Kunstig intelligens
Farerne ved at bruge citater til at godkende NLG-indhold

Udtalelse Natural Language Generation-modeller såsom GPT-3 er tilbøjelig til at 'hallucinere' materiale, som de præsenterer i forbindelse med faktuelle oplysninger. I en æra, der er ekstraordinært optaget af væksten af tekstbaserede falske nyheder, repræsenterer disse "ivrige efter at behage" fantasiflugter en eksistentiel hindring for udviklingen af automatiserede skrive- og resumésystemer og for fremtidens AI-drevet journalistik, blandt forskellige andre undersektorer af Natural Language Processing (NLP).
Det centrale problem er, at sprogmodeller i GPT-stil udleder nøglefunktioner og klasser fra meget store korpus af træningstekster, og lær at bruge disse funktioner som byggesten i sproget behændigt og autentisk, uanset det genererede indholds nøjagtighed, eller endda dets acceptabilitet.
NLG-systemer er derfor i øjeblikket afhængige af menneskelig verifikation af fakta i en af to tilgange: at modellerne enten bruges som frøtekstgeneratorer, der straks videregives til menneskelige brugere, enten til verifikation eller en anden form for redigering eller tilpasning; eller at mennesker bruges som dyre filtre til at forbedre kvaliteten af datasæt, der er beregnet til at informere mindre abstrakte og 'kreative' modeller (som i sig selv uundgåeligt stadig er svære at stole på med hensyn til faktuel nøjagtighed, og som vil kræve yderligere lag af menneskelig overvågning) .
Gamle nyheder og falske fakta
Natural Language Generation (NLG)-modeller er i stand til at producere overbevisende og plausibelt output, fordi de har lært semantisk arkitektur, snarere end mere abstrakt at assimilere den faktiske historie, videnskab, økonomi eller et hvilket som helst andet emne, som de kan blive bedt om at udtale sig om, hvilket er effektivt viklet ind som "passagerer" i kildedataene.
Den faktuelle nøjagtighed af den information, som NLG-modeller genererer, forudsætter, at input, som de er trænet i, i sig selv er pålidelige og opdaterede, hvilket udgør en ekstraordinær byrde i form af forbehandling og yderligere menneskebaseret verifikation – en omkostningsfuld anstødssten, som NLP-forskningssektoren i øjeblikket adresserer på mange fronter.
GPT-3-skala-systemer tager ekstraordinært meget tid og penge at træne, og når de først er trænet, er de svære at opdatere på, hvad der kan betragtes som "kerneniveau". Selvom sessionsbaserede og brugerbaserede lokale ændringer kan øge anvendeligheden og nøjagtigheden af de implementerede modeller, er disse nyttige fordele vanskelige, nogle gange umulige at overføre til kernemodellen uden at nødvendiggøre hel eller delvis genoptræning.
Af denne grund er det svært at skabe trænede sprogmodeller, der kan gøre brug af den nyeste information.

Text-davinci-002, der er uddannet selv før COVID-indkomsten – gentagelsen af GPT-3, som anses for 'mest dygtig' af dets skaber OpenAI – kan behandle 4000 tokens pr. anmodning, men kender intet til COVID-19 eller den ukrainske indtrængen i 2022 (disse meddelelser og svar er fra 5. april 2022). Interessant nok er 'ukendt' faktisk et acceptabelt svar i begge fejltilfælde, men yderligere prompter fastslår let, at GPT-3 er uvidende om disse hændelser. Kilde: https://beta.openai.com/playground
En trænet model kan kun få adgang til 'sandheder', som den internaliserede på træningstidspunktet, og det er svært at få en nøjagtig og relevant citat som standard, når man forsøger at få modellen til at bekræfte sine påstande. Den reelle fare ved at indhente citater fra standard GPT-3 (for eksempel) er, at den nogle gange producerer korrekte citater, hvilket fører til en falsk tillid til denne facet af dens muligheder:

Top, tre nøjagtige citater opnået af 2021-æraen davinci-instruct-text GPT-3. I midten undlader GPT-3 at citere et af Einsteins mest berømte citater ("Gud spiller ikke terninger med universet") på trods af en ikke-kryptisk prompt. Nederst tildeler GPT-3 et skandaløst og fiktivt citat til Albert Einstein, tilsyneladende overspil fra tidligere spørgsmål om Winston Churchill i samme session. Kilde: Forfatterens egen artikel fra 2021 på https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
I håb om at løse denne generelle mangel i NLG-modeller foreslog Googles DeepMind for nylig GopherCite, en 280-milliarder parametermodel, der er i stand til at citere specifikke og nøjagtige beviser til støtte for sine genererede svar på prompter.


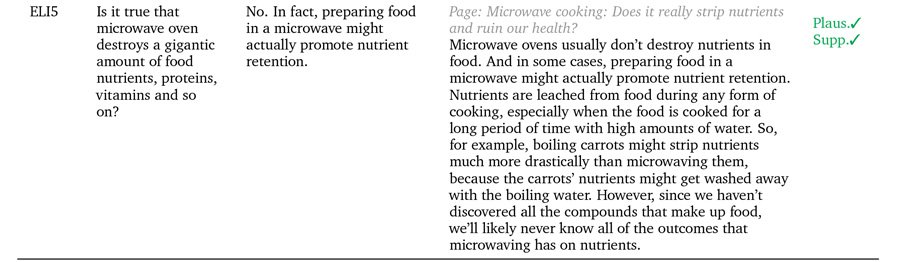
Tre eksempler på, at GopherCite understøtter sine påstande med rigtige citater. Kilde: https://arxiv.org/pdf/2203.11147.pdf
GopherCite udnytter forstærkende læring fra menneskelige præferencer (RLHP) til at træne forespørgselsmodeller, der er i stand til at citere rigtige citater som understøttende bevis. Citaterne er hentet live fra flere dokumentkilder hentet fra søgemaskiner eller fra et specifikt dokument leveret af brugeren.
GopherCites ydeevne blev målt gennem menneskelig evaluering af modelsvar, som viste sig at være 'høj kvalitet' 80 % af tiden på Googles Naturlige spørgsmål datasæt, og 67% af tiden på EL5 datasæt.
Citerer falskheder
Men når testet mod Oxford University's Sandfærdig QA benchmark, blev GopherCites svar sjældent bedømt som sandfærdige i sammenligning med de menneskeligt kuraterede 'korrekte' svar.
Forfatterne antyder, at dette skyldes, at begrebet 'understøttede svar' ikke på nogen objektiv måde hjælper med at definere sandheden i sig selv, da nytten af kildecitater kan blive kompromitteret af andre faktorer, såsom muligheden for, at forfatteren af citatet er selv 'hallucinerende' (dvs. at skrive om fiktive verdener, producere reklameindhold eller på anden måde fantastisk uægte materiale.



