Изкуствен интелект
Как да тренирате и използвате Hunyuan Video LoRA модели

Тази статия ще ви покаже как да инсталирате и използвате базиран на Windows софтуер, който може да обучава Hunyuan видео LoRA модели, което позволява на потребителя да генерира персонализирани личности в основния модел на Hunyuan Video:
Кликнете, за да играете. Примери от скорошната експлозия на известни личности Hunyuan LoRAs от общността civit.ai.
В момента двата най-популярни начина за локално генериране на Hunyuan LoRA модели са:
1) diffusion-pipe-ui Докер-базирана рамка, която разчита на Подсистема за Windows за Linux (WSL), за да управлява някои от процесите.
2) Мусуби тунер, ново допълнение към популярните Kohya ss дифузионна обучителна архитектура. Musubi Tuner не изисква Docker и не зависи от WSL или други базирани на Linux прокси сървъри – но може да е трудно да се стартира под Windows.
Ето защо този преглед ще се съсредоточи върху Musubi Tuner и върху предоставянето на напълно локално решение за обучение и генериране на Hunyuan LoRA, без използването на управлявани от API уебсайтове или комерсиални процеси за наемане на GPU като Runpod.
Кликнете, за да играете. Примери от обучение по LoRA на Musubi Tuner за тази статия. Всички разрешения, предоставени от изобразеното лице, за целите на илюстрирането на тази статия.
ИЗИСКВАНИЯ
Инсталацията ще изисква минимум компютър с Windows 10 с NVIDIA карта от серия 30+/40+, която има поне 12GB VRAM (въпреки че се препоръчва 16GB). Инсталацията, използвана за тази статия, е тествана на машина с 64 GB на система RAM и NVIDIA 3090 графични карти с 24 GB VRAM. Беше тестван на специална тестова система с нова инсталация на Windows 10 Professional, на дял с 600+ GB свободно дисково пространство.
ПРЕДУПРЕЖДЕНИЕ
Инсталирането на Musubi Tuner и неговите предпоставки също включва инсталиране на софтуер и пакети, фокусирани върху разработчиците, директно в основната инсталация на Windows на компютър. Като вземем предвид инсталирането на ComfyUI, за крайните етапи този проект ще изисква около 400-500 гигабайта дисково пространство. Въпреки че тествах процедурата без инциденти няколко пъти в новоинсталирана тестова среда Windows 10, нито аз, нито unite.ai носим отговорност за каквито и да е щети на системите от спазването на тези инструкции. Съветвам ви да архивирате всички важни данни, преди да опитате този вид инсталационна процедура.
Съображенията
Този метод все още ли е валиден?
Генеративната AI сцена се движи много бързо и можем да очакваме по-добри и по-рационализирани методи на Hunyuan Video LoRA frameworks тази година.
…или дори тази седмица! Докато пишех тази статия, разработчикът на Kohya/Musubi създаде musubi-тунер-gui, сложен Gradio GUI за Musubi Tuner:

Очевидно удобният за потребителя GUI е за предпочитане пред BAT файловете, които използвам в тази функция – след като musubi-tuner-gui работи. Докато пиша, той беше онлайн само преди пет дни и не мога да намеря сметка за някой, който го е използвал успешно.
Според публикациите в хранилището, новият графичен потребителски интерфейс е предназначен да бъде включен директно в проекта Musubi Tuner възможно най-скоро, което ще прекрати съществуването му като самостоятелно хранилище на GitHub.
Въз основа на настоящите инструкции за инсталиране, новият GUI се клонира директно в съществуващата виртуална среда на Musubi; и въпреки многото усилия не мога да го накарам да се свърже със съществуващата инсталация на Musubi. Това означава, че когато работи, ще открие, че няма двигател!
След като GUI бъде интегриран в Musubi Tuner, проблеми от този вид със сигурност ще бъдат решени. Въпреки че авторът признава, че новият проект е „наистина груб“, той е оптимист за неговото развитие и интегриране директно в Musubi Tuner.
Предвид тези проблеми (също относно пътищата по подразбиране по време на инсталиране и използването на Пакет UV Python, което усложнява някои процедури в новата версия), вероятно ще трябва да изчакаме малко за по-гладко обучение на Hunyuan Video LoRA. Това каза, че изглежда много обещаващо!
Но ако не можете да чакате и сте готови да запретнете малко ръкави, можете да стартирате видео LoRA обучение на Hunyuan на местно ниво точно сега.
Да започваме.
Защо да инсталирате Нещо на Bare Metal?
(Пропуснете този параграф, ако не сте напреднал потребител)
Напредналите потребители ще се чудят защо избрах да инсталирам толкова голяма част от софтуера на голата инсталация на Windows 10, вместо във виртуална среда. Причината е, че основният порт на Windows е базиран на Linux Пакет Тритон е много по-трудно да се работи във виртуална среда. Всички останали голи метални инсталации в урока не могат да бъдат инсталирани във виртуална среда, тъй като трябва да взаимодействат директно с локалния хардуер.
Инсталиране на необходимите пакети и програми
За програмите и пакетите, които трябва да бъдат първоначално инсталирани, редът на инсталиране има значение. Нека започваме.
1: Изтеглете Microsoft Redistributable
Изтеглете и инсталирайте пакета за повторно разпространение на Microsoft от https://aka.ms/vs/17/release/vc_redist.x64.exe.
Това е проста и бърза инсталация.

2: Инсталирайте Visual Studio 2022
Изтеглете изданието на общността на Microsoft Visual Studio 2022 от https://visualstudio.microsoft.com/downloads/?cid=learn-onpage-download-install-visual-studio-page-cta
Стартирайте изтегления инсталатор:

Не се нуждаем от всеки наличен пакет, което би било тежка и продължителна инсталация. В началния Работни натоварвания страница, която се отваря, отметнете Разработка на настолен компютър с C++ (виж изображението по-долу).

Сега кликнете върху Индивидуални компоненти в горния ляв ъгъл на интерфейса и използвайте полето за търсене, за да намерите „Windows SDK“.

По подразбиране само SDK за Windows 11 е отбелязано. Ако сте на Windows 10 (тази инсталационна процедура не е тествана от мен на Windows 11), отбележете най-новата версия на Windows 10, посочена на изображението по-горе.
Потърсете „C++ CMake“ и проверете това C++ CMake инструменти за Windows е проверена.

Тази инсталация ще отнеме поне 13 GB място.

След като Visual Studio бъде инсталиран, той ще се опита да стартира на вашия компютър. Оставете го да се отвори напълно. Когато интерфейсът на цял екран на Visual Studio най-накрая се види, затворете програмата.
3: Инсталирайте Visual Studio 2019
Някои от следващите пакети за Musubi очакват по-стара версия на Microsoft Visual Studio, докато други се нуждаят от по-нова.
Затова изтеглете и безплатното издание на общността на Visual Studio 19 от Microsoft (https://visualstudio.microsoft.com/vs/older-downloads/ – изисква се акаунт) или Techspot (https://www.techspot.com/downloads/7241-visual-studio-2019.html).
Инсталирайте го със същите опции като за Visual Studio 2022 (вижте процедурата по-горе, с изключение на това Windows SDK вече е отбелязано в инсталатора на Visual Studio 2019).
Ще видите, че инсталаторът на Visual Studio 2019 вече е наясно с по-новата версия, докато се инсталира:

Когато инсталацията приключи и сте отворили и затворили инсталираното приложение Visual Studio 2019, отворете команден ред на Windows (Въведете CMD в Стартиране на търсене) и въведете и въведете:
where cl
Резултатът трябва да бъде известните местоположения на двете инсталирани издания на Visual Studio.

Ако вместо това получите INFO: Could not find files for the given pattern(s), виж Проверете пътя раздел на тази статия по-долу и използвайте тези инструкции, за да добавите съответните пътища на Visual Studio към средата на Windows.
Запазете всички промени, направени според Проверете пътищата раздел по-долу и след това опитайте отново командата where cl.
4: Инсталирайте CUