Изкуствен интелект
Опасностите от използването на цитати за удостоверяване на NLG съдържание

Мнение Моделите за генериране на естествен език като GPT-3 са склонни към "халюцинации" материал, който представят в контекста на фактическа информация. В епоха, която е изключително загрижена за растежа на базирани на текст фалшиви новини, тези „нетърпеливи да угодят“ полети на фантазия представляват екзистенциално препятствие за развитието на автоматизирани системи за писане и резюмета и за бъдещето на Журналистика, управлявана от AI, сред различни други подсектори на обработката на естествен език (NLP).
Централният проблем е, че езиковите модели в стил GPT извличат ключови характеристики и класове от много големи корпуси на обучителни текстове и се научете да използвате тези функции като градивни елементи на езика сръчно и автентично, независимо от точността на генерираното съдържание или дори неговата приемливост.
Следователно системите на NLG понастоящем разчитат на човешка проверка на факти в един от двата подхода: че моделите се използват или като начални текстови генератори, които незабавно се предават на човешки потребители, или за проверка, или някаква друга форма на редактиране или адаптиране; или че хората се използват като скъпи филтри за подобряване на качеството на наборите от данни, предназначени да информират за по-малко абстрактни и „творчески“ модели (които сами по себе си неизбежно все още са трудни за доверие по отношение на фактическата точност и които ще изискват допълнителни нива на човешки надзор) .
Стари новини и фалшиви факти
Моделите за генериране на естествен език (NLG) са способни да произвеждат убедителни и правдоподобни резултати, защото са научили семантична архитектура, вместо по-абстрактно асимилиране на действителната история, наука, икономика или всяка друга тема, по която може да се изисква да изразят мнение, които са ефективно заплетени като „пътници“ в изходните данни.
Фактическата точност на информацията, която моделите на NLG генерират, предполага, че входящите данни, на които те се обучават, са сами по себе си надеждни и актуални, което представлява изключителна тежест по отношение на предварителната обработка и по-нататъшната човешка проверка – скъпо препъникамък, с който изследователският сектор на НЛП в момента се занимава на много фронтове.
GPT-3-мащабните системи отнемат изключително много време и пари за обучение и, веднъж обучени, е трудно да се актуализират на това, което може да се счита за „ниво на ядрото“. Въпреки че локалните модификации, базирани на сесии и потребители, могат да увеличат полезността и точността на внедрените модели, тези полезни предимства са трудни, понякога невъзможни за връщане обратно към основния модел, без да е необходимо пълно или частично преквалификация.
Поради тази причина е трудно да се създадат обучени езикови модели, които могат да използват най-новата информация.

Обучен още преди появата на COVID, text-davinci-002 – итерацията на GPT-3, смятана за „най-способна“ от нейния създател OpenAI – може да обработва 4000 токена на заявка, но не знае нищо за COVID-19 или украинското нахлуване през 2022 г. (тези подкани и отговори са от 5 април 2022 г.). Интересното е, че „неизвестен“ всъщност е приемлив отговор и в двата случая на неуспех, но допълнителни подкани лесно установяват, че GPT-3 не знае за тези събития. Източник: https://beta.openai.com/playground
Един обучен модел има достъп само до „истините“, които е интернализирал по време на обучението, и е трудно да се получи точна намлява уместен цитат по подразбиране, когато се опитвате да накарате модела да потвърди твърденията си. Реалната опасност от получаване на котировки от GPT-3 по подразбиране (например) е, че понякога произвежда правилни котировки, което води до фалшива увереност в този аспект на неговите възможности:

Топ, три точни цитата, получени от епохата на 2021 г. davinci-instruct-text GPT-3. Center, GPT-3 пропуска да цитира един от най-известните цитати на Айнщайн („Бог не играе на зарове с Вселената“), въпреки некриптичната подкана. Отдолу, GPT-3 приписва скандален и измислен цитат на Алберт Айнщайн, очевидно излишък от предишни въпроси за Уинстън Чърчил в същата сесия. Източник: собствена статия на автора от 2021 г. на https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Надявайки се да се справи с този общ недостатък в моделите NLG, DeepMind на Google наскоро предложи GopherCite, модел с 280 милиарда параметри, който е способен да цитира конкретни и точни доказателства в подкрепа на генерираните от него отговори на подкани.


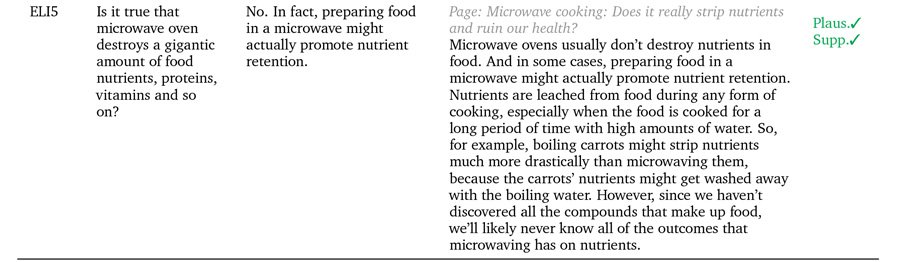
Три примера за GopherCite, подкрепящи твърденията си с реални цитати. Източник: https://arxiv.org/pdf/2203.11147.pdf
GopherCite използва обучение за подсилване от човешките предпочитания (RLHP), за да обучи модели на заявки, способни да цитират реални цитати като подкрепящи доказателства. Цитатите се извличат на живо от множество източници на документи, получени от търсачките, или от конкретен документ, предоставен от потребителя.
Ефективността на GopherCite беше измерена чрез човешка оценка на отговорите на модела, които бяха установени като „висококачествени“ 80% от времето на Google NaturalQuestions набор от данни и 67% от времето на EL5г набор от данни.
Цитиране на неистини
Въпреки това, когато се тества срещу Оксфордския университет TruthfulQA бенчмарк, отговорите на GopherCite рядко се оценяват като верни в сравнение с курираните от хора „правилни“ отговори.
Авторите предполагат, че това е така, защото концепцията за „подкрепени отговори“ не помага по никакъв обективен начин да се дефинира истината сама по себе си, тъй като полезността на цитатите на източниците може да бъде компрометирана от други фактори, като например възможността авторът на цитата да са сами по себе си „халюциниращи“ (т.е. писане за измислени светове, създаване на рекламно съдържание или по друг начин фантастиране на неавтентичен материал.



GopherCite случаи, при които правдоподобността не се равнява непременно на „истина“.
Ефективно в такива случаи става необходимо да се прави разлика между „поддържан“ и „верен“. В момента човешката култура е далеч пред машинното обучение по отношение на използването на методологии и рамки, предназначени да получат обективни дефиниции на истината, и дори там естественото състояние на „важната“ истина изглежда е спор и маргинално отричане.
Проблемът е рекурсивен в архитектурите на NLG, които се стремят да създадат окончателни „потвърждаващи“ механизми: ръководеният от човека консенсус се използва като еталон за истината чрез изнесени, AMTмодели в стил, където са хората оценители (и тези други хора, които посредничат при спорове между тях). сами по себе си пристрастни и пристрастни.
Например, първоначалните експерименти на GopherCite използват модел на „супер оценител“, за да изберат най-добрите човешки субекти за оценка на изхода на модела, избирайки само онези оценители, които са получили най-малко 85% в сравнение с набор за осигуряване на качество. Накрая бяха избрани 113 супероценители за задачата.
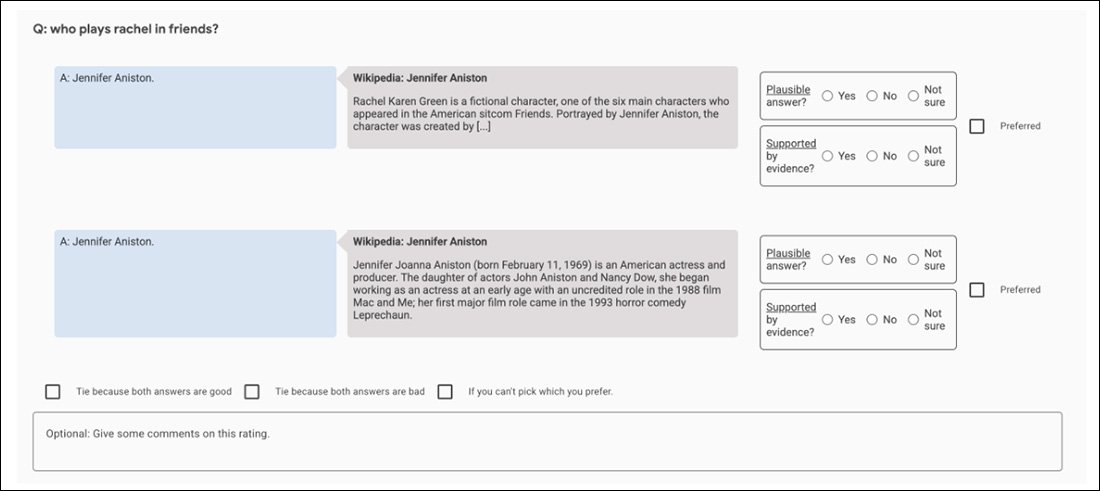
Екранна снимка на приложението за сравнение, използвано за подпомагане на оценката на изхода на GopherCite.
Може да се каже, че това е перфектна картина на фрактално преследване, което не може да бъде спечелено: наборът за осигуряване на качеството, използван за оценяване на оценителите, сам по себе си е още един „дефиниран от човека“ показател за истина, както и наборът Oxford TruthfulQA, спрямо който GopherCite е установено, че има недостатъци.
По отношение на поддържано и „удостоверено“ съдържание, всичко, което системите на NLG могат да се надяват да синтезират от обучение върху човешки данни, е човешкото несъответствие и разнообразие, което само по себе си е неправилно поставен и нерешен проблем. Имаме вродена склонност да цитираме източници, които подкрепят нашите гледни точки, и да говорим авторитетно и с убеденост в случаите, когато информацията от нашия източник може да е остаряла, напълно неточна или умишлено погрешно представена по други начини; и склонност за разпространение на тези гледни точки директно в дивата природа, в мащаб и ефикасност, ненадминати в човешката история, направо по пътя на рамките за събиране на знания, които захранват новите рамки на NLG.
Следователно опасността, свързана с разработването на поддържани от цитиране NLG системи, изглежда свързана с непредсказуемия характер на изходния материал. Всеки механизъм (като директно цитиране и цитати), който повишава доверието на потребителите в изхода на NLG, при сегашното ниво на техниката добавя опасно към автентичността, но не и към истинността на изхода.
Такива техники вероятно ще бъдат достатъчно полезни, когато НЛП най-накрая пресъздаде „калейдоскопите“ за писане на художествена литература от Оруел Деветнадесет осемдесет и четири; но те представляват опасно преследване на обективен анализ на документи, журналистика, фокусирана върху AI, и други възможни „нехудожествени“ приложения на машинно резюме и спонтанно или направлявано генериране на текст.
Първо публикувано на 5 април 2022 г. Актуализирано в 3:29 EET за коригиране на термина.