Inteligencia artificial
Incrustaciones de Código: Una Guía Completa

Las incrustaciones de código son una forma transformadora de representar fragmentos de código como vectores densos en un espacio continuo. Estas incrustaciones capturan las relaciones semánticas y funcionales entre fragmentos de código, lo que permite aplicaciones poderosas en la programación asistida por IA. Similar a las incrustaciones de palabras en el procesamiento de lenguaje natural (NLP), las incrustaciones de código posicionan fragmentos de código similares cerca uno del otro en el espacio vectorial, lo que permite a las máquinas entender y manipular el código de manera más efectiva.
¿Qué son las Incrustaciones de Código?
Las incrustaciones de código convierten estructuras de código complejas en vectores numéricos que capturan el significado y la funcionalidad del código. A diferencia de los métodos tradicionales que tratan el código como secuencias de caracteres, las incrustaciones capturan las relaciones semánticas entre partes del código. Esto es crucial para diversas tareas de ingeniería de software impulsadas por IA, como la búsqueda de código, la finalización de código, la detección de errores y más.
Por ejemplo, consideremos estas dos funciones de Python:
def add_numbers(a, b): return a + b
<p>def sum_two_values(x, y): result = x + y return result</p>
Aunque estas funciones se ven diferentes sintácticamente, realizan la misma operación. Una buena incrustación de código representaría estas dos funciones con vectores similares, capturando su similitud funcional a pesar de sus diferencias textuales.

Vector Embedding
¿Cómo se Crean las Incrustaciones de Código?
Hay diferentes técnicas para crear incrustaciones de código. Un enfoque común implica el uso de redes neuronales para aprender estas representaciones a partir de un conjunto de datos grande de código. La red analiza la estructura del código, incluyendo tokens (palabras clave, identificadores), sintaxis (cómo se estructura el código) y posiblemente comentarios para aprender las relaciones entre diferentes fragmentos de código.
Desglosemos el proceso:
- Código como Secuencia: Primero, los fragmentos de código se tratan como secuencias de tokens (variables, palabras clave, operadores).
- Entrenamiento de la Red Neuronal: Una red neuronal procesa estas secuencias y aprende a mapearlas a representaciones vectoriales de tamaño fijo. La red considera factores como la sintaxis, la semántica y las relaciones entre elementos del código.
- Capturando Similitudes: El entrenamiento tiene como objetivo posicionar fragmentos de código similares (con funcionalidad similar) cerca uno del otro en el espacio vectorial. Esto permite tareas como encontrar código similar o comparar funcionalidad.
Aquí hay un ejemplo simplificado de Python de cómo se podría preprocesar el código para la incrustación:
import ast
<p>def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Agregar más tipos de nodos según sea necesario
return tokens</p>
<p># Ejemplo de uso
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Salida: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']</p>
Esta representación tokenizada se puede alimentar a una red neuronal para la incrustación.
Enfoques Existentes para la Incrustación de Código
Los métodos existentes para la incrustación de código se pueden clasificar en tres categorías principales:
Métodos Basados en Tokens
Los métodos basados en tokens tratan el código como una secuencia de tokens léxicos. Técnicas como la Frecuencia de Término-Inversa de la Frecuencia del Documento (TF-IDF) y modelos de aprendizaje profundo como CodeBERT caen en esta categoría.
Métodos Basados en Árboles
Los métodos basados en árboles analizan el código en árboles de sintaxis abstracta (AST) o otras estructuras de árbol, capturando las reglas sintácticas y semánticas del código. Ejemplos incluyen redes neuronales basadas en árboles y modelos como code2vec y ASTNN.
Métodos Basados en Grafos
Los métodos basados en grafos construyen grafos a partir del código, como grafos de flujo de control (CFG) y grafos de flujo de datos (DFG), para representar el comportamiento dinámico y las dependencias del código. GraphCodeBERT es un ejemplo notable.
