Inteligencia Artificial
Adobe Research amplía la edición de caras GAN desenredada

No es difícil entender por qué. enredo Es un problema en la síntesis de imágenes, porque suele ser un problema en otros ámbitos de la vida; por ejemplo, es mucho más difícil quitar la cúrcuma de un curry que desechar el pepinillo de una hamburguesa, y es prácticamente imposible desdulzar una taza de café. Algunas cosas simplemente vienen empaquetadas.
Del mismo modo, el entrelazamiento es un obstáculo para las arquitecturas de síntesis de imágenes a las que idealmente les gustaría separar diferentes características y conceptos cuando utilizan el aprendizaje automático para crear o editar caras (o perros, barcos, o cualquier otro dominio).
Si pudieras separar hebras como edad , género, color de pelo, tono de piel, emoción, y así sucesivamente, tendrías los inicios de una verdadera instrumentalidad y flexibilidad en un marco que podría crear y editar imágenes de rostros a un nivel verdaderamente granular, sin arrastrar "pasajeros" no deseados a estas conversiones.

En el enredo máximo (arriba a la izquierda), todo lo que puede hacer es cambiar la imagen de una red GAN aprendida a la imagen de otra persona.
Se trata de utilizar eficazmente la última tecnología de visión por computadora con IA para lograr algo que se resolvió por otros medios. hace más de treinta años.
Con cierto grado de separación ("Separación media" en la imagen anterior), es posible realizar cambios basados en el estilo, como color de cabello, expresión, aplicación de cosméticos y rotación limitada de la cabeza, entre otros.

Fuente: FEAT: Edición de rostros con atención, febrero de 2022, https://arxiv.org/pdf/2202.02713.pdf
Ha habido una serie de intentos en los últimos dos años para crear entornos interactivos de edición de caras que permitan a un usuario cambiar las características faciales con controles deslizantes y otras interacciones tradicionales de la interfaz de usuario, manteniendo intactas las características principales de la cara objetivo al realizar adiciones o cambios. Sin embargo, esto ha resultado ser un desafío debido al entrelazamiento de características/estilos subyacentes en el espacio latente de la GAN.
Por ejemplo, la gafas El rasgo está frecuentemente enredado con el años de edad rasgo, lo que significa que agregar anteojos también podría 'envejecer' el rostro, mientras que envejecer el rostro podría agregar anteojos, dependiendo del grado de separación aplicado de las características de alto nivel (ver 'Prueba' a continuación para ver ejemplos).
Lo más notable es que ha sido casi imposible alterar el color del cabello y otras facetas del mismo sin recalcular las hebras y la disposición del mismo, lo que produce un efecto transicional "chisporroteante".

Fuente: demostración de InterFaceGAN (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Recorrido de GAN latente a latente
Un nuevo documento dirigido por Adobe entrado para WACV 2022 ofrece un enfoque novedoso a estos problemas subyacentes en un llamado Latente a latente: un mapeador aprendido para la edición de conservación de identidad de múltiples atributos faciales en imágenes generadas por StyleGAN.

