
Изкуствен интелект
Zero123++: Едно изображение към последователен дифузионен базов модел с множество изгледи

През последните няколко години станахме свидетели на бърз напредък в производителността, ефикасността и генеративните способности на нововъзникващия роман AI генеративни модели които използват обширни набори от данни и практики за генериране на 2D дифузия. Днес генеративните AI модели са изключително способни да генерират различни форми на 2D и до известна степен 3D медийно съдържание, включително текст, изображения, видеоклипове, GIF файлове и др.
В тази статия ще говорим за рамката Zero123++, генеративен AI модел с дифузия, обусловен от изображение, с цел генериране на 3D-консистентни изображения с множество изгледи, използвайки един вход за изглед. За да се увеличи максимално предимството, получено от предишни предварително обучени генеративни модели, рамката Zero123++ прилага многобройни схеми за обучение и кондициониране, за да се сведе до минимум усилието, необходимо за фина настройка от готови модели на дифузионни изображения. Ще се потопим по-задълбочено в архитектурата, работата и резултатите от рамката Zero123++ и ще анализираме нейните възможности за генериране на последователни изображения с множество изгледи с високо качество от едно изображение. Така че да започваме.
Zero123 и Zero123++: Въведение
Рамката Zero123++ е обусловен от изображение дифузионен генериращ AI модел, който има за цел да генерира 3D-консистентни изображения с множество изгледи, като използва вход от един изглед. Рамката Zero123++ е продължение на рамката Zero123 или Zero-1-to-3, която използва техниката за синтез на изображения с нов изглед с нулев изстрел, за да бъде пионер в преобразуването на едно изображение в 3D с отворен код. Въпреки че рамката Zero123++ осигурява обещаваща производителност, изображенията, генерирани от рамката, имат видими геометрични несъответствия и това е основната причина, поради която разликата между 3D сцените и изображенията с множество изгледи все още съществува.
Рамката Zero-1-to-3 служи като основа за няколко други рамки, включително SyncDreamer, One-2-3-45, Consistent123 и други, които добавят допълнителни слоеве към рамката Zero123 за получаване на по-последователни резултати при генериране на 3D изображения. Други рамки като ProlificDreamer, DreamFusion, DreamGaussian и други следват базиран на оптимизация подход за получаване на 3D изображения чрез дестилиране на 3D изображение от различни непоследователни модели. Въпреки че тези техники са ефективни и генерират задоволителни 3D изображения, резултатите могат да бъдат подобрени с прилагането на основен дифузионен модел, способен да генерира последователно изображения с множество изгледи. Съответно рамката Zero123++ приема Zero-1 to-3 и фино настройва нов модел на базова дифузия с множество изгледи от Stable Diffusion.
В рамката от нула 1 до 3 всеки нов изглед се генерира независимо и този подход води до несъответствия между генерираните изгледи, тъй като дифузионните модели имат извадков характер. За да се справи с този проблем, рамката Zero123++ възприема подход за оформление на мозайки, като обектът е заобиколен от шест изгледа в едно изображение и гарантира правилното моделиране за съвместното разпределение на изображенията с множество изгледи на обекта.
Друго голямо предизвикателство, пред което са изправени разработчиците, работещи върху рамката Zero-1-to-3, е, че тя не използва достатъчно възможностите, предлагани от Стабилна дифузия което в крайна сметка води до неефективност и допълнителни разходи. Има две основни причини, поради които рамката Zero-1-to-3 не може да увеличи максимално възможностите, предлагани от Stable Diffusion
- Когато тренирате с условия на изображението, рамката Zero-1-to-3 не включва локални или глобални механизми за кондициониране, предлагани ефективно от Stable Diffusion.
- По време на обучение рамката Zero-1-to-3 използва намалена разделителна способност, подход, при който изходната разделителна способност е намалена под разделителната способност на обучението, което може да намали качеството на генериране на изображение за модели на стабилна дифузия.
За да се справи с тези проблеми, рамката Zero123++ прилага набор от техники за кондициониране, които максимизират използването на ресурсите, предлагани от Stable Diffusion, и поддържат качеството на генериране на изображения за модели Stable Diffusion.
Подобряване на кондиционирането и консистенцията
В опит да подобри кондиционирането на изображението и съгласуваността на изображението с множество изгледи, рамката Zero123++ внедри различни техники, като основната цел беше повторното използване на предишни техники, получени от предварително обучения модел на стабилна дифузия.
Генериране на множество изгледи
Незаменимото качество за генериране на последователни изображения с множество изгледи се крие в правилното моделиране на съвместното разпределение на множество изображения. В рамката Zero-1-to-3 корелацията между изображенията с множество изгледи се игнорира, тъй като за всяко изображение рамката моделира условното маргинално разпределение независимо и отделно. Въпреки това, в рамката Zero123++, разработчиците са избрали подход за оформление на мозайки, който обединява 6 изображения в един кадър/изображение за последователно генериране на множество изгледи и процесът е демонстриран на следното изображение.
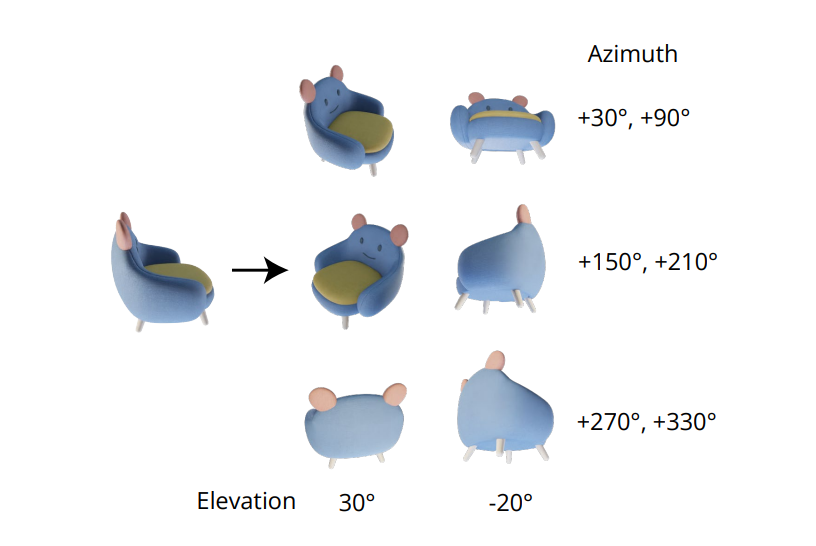
Освен това беше забелязано, че ориентациите на обектите са склонни да разграничават двусмислието, когато обучават модела върху позите на камерата, и за да предотврати това разграничаване, рамката Zero-1-to-3 обучава пози на камерата с ъгли на повдигане и относителен азимут към входа. За да се приложи този подход, е необходимо да се знае ъгълът на повдигане на изгледа на входа, който след това се използва за определяне на относителната поза между новите входни изгледи. В опит да разберат този ъгъл на кота, рамките често добавят модул за оценка на кота и този подход често идва с цената на допълнителни грешки в конвейера.
График на шума
Мащабиран линеен график, оригиналният шумов график за стабилна дифузия се фокусира предимно върху локални детайли, но както може да се види на следващото изображение, има много малко стъпки с по-ниско SNR или съотношение сигнал/шум.