GopherCite tilfælde, hvor plausibilitet ikke nødvendigvis er lig med 'sandhed'.
Det bliver effektivt nødvendigt at skelne mellem 'understøttet' og 'sand' i sådanne tilfælde. Den menneskelige kultur er i øjeblikket langt forud for maskinlæring med hensyn til brugen af metoder og rammer designet til at opnå objektive definitioner af sandhed, og selv der synes den oprindelige tilstand af "vigtig" sandhed at være påstand og marginal benægtelse.
Problemet er rekursivt i NLG-arkitekturer, der søger at udtænke definitive 'bekræftende' mekanismer: menneskestyret konsensus presses i brug som et benchmark for sandhed gennem outsourcet, AMT-modeller, hvor de menneskelige evaluatorer (og de andre mennesker, der mægler tvister mellem dem) er i sig selv delvis og forudindtaget.
For eksempel bruger de indledende GopherCite-eksperimenter en 'super-bedømmer'-model til at vælge de bedste menneskelige forsøgspersoner til at evaluere modellens output, idet man kun vælger de bedømmere, der scorede mindst 85 % i forhold til et kvalitetssikringssæt. Endelig blev 113 superbedømmere udvalgt til opgaven.
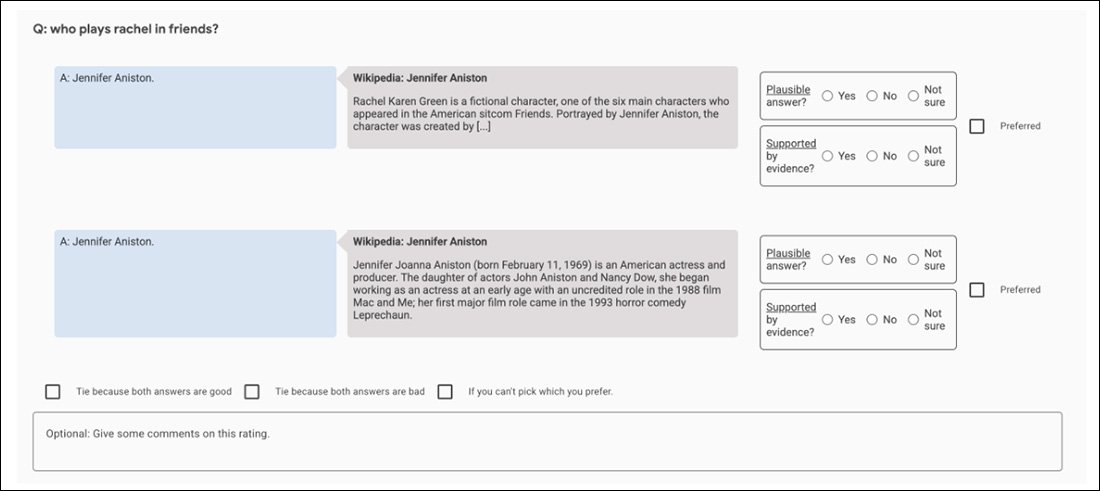
Skærmbillede af sammenligningsappen, der bruges til at hjælpe med at evaluere GopherCites output.
Dette er velsagtens et perfekt billede af en uvindelig fraktal jagt: Kvalitetssikringssættet, der bruges til at vurdere bedømmerne, er i sig selv en anden 'menneske-defineret' sandhedsmetrik, ligesom Oxford TruthfulQA-sættet, som GopherCite er blevet fundet mangelfuldt.
Hvad angår understøttet og 'autentificeret' indhold, er alt, hvad NLG-systemer kan håbe på at syntetisere fra træning i menneskelige data, menneskelig ulighed og mangfoldighed, i sig selv et dårligt stillet og uløst problem. Vi har en medfødt tendens til at citere kilder, der understøtter vores synspunkter, og til at tale autoritativt og med overbevisning i tilfælde, hvor vores kildeoplysninger kan være forældede, fuldstændig unøjagtige eller på anden måde bevidst forkert fremstillet på andre måder; og en tilbøjelighed til at sprede disse synspunkter direkte ud i naturen, i en skala og effektivitet, der er uovertruffen i menneskehedens historie, lige ind på vejen for de videnskrabende rammer, der fodrer nye NLG-rammer.
Derfor synes den fare, der er forbundet med udviklingen af citationsunderstøttede NLG-systemer, at være forbundet med kildematerialets uforudsigelige karakter. Enhver mekanisme (såsom direkte citat og citater), der øger brugernes tillid til NLG-output, bidrager på det nuværende stade farligt til ægtheden, men ikke rigtigheden af outputtet.
Sådanne teknikker vil sandsynligvis være nyttige nok, når NLP endelig genskaber de fiktionsskrivende 'kalejdoskoper' fra Orwells Nittenogogfyrre; men de repræsenterer en farefuld stræben efter objektiv dokumentanalyse, AI-centreret journalistik og andre mulige 'non-fiction' anvendelser af maskinresumé og spontan eller guidet tekstgenerering.
Først offentliggjort den 5. april 2022. Opdateret kl. 3:29 EET til korrekt term.