Material complementario del artículo Latente a latente: un mapeador aprendido para la edición de conservación de identidad de múltiples atributos faciales en imágenes generadas por StyleGAN. Aquí vemos que las características básicas en la cara aprendida no se arrastran a cambios no relacionados. Vea el video completo incrustado al final del artículo para obtener mejores detalles y resolución. Fuente: https://www.youtube.com/watch?v=rf_61llRH0Q
El documento está dirigido por el científico aplicado de Adobe Siavash Khodadadeh, junto con otros cuatro investigadores de Adobe y un investigador del Departamento de Ciencias de la Computación de la Universidad de Florida Central.
El artículo es interesante en parte porque Adobe ha estado operando en este espacio durante algún tiempo y es tentador imaginar que esta funcionalidad ingrese a un proyecto de Creative Suite en los próximos años; pero principalmente porque la arquitectura creada para el proyecto adopta un enfoque diferente para mantener la integridad visual en un editor de rostros GAN mientras se aplican los cambios.
Los autores declaran:
'[Nosotros] entrenamos una red neuronal para realizar una transformación de latente a latente que encuentra la codificación latente correspondiente a la imagen con el atributo modificado. Como la técnica es de una sola vez, no se basa en una trayectoria lineal o no lineal del cambio gradual de los atributos.
“Al entrenar la red de extremo a extremo a lo largo de la tubería de generación completa, el sistema puede adaptarse a los espacios latentes de las arquitecturas de generadores estándar. Las propiedades de conservación, como el mantenimiento de la identidad de la persona, pueden codificarse en forma de pérdidas de formación.
'Una vez entrenada la red latente a latente, se puede reutilizar para imágenes arbitrarias sin necesidad de volver a entrenarla.'
Esta última parte significa que la arquitectura propuesta llega al usuario final en un estado finalizado. Aún necesita ejecutar una red neuronal en recursos locales, pero se pueden incorporar nuevas imágenes y estar listas para su modificación casi de inmediato, ya que el marco está lo suficientemente desacoplado como para no requerir entrenamiento adicional específico para cada imagen.
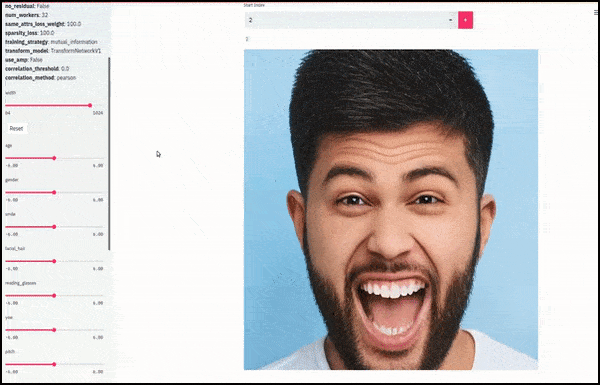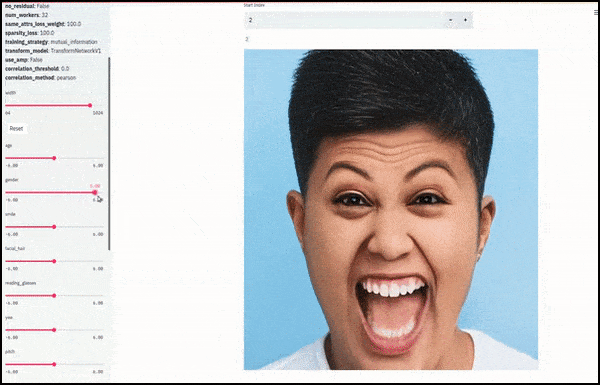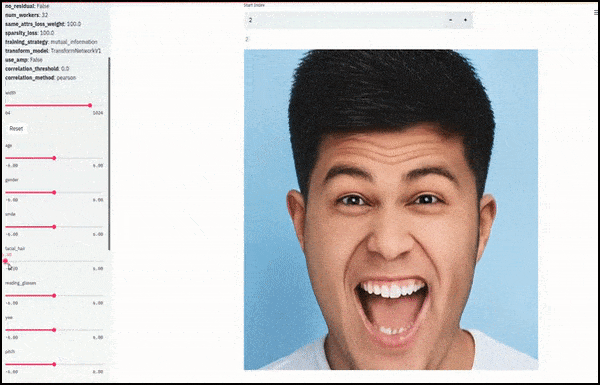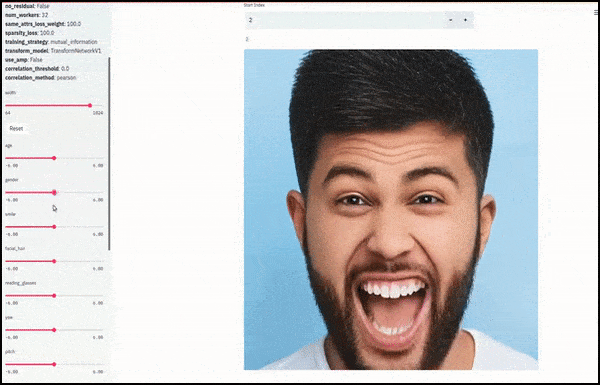
El género y el vello facial cambiaron a medida que los controles deslizantes trazaban rutas aleatorias y arbitrarias a través del espacio latente, no solo "desplazando" entre puntos finales. Vea el video incrustado al final del artículo para ver más transformaciones con mejor resolución.
Entre los principales logros del trabajo se encuentra la capacidad de la red de “congelar” identidades en el espacio latente cambiando únicamente el atributo en un vector objetivo y proporcionando “términos de corrección” que conservan las identidades que se están transformando.
Esencialmente, la red propuesta está integrada en una arquitectura más amplia que orquesta todos los elementos procesados, que pasan por componentes preentrenados con pesos congelados que no producirán efectos laterales no deseados en las transformaciones.
Dado que el proceso de formación se basa en trillizos que puede generarse mediante una imagen semilla (bajo inversión GAN) o una codificación latente inicial existente, todo el proceso de capacitación no está supervisado, con las acciones tácitas del rango habitual de sistemas de etiquetado y conservación en tales sistemas integrados de manera efectiva en la arquitectura. De hecho, el nuevo sistema utiliza regresores de atributos listos para usar:
El número de atributos que nuestra red puede controlar de forma independiente solo está limitado por las capacidades del/de los reconocedor(es). Si se dispone de un reconocedor para un atributo, podemos añadirlo a rostros arbitrarios. En nuestros experimentos, entrenamos la red latente a latente para permitir el ajuste de 35 atributos faciales diferentes, más que cualquier otro enfoque anterior.
El sistema incorpora una protección adicional contra transformaciones de "efectos secundarios" no deseadas: en ausencia de una solicitud de cambio de atributo, la red latente a latente mapeará un vector latente a sí misma, aumentando aún más la persistencia estable de la identidad objetivo.
Reconocimiento facial
Un problema recurrente con GAN y los editores de rostros basados en codificadores/descodificadores de los últimos años ha sido que las transformaciones aplicadas tienden a degradar la semejanza. Para combatir esto, el proyecto de Adobe utiliza una red de reconocimiento facial integrada llamada facenet como discriminador.

