Inteligencia artificial
Enfabrica Presenta una Memoria de Tela Basada en Ethernet que Podría Redefinir la Inferencia de IA a Gran Escala
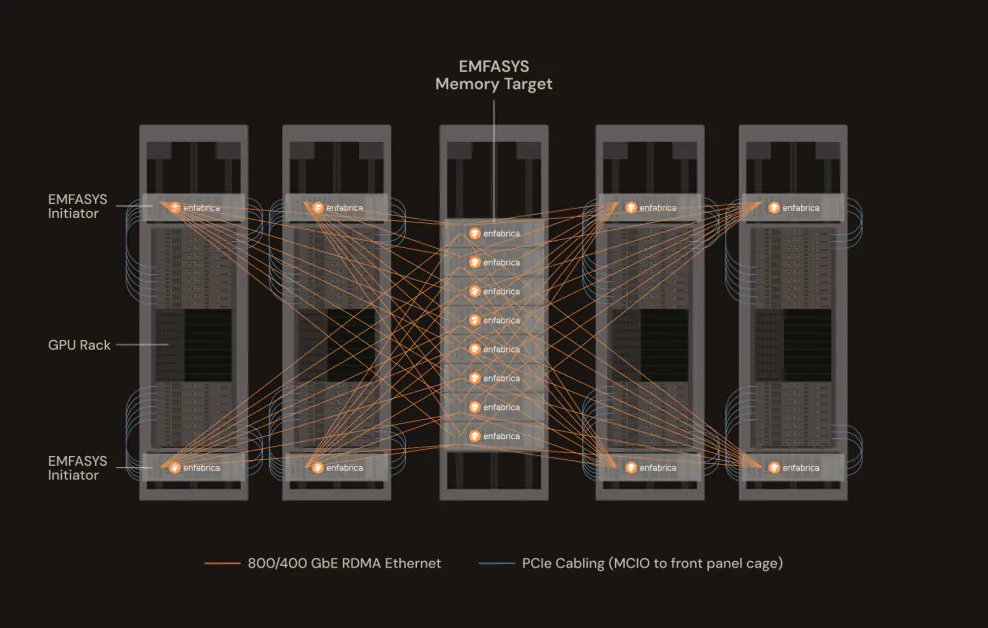
Enfabrica, una startup con sede en Silicon Valley respaldada por Nvidia, ha presentado un producto innovador que puede cambiar significativamente la forma en que se despliegan y escalan las cargas de trabajo de IA a gran escala. El nuevo sistema de tela de memoria elástica (EMFASYS) de la empresa es el primer sistema de tela de memoria basado en Ethernet disponible comercialmente, diseñado específicamente para abordar el cuello de botella principal de la inferencia de IA generativa: el acceso a la memoria.
En un momento en que los modelos de IA están creciendo en complejidad, conciencia contextual y persistencia, requiriendo vastas cantidades de memoria por sesión de usuario, EMFASYS ofrece un enfoque novedoso para desacoplar la memoria del cálculo, lo que permite a los centros de datos de IA mejorar drásticamente el rendimiento, reducir costos y aumentar la utilización de sus recursos más costosos: las GPU.
¿Qué es una Tela de Memoria y Por Qué Es Importante?
Tradicionalmente, la memoria dentro de los centros de datos ha estado estrechamente vinculada al servidor o nodo en el que reside. Cada GPU o CPU solo tiene acceso a la memoria de alta velocidad directamente conectada a ella, generalmente HBM para GPUs o DRAM para CPUs. Esta arquitectura funciona bien cuando las cargas de trabajo son pequeñas y predecibles. Pero la IA generativa ha cambiado el juego. Los LLM requieren acceso a ventanas de contexto grandes, historial de usuario y memoria multiagente, todo lo cual debe procesarse rápidamente y sin retraso. Estas demandas de memoria a menudo superan la capacidad disponible de la memoria local, creando cuellos de botella que dejan inactivas las GPU y aumentan los costos de infraestructura.
Una tela de memoria resuelve esto transformando la memoria en un recurso compartido y distribuido, una especie de memoria conectada a la red accesible por cualquier GPU o CPU en el clúster. Piense en ello como crear una “nube de memoria” dentro del rack del centro de datos. En lugar de replicar la memoria en los servidores o sobrecargar la costosa HBM, una tela permite que la memoria se agregue, se desagregue y se acceda bajo demanda a través de una red de alta velocidad. Esto permite que las cargas de trabajo de inferencia de IA se escalen de manera más eficiente sin estar limitadas por los límites de memoria física de un solo nodo.
El Enfoque de Enfabrica: Ethernet y CXL, Juntos al Fin
EMFASYS logra esta arquitectura de memoria a nivel de rack combinando dos tecnologías poderosas: RDMA sobre Ethernet y Compute Express Link (CXL). El primero permite la transferencia de datos de ultra baja latencia y alta velocidad a través de redes Ethernet estándar. El segundo permite que la memoria se separe de las CPUs y las GPUs y se acumule en recursos compartidos, accesibles a través de enlaces CXL de alta velocidad.
En el núcleo de EMFASYS se encuentra el chip ACF-S de Enfabrica, un “SuperNIC” de 3,2 terabits por segundo (Tbps) que fusiona el control de red y memoria en un solo dispositivo. Este chip permite a los servidores interactuar con grandes cantidades de memoria DRAM de commodity de hasta 18 terabytes por nodo, distribuidas a lo largo del rack. Crucialmente, lo hace utilizando puertos Ethernet estándar, lo que permite a los operadores aprovechar su infraestructura de centro de datos existente sin invertir en interconexiones propietarias.
Lo que hace que EMFASYS sea particularmente atractivo es su capacidad para descargar dinámicamente las cargas de trabajo limitadas por la memoria de las GPU costosas con HBM a DRAM mucho más asequible, manteniendo al mismo tiempo una latencia de acceso a nivel de microsegundo. La pila de software detrás de EMFASYS incluye mecanismos de caché inteligentes y equilibrio de carga que ocultan la latencia y orquestan el movimiento de memoria de manera transparente para los LLM que se ejecutan en el sistema.
Implicaciones para la Industria de la IA
Esto es más que una solución de hardware inteligente, representa un cambio filosófico en la forma en que se construye y escala la infraestructura de IA. A medida que la IA generativa pasa de ser una novedad a una necesidad, con miles de millones de consultas de usuario procesadas diariamente, el costo de servir estos modelos se ha vuelto insostenible para muchas empresas. Las GPU a menudo están subutilizadas no por falta de cálculo, sino porque permanecen inactivas esperando a la memoria. EMFASYS aborda directamente este desequilibrio.
Al permitir que la memoria se conecte a la red y se acceda a través de Ethernet, Enfabrica ofrece a los operadores de centros de datos una alternativa escalable a la compra continua de más GPU o HBM. En lugar de eso, pueden aumentar la capacidad de memoria de manera modular, utilizando DRAM y networking inteligente, reduciendo la huella general y mejorando la economía de la inferencia de IA.
Las implicaciones van más allá de los ahorros de costos inmediatos. Esta arquitectura desagregada allana el camino para modelos de memoria como servicio, donde el contexto, el historial y el estado del agente pueden persistir más allá de una sola sesión o servidor, abriendo la puerta a sistemas de IA más inteligentes y personalizados. También establece el escenario para nubes de IA más resilientes, donde las cargas de trabajo se pueden distribuir elásticamente a través de un rack o de todo el centro de datos sin rigurosas limitaciones de memoria.
Mirando Hacia Adelante
El EMFASYS de Enfabrica está actualmente en fase de muestreo con clientes seleccionados, y aunque la empresa no ha divulgado quiénes son esos socios, Reuters informa que los principales proveedores de nube de IA ya están pilotando el sistema. Esto posiciona a Enfabrica no solo como un proveedor de componentes, sino como un habilitador clave en la próxima generación de infraestructura de IA.
Al desacoplar la memoria del cálculo y hacerla accesible a través de redes Ethernet de alta velocidad y de commodity, Enfabrica está sentando las bases para una nueva era de arquitectura de IA, una en la que la inferencia puede escalarse sin compromiso, donde los recursos ya no están limitados y donde la economía de la implementación de grandes modelos de lenguaje finalmente comienza a tener sentido.
En un mundo cada vez más definido por sistemas de IA ricos en contexto y multiagente, la memoria ya no es un actor de apoyo, es el escenario. Y Enfabrica está apostando por que quien construya el mejor escenario definirá el rendimiento de la IA durante años por venir.












