto permite la edición de imágenes a través del bocetado.
Aunque es configurable, el sistema no está diseñado para funcionar en tiempo real, al menos en términos de entrenamiento y calibración. Actualmente, GAN Sketching requiere 30,000 iteraciones de entrenamiento. El sistema también requiere acceso a los datos de entrenamiento originales para el modelo original.
En casos donde el conjunto de datos es de código abierto y tiene una licencia que permite la copia local, esto podría acomodarse incluyendo los datos de origen en un paquete instalado localmente, aunque esto ocuparía un espacio de disco considerable; o accediendo o procesando datos de forma remota, a través de un enfoque basado en la nube, lo que introduce sobrecargas de red y (en el caso de que el procesamiento ocurra en la nube) posibles consideraciones de costo de cómputo.

Transformaciones de modelos FFHQ personalizados entrenados con solo 4 bocetos generados por humanos.