Arquitectura del proyecto, consulte la parte inferior central izquierda para ver la inclusión de FaceNet. Fuente: Latente a latente: un mapeador aprendido para la edición de conservación de identidad de múltiples atributos faciales en imágenes generadas por StyleGAN, Acceso abierto.
(En una nota personal, esto parece un movimiento alentador hacia la integración de la identificación facial estándar e incluso los sistemas de reconocimiento de expresión en redes generativas, posiblemente la mejor manera de superar el problema). píxel ciego>mapeo de píxel que domina las arquitecturas deepfake actuales a expensas de la fidelidad de expresión y otros dominios importantes en el sector de la generación de rostros).
Acceso a todas las areas en el espacio latente
Otra característica impresionante del framework es su capacidad para navegar arbitrariamente entre posibles transformaciones en el espacio latente, según el capricho del usuario. Varios sistemas anteriores que proporcionaban interfaces exploratorias solían dejar al usuario prácticamente "depurándose" entre plazos fijos de transformación de características; una experiencia impresionante, pero a menudo bastante lineal o prescriptiva.

De Mejora del equilibrio de GAN mediante el aumento de la conciencia espacial: aquí el usuario recorre un rango de posibles puntos de transición entre dos ubicaciones de espacio latente, pero dentro de los límites de las ubicaciones previamente entrenadas en el espacio latente. Para aplicar otros tipos de transformación basados en el mismo material, es necesaria la reconfiguración y/o reentrenamiento. Fuente: https://genforce.github.io/eqgan/
Además de ser receptivo a imágenes de usuario completamente nuevas, el usuario también puede congelar manualmente los elementos que desee conservar durante el proceso de transformación. De esta forma, puede garantizar que, por ejemplo, los fondos no se muevan o que los ojos se mantengan abiertos o cerrados.
Fecha
La red de regresión de atributos se entrenó en tres redes: FFHQ, CelebAMask-HQ, y una red local generada por GAN obtenida al muestrear 400,000 vectores del espacio Z de EstiloGAN-V2.
Las imágenes fuera de distribución (OOD) se filtraron y los atributos se extrajeron utilizando el software de Microsoft. API de cara, con el conjunto de imágenes resultante dividido 90/10, dejando 721,218 72,172 imágenes de entrenamiento y XNUMX XNUMX imágenes de prueba para comparar.
Pruebas
Aunque la red experimental se configuró inicialmente para acomodar 35 transformaciones potenciales, estas se redujeron a ocho para realizar pruebas análogas con los marcos comparables. InterfazGAN, GANEspacio y EstiloFlujo.
Los ocho atributos seleccionados fueron Edad, Calvicie, Barba, expresión, Género, Gafas, Paso y Guiñada. Fue necesario reorganizar los marcos de la competencia para algunos de los ocho atributos que no se aprovisionaron en la distribución original, como agregar calvicie y barba a InterFaceGAN.
Como era de esperar, se produjo un mayor nivel de entrelazamiento en las arquitecturas rivales. Por ejemplo, en una prueba, InterFaceGAN y StyleFlow cambiaron el género del sujeto cuando se les pidió que aplicaran edad :

Dos de los frameworks en competencia incorporaron un cambio de género en la transformación de "edad" y también cambiaron el color del cabello sin necesidad de que el usuario lo pidiera directamente.
Además, dos de los rivales encontraron que las gafas y la edad son facetas inseparables:

¡Gafas y cambio de color de cabello incluido sin cargo adicional!
No es una victoria uniforme para la investigación: como se puede ver en el video adjunto incluido al final del artículo, el marco es el menos efectivo cuando se intenta extrapolar diversos ángulos (guiñada), mientras que GANSpace tiene un mejor resultado general para edad y la imposición de gafas. El marco de latente a latente vinculado con GANSpace y StyleFlow con respecto a la adición de tono (ángulo de la cabeza).

Resultados calculados en base a una calibración del Detector de rostros MTCNN. Los resultados más bajos son mejores.
Para más detalles y una mejor resolución de los ejemplos, consulte el vídeo que acompaña al artículo a continuación.

Publicado por primera vez el 16 de febrero de 2022.












