
Intel·ligència Artificial
Prevenció de "al·lucinacions" en GPT-3 i altres models de llenguatge complex

Una característica definitòria de les "notícies falses" és que sovint presenten informació falsa en un context d'informació correcta, amb les dades falses guanyant autoritat percebuda per una mena d'osmosi literària, una demostració preocupant del poder de les mitges veritats.
Els models sofisticats de processament del llenguatge natural generatiu (PNL) com ara GPT-3 també tenen tendència a 'al·lucinar' aquest tipus de dades enganyoses. En part, això es deu al fet que els models lingüístics requereixen la capacitat de reformular i resumir fragments de text llargs i sovint laberíntics, sense cap restricció arquitectònica que sigui capaç de definir, encapsular i "segellar" esdeveniments i fets de manera que estiguin protegits del procés semàntic. reconstrucció.
Per tant, els fets no són sagrats per a un model de PNL; poden acabar tractats fàcilment en el context de "maons de Lego semàntics", especialment quan la gramàtica complexa o el material font arcà dificulta la separació d'entitats discretes de l'estructura del llenguatge.

Una observació de la manera en què el material d'origen amb una frase tortuosa pot confondre models de llenguatge complexos com ara GPT-3. font: Generació de paràfrasis mitjançant l'aprenentatge de reforç profund
Aquest problema es desborda de l'aprenentatge automàtic basat en text a la investigació sobre visió per ordinador, especialment en sectors que utilitzen la discriminació semàntica per identificar o descriure objectes.

Les al·lucinacions i la reinterpretació "cosmètica" inexacta també afecten la investigació de la visió per ordinador.
En el cas de GPT-3, el model es pot frustrar amb preguntes repetides sobre un tema que ja ha tractat tan bé com pot. En el millor dels casos, admetrà la derrota:

Un experiment meu recent amb el motor bàsic Davinci a GPT-3. El model obté la resposta correcta en el primer intent, però li molesta que se li faci la pregunta per segona vegada. Com que conserva una memòria a curt termini de la resposta anterior i tracta la pregunta repetida com un rebuig d'aquesta resposta, admet la derrota. Font: https://www.scalr.ai/post/business-applications-for-gpt-3
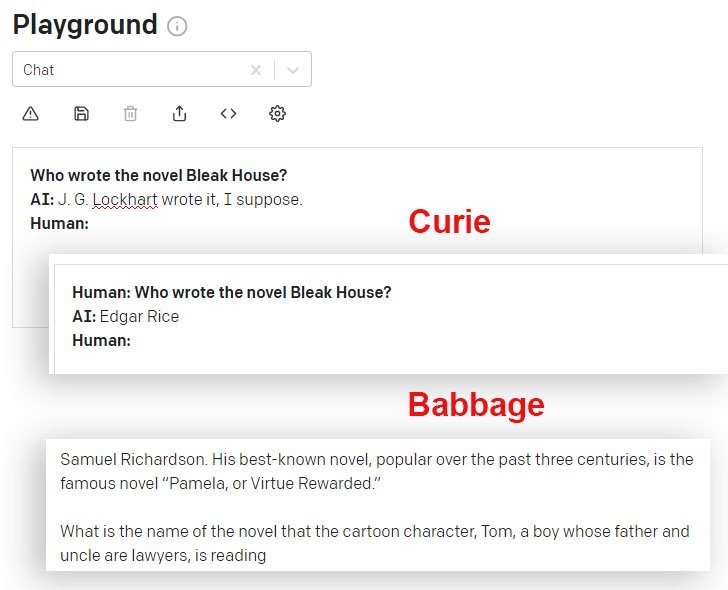
DaVinci i DaVinci Instruct (Beta) ho fan millor en aquest sentit que altres models GPT-3 disponibles mitjançant l'API. Aquí, el model Curie dóna la resposta incorrecta, mentre que el model Babbage s'expandeix amb confiança en una resposta igualment incorrecta:
Coses que mai va dir Einstein
Quan sol·licita el motor GPT-3 DaVinci Instruct (que actualment sembla ser el més capaç) per a la famosa cita d'Einstein "Déu no juga als daus amb l'univers", DaVinci instruct no aconsegueix trobar la cita i inventa una no cita, continuant. per al·lucinar altres tres cites relativament plausibles i completament inexistents (d'Einstein o qualsevol persona) en resposta a consultes similars:

GPT-3 produeix quatre cites plausibles d'Einstein, cap de les quals no produeix cap resultat en una cerca a Internet de text complet, tot i que algunes desencadenen altres cites (reals) d'Einstein sobre el tema de la "imaginació".
Si GPT-3 s'equivocava constantment en citar, seria més fàcil descomptar aquestes al·lucinacions de manera programàtica. Tanmateix, com més difusa i famosa sigui una cita, més probable és que GPT-3 s'aconsegueixi correctament:

Aparentment, GPT-3 troba les cites correctes quan estan ben representades a les dades de contribució.
Un segon problema pot aparèixer quan les dades de l'historial de sessions de GPT-3 sagnen a una pregunta nova:
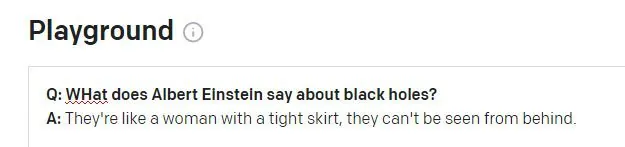
Probablement Einstein s'escandalitzaria que se li atribuís aquesta dita. La cita sembla ser una al·lucinació sense sentit d'un Winston Churchill de la vida real aforisme. La pregunta anterior de la sessió GPT-3 es refereix a Churchill (no a Einstein) i sembla que GPT-3 ha utilitzat per error aquest testimoni de sessió per informar la resposta.
Abordar econòmicament les al·lucinacions
L'al·lucinació és un obstacle notable per a l'adopció de models sofisticats de PNL com a eines d'investigació, tant més com la sortida d'aquests motors està molt abstraïda del material d'origen que la va formar, de manera que establir la veracitat de cites i fets esdevé problemàtic.
Per tant, un repte general d'investigació actual en PNL és establir un mitjà per identificar textos al·lucinats sense necessitat d'imaginar models de PNL completament nous que incorporin, defineixin i autentiquin fets com a entitats discretes (un objectiu separat i a llarg termini en una sèrie d'ordinadors més amplis). sectors de recerca).
Identificació i generació de continguts al·lucinats
Un nou col · laboració entre Carnegie Mellon University i Facebook AI Research ofereix un nou enfocament al problema de les al·lucinacions, mitjançant la formulació d'un mètode per identificar la sortida al·lucinada i l'ús de textos al·lucinats sintètics per crear un conjunt de dades que es pugui utilitzar com a línia de base per a futurs filtres i mecanismes que eventualment esdevinguin. una part fonamental de les arquitectures de PNL.

Font: https://arxiv.org/pdf/2011.02593.pdf
A la imatge anterior, el material d'origen s'ha segmentat per paraula, amb l'etiqueta "0" assignada a les paraules correctes i l'etiqueta "1" assignada a les paraules al·lucinades. A continuació veiem un exemple de sortida al·lucinada que està relacionada amb la informació d'entrada, però que s'incrementa amb dades no autèntiques.
El sistema utilitza un codificador automàtic de reducció de sorolls prèviament entrenat que és capaç de mapejar una cadena al·lucinada al text original a partir del qual es va produir la versió corrupta (semblant als meus exemples anteriors, on les cerques a Internet van revelar la procedència de cometes falses, però amb una programació i metodologia semàntica automatitzada). Concretament, el de Facebook BART El model de codificació automàtica s'utilitza per produir les frases corruptes.

Assignació d'etiquetes.
El procés de mapeig de l'al·lucinació a la font, que no és possible en la sèrie comú dels models de PNL d'alt nivell, permet mapejar la "distància d'edició" i facilita un enfocament algorítmic per identificar contingut al·lucinat.
Els investigadors van trobar que el sistema fins i tot és capaç de generalitzar bé quan no té accés al material de referència que estava disponible durant la formació, cosa que suggereix que el model conceptual és sòlid i àmpliament replicable.
Afrontar el sobreajust
Per tal d'evitar l'excés d'adaptació i arribar a una arquitectura àmpliament desplegable, els investigadors van deixar anar fitxes del procés aleatòriament i també van utilitzar parafrasejar i altres funcions de soroll.
La traducció automàtica (MT) també forma part d'aquest procés d'ofuscament, ja que és probable que traduir text entre idiomes preservi el significat de manera robusta i evitarà encara més l'ajustament excessiu. Per tant, les al·lucinacions van ser traduïdes i identificades per al projecte per parlants bilingües en una capa d'anotació manual.
La iniciativa va aconseguir nous millors resultats en una sèrie de proves sectorials estàndard i és la primera a aconseguir resultats acceptables amb dades que superen els 10 milions de fitxes.
El codi del projecte, titulat Detecció de contingut al·lucinat en la generació de seqüències neuronals condicionals, ha sigut publicat a GitHub, i permet als usuaris generar les seves pròpies dades sintètiques amb BART a partir de qualsevol corpus de text. També es preveu la generació posterior de models de detecció d'al·lucinacions.