Тези стъпки на ниско съотношение сигнал/шум се случват рано по време на етапа на премахване на шума, етап от решаващо значение за определяне на глобалната нискочестотна структура. Намаляването на броя на стъпките по време на етапа на обезшумяване, било то по време на намеса или обучение, често води до по-голяма структурна вариация. Въпреки че тази настройка е идеална за генериране на едно изображение, тя ограничава способността на рамката да гарантира глобална съгласуваност между различните изгледи. За да преодолее това препятствие, рамката Zero123++ прецизира LoRA модел върху рамката за v-предсказания Stable Diffusion 2, за да изпълни задача-играчка, а резултатите са демонстрирани по-долу.

С мащабирания линеен график на шума моделът LoRA не препълва, а само леко избелва изображението. Обратно, когато работи с линейния шумов график, LoRA рамката генерира успешно празно изображение, независимо от подканата за въвеждане, като по този начин означава въздействието на шумовия график върху способността на рамката да се адаптира към новите изисквания в световен мащаб.
Мащабирано референтно внимание за местните условия
Единичният вход за изглед или кондициониращите изображения в рамката Zero-1-to-3 се свързват с шумните входове в измерението на характеристиките, които трябва да бъдат шумени за кондициониране на изображението.
Това свързване води до неправилно пикселно пространствено съответствие между целевото изображение и входа. За да осигури правилен вход за локално кондициониране, рамката Zero123++ използва мащабирано референтно внимание, подход, при който изпълняването на обезшумяващ UNet модел се препраща към допълнително референтно изображение, последвано от добавяне на матрици на стойности и ключ за самовнимание от референтния изображение към съответните слоеве на вниманието, когато входът на модела е обезшумен, и това е демонстрирано на следващата фигура.

Подходът на референтното внимание е в състояние да насочва дифузионния модел за генериране на изображения, споделящи наподобяваща текстура с референтното изображение и семантично съдържание без каквато и да е фина настройка. С фина настройка подходът Reference Attention осигурява превъзходни резултати с латентно мащабиране.

Глобално кондициониране: FlexDiffuse
В оригиналния подход на стабилна дифузия текстовите вграждания са единственият източник за глобални вграждания и подходът използва рамката CLIP като текстов енкодер за извършване на кръстосани изследвания между текстовите вграждания и латентите на модела. В резултат на това разработчиците са свободни да използват подравняването между текстовите пространства и получените CLIP изображения, за да го използват за глобално кондициониране на изображението.
Рамката Zero123++ предлага да се използва обучаем вариант на механизма за линейно насочване, за да се включи глобалното кондициониране на изображението в рамката с минимални фина настройка необходими, а резултатите са демонстрирани на следното изображение. Както може да се види, без наличието на глобално кондициониране на изображението, качеството на съдържанието, генерирано от рамката, е задоволително за видими области, които съответстват на входното изображение. Въпреки това, качеството на изображението, генерирано от рамката за невидими региони, е свидетел на значително влошаване, което се дължи главно на неспособността на модела да изведе глобалната семантика на обекта.

Архитектура на модела
Рамката Zero123++ се обучава с модела Stable Diffusion 2v като основа, използвайки различните подходи и техники, споменати в статията. Рамката Zero123++ е предварително обучена върху набора от данни на Objaverse, който се изобразява с произволно HDRI осветление. Рамката също възприема подхода на поетапния график за обучение, използван в рамката за вариации на стабилно дифузно изображение в опит да се минимизира допълнително необходимото количество фина настройка и да се запази възможно най-много в предишната стабилна дифузия.
Работата или архитектурата на рамката Zero123++ може да бъде допълнително разделена на последователни стъпки или фази. Първата фаза става свидетел на фина настройка на рамката на KV матриците на слоевете за кръстосано внимание и слоевете за самонасочване на Stable Diffusion с AdamW като негов оптимизатор, 1000 стъпки за загряване и графика на косинусната скорост на обучение, максимизиращ при 7×10-5. Във втората фаза рамката използва силно консервативна постоянна скорост на обучение с 2000 серии за загряване и използва подхода Min-SNR, за да увеличи максимално ефективността по време на обучението.
Zero123++ : Резултати и сравнение на ефективността
Качествено изпълнение
За да се оцени производителността на рамката Zero123++ въз основа на нейното генерирано качество, тя се сравнява със SyncDreamer и Zero-1-to-3-XL, две от най-добрите съвременни рамки за генериране на съдържание. Рамките се сравняват с четири входни изображения с различен обхват. Първото изображение е електрическа котка-играчка, взето директно от набора от данни на Objaverse и може да се похвали с голяма несигурност в задния край на обекта. Второто е изображението на пожарогасител, а третото е изображението на куче, седнало върху ракета, генерирано от модела SDXL. Крайното изображение е илюстрация на аниме. Необходимите стъпки на надморска височина за рамките се постигат чрез използване на метода за оценка на надморската височина на рамката One-2-3-4-5, а премахването на фона се постига с помощта на рамката SAM. Както може да се види, рамката Zero123++ генерира висококачествени изображения с множество изгледи последователно и е способна да обобщава еднакво добре както 2D илюстрации извън домейна, така и изображения, генерирани от AI.


Количествен анализ
За количествено сравняване на рамката Zero123++ с най-съвременните рамки Zero-1-to-3 и Zero-1to-3 XL, разработчиците оценяват оценката на Learned Perceptual Image Patch Similarity (LPIPS) на тези модели на валидиращите разделени данни, подмножество от набора от данни на Objaverse. За да оценят производителността на модела при генериране на изображения с множество изгледи, разработчиците подреждат референтните изображения на истината на земята и съответно 6 генерирани изображения и след това изчисляват резултата за подобие на научени перцептуални изображения (LPIPS). Резултатите са демонстрирани по-долу и както може ясно да се види, рамката Zero123++ постига най-добрата производителност на разделения набор за валидиране.

Текст към многоизгледна оценка
За да оценят способността на рамката Zero123++ при генериране на съдържание от Text to Multi-View, разработчиците първо използват рамката SDXL с текстови подкани за генериране на изображение и след това използват рамката Zero123++ за генерираното изображение. Резултатите са демонстрирани на следното изображение и както може да се види, в сравнение с рамката Zero-1-to-3, която не може да гарантира последователно генериране на множество изгледи, рамката Zero123++ връща последователни, реалистични и много детайлни мулти-изгледи преглеждайте изображения чрез прилагане на текст към изображение към мулти изглед подход или тръбопровод.

Zero123++ Depth ControlNet
В допълнение към базовата рамка Zero123++, разработчиците също пуснаха Depth ControlNet Zero123++, контролирана в дълбочина версия на оригиналната рамка, изградена с помощта на архитектурата ControlNet. Нормализираните линейни изображения се визуализират по отношение на последващите RGB изображения и рамка ControlNet е обучена да контролира геометрията на рамката Zero123++, използвайки възприемане на дълбочина.

Заключение
В тази статия говорихме за Zero123++, обусловен от изображение дифузионен генериращ AI модел с цел генериране на 3D-консистентни изображения с множество изгледи с помощта на един вход за изглед. За да се увеличи максимално предимството, получено от предишни предварително обучени генеративни модели, рамката Zero123++ прилага многобройни схеми за обучение и кондициониране, за да се сведе до минимум усилието, необходимо за фина настройка от готови модели на дифузионни изображения. Ние също така обсъдихме различните подходи и подобрения, въведени от рамката Zero123++, които й помагат да постигне резултати, сравними с и дори надхвърлящи тези, постигнати от текущите съвременни рамки.
Въпреки това, въпреки своята ефективност и способността да генерира последователно висококачествени изображения с множество изгледи, рамката Zero123++ все още има място за подобрение, като потенциалните области на изследване са
- Двустепенен модел на рафинер това може да реши неспособността на Zero123++ да отговори на глобалните изисквания за последователност.
- Допълнителни увеличения за допълнително подобряване на способността на Zero123++ да генерира изображения с още по-високо качество.