TransformCode: Un Marco para la Incrustación de Código
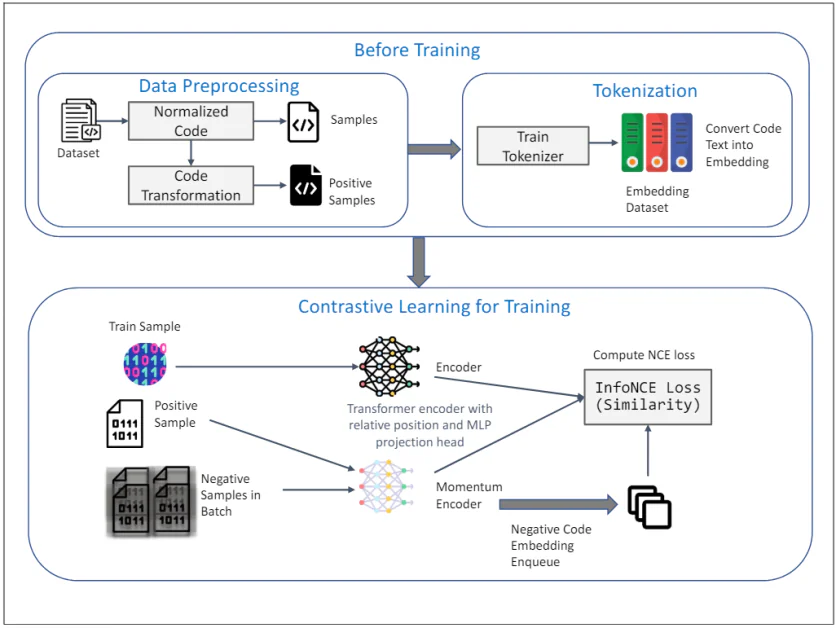
TransformCode: Aprendizaje no supervisado de incrustaciones de código
TransformCode es un marco que aborda las limitaciones de los métodos existentes aprendiendo incrustaciones de código de manera no supervisada mediante aprendizaje contrastivo. Es agnóstico al codificador y al lenguaje, lo que significa que puede aprovechar cualquier modelo de codificador y manejar cualquier lenguaje de programación.
El diagrama anterior ilustra el marco de TransformCode para el aprendizaje no supervisado de incrustaciones de código mediante aprendizaje contrastivo. Consiste en dos fases principales: Antes del Entrenamiento y Aprendizaje Contrastivo para el Entrenamiento. A continuación, se proporciona una explicación detallada de cada componente:
Antes del Entrenamiento
1. Preprocesamiento de Datos:
- Conjunto de Datos: La entrada inicial es un conjunto de datos que contiene fragmentos de código.
- Código Normalizado: Los fragmentos de código se normalizan para eliminar comentarios y renombrar variables a un formato estándar. Esto ayuda a reducir la influencia de la nomenclatura de variables en el proceso de aprendizaje y mejora la generalización del modelo.
- Transformación de Código: El código normalizado se transforma utilizando varias transformaciones sintácticas y semánticas para generar muestras positivas. Estas transformaciones garantizan que el significado semántico del código permanece sin cambios, proporcionando muestras diversas y robustas para el aprendizaje contrastivo.
2. Tokenización:
- Entrenar Tokenizador: Un tokenizador se entrena en el conjunto de datos de código para convertir el texto de código en incrustaciones. Esto implica descomponer el código en unidades más pequeñas, como tokens, que pueden ser procesadas por el modelo.
- Conjunto de Datos de Incrustaciones: El tokenizador entrenado se utiliza para convertir el conjunto de datos de código completo en incrustaciones, que sirven como entrada para la fase de aprendizaje contrastivo.
Aprendizaje Contrastivo para el Entrenamiento
3. Proceso de Entrenamiento:
- Muestra de Entrenamiento: Una muestra del conjunto de datos de entrenamiento se selecciona como la representación de código de consulta.
- Muestra Positiva: La muestra positiva correspondiente es la versión transformada de la consulta de código, obtenida durante la fase de preprocesamiento de datos.
- Muestras Negativas en el Lote: Las muestras negativas son todas las demás muestras de código en el lote actual que son diferentes de la muestra positiva.
4. Codificador y Codificador de Momentum:
- Codificador de Transformador con Codificación de Posición Relativa y Cabeza de Proyección MLP: Tanto la consulta como las muestras positivas se alimentan a un codificador de transformador. El codificador incorpora la codificación de posición relativa para capturar la estructura sintáctica y las relaciones entre tokens en el código. Una cabeza de proyección MLP se utiliza para mapear las representaciones codificadas a un espacio de dimensión inferior donde se aplica el objetivo de aprendizaje contrastivo.
- Codificador de Momentum: También se utiliza un codificador de momentum, que se actualiza mediante un promedio móvil de los parámetros del codificador de consulta. Esto ayuda a mantener la coherencia y la diversidad de las representaciones, evitando el colapso de la pérdida contrastiva. Las muestras negativas se codifican usando este codificador de momentum y se encolan para el proceso de aprendizaje contrastivo.
5. Objetivo de Aprendizaje Contrastivo:
- Computar la Pérdida InfoNCE (Similitud): La pérdida InfoNCE (Estimación de Contraste de Ruido) se computa para maximizar la similitud entre la consulta y las muestras positivas, mientras se minimiza la similitud entre la consulta y las muestras negativas. Este objetivo garantiza que las incrustaciones aprendidas sean discriminatorias y robustas, capturando la similitud semántica de los fragmentos de código.
El marco completo aprovecha las fortalezas del aprendizaje contrastivo para aprender incrustaciones de código significativas y robustas a partir de datos no etiquetados. El uso de transformaciones de AST y un codificador de momentum mejora aún más la calidad y la eficiencia de las representaciones aprendidas, convirtiendo a TransformCode en una herramienta poderosa para diversas tareas de ingeniería de software.
Características Clave de TransformCode
- Flexibilidad y Adaptabilidad: Puede extenderse a diversas tareas posteriores que requieren representación de código.
- Eficiencia y Escalabilidad: No requiere un modelo grande o datos de entrenamiento extensos, soporta cualquier lenguaje de programación.
- Aprendizaje No Supervisado y Supervisado: Puede aplicarse a ambos escenarios de aprendizaje incorporando etiquetas o objetivos específicos de la tarea.
- Parámetros Ajustables: La cantidad de parámetros del codificador puede ajustarse según los recursos de cómputo disponibles.
TransformCode introduce una técnica de aumento de datos llamada transformación de AST, aplicando transformaciones sintácticas y semánticas a los fragmentos de código originales. Esto genera muestras diversas y robustas para el aprendizaje contrastivo.
Aplicaciones de las Incrustaciones de Código
Las incrustaciones de código han revolucionado varios aspectos de la ingeniería de software al transformar el código de un formato textual a una representación numérica que las máquinas pueden utilizar. A continuación, se presentan algunas aplicaciones clave:
Búsqueda de Código Mejorada
Tradicionalmente, la búsqueda de código dependía del emparejamiento de palabras clave, lo que a menudo llevaba a resultados irrelevantes. Las incrustaciones de código permiten la búsqueda semántica, donde los fragmentos de código se clasifican según su similitud en funcionalidad, incluso si utilizan diferentes palabras clave. Esto mejora significativamente la precisión y la eficiencia de encontrar código relevante dentro de grandes bases de código.
Finalización de Código más Inteligente
Las herramientas de finalización de código sugieren fragmentos de código relevantes según el contexto actual. Al aprovechar las incrustaciones de código, estas herramientas pueden proporcionar sugerencias más precisas y útiles al entender el significado semántico del código que se está escribiendo. Esto se traduce en experiencias de codificación más rápidas y productivas.
Corrección de Código Automatizada y Detección de Errores
Las incrustaciones de código se pueden utilizar para identificar patrones que a menudo indican errores o ineficiencias en el código. Al analizar la similitud entre fragmentos de código y patrones de errores conocidos, estos sistemas pueden sugerir automáticamente correcciones o resaltar áreas que pueden requerir una inspección más detallada.
Resumen de Código y Generación de Documentación Mejorados
Las grandes bases de código a menudo carecen de documentación adecuada, lo que dificulta que los nuevos desarrolladores comprendan su funcionamiento. Las incrustaciones de código pueden crear resúmenes concisos que capturan la esencia de la funcionalidad del código. Esto no solo mejora la mantenibilidad del código sino que también facilita la transferencia de conocimientos dentro de los equipos de desarrollo.
Revisión de Código Mejorada
Las revisiones de código son fundamentales para mantener la calidad del código. Las incrustaciones de código pueden asistir a los revisores al resaltar posibles problemas y sugerir mejoras. Además, pueden facilitar comparaciones entre diferentes versiones de código, lo que hace que el proceso de revisión sea más eficiente.
Procesamiento de Código entre Lenguajes
El mundo del desarrollo de software no se limita a un solo lenguaje de programación. Las incrustaciones de código tienen el potencial de facilitar tareas de procesamiento de código entre lenguajes. Al capturar las relaciones semánticas entre el código escrito en diferentes lenguajes, estas técnicas podrían permitir tareas como la búsqueda de código y el análisis entre lenguajes de programación.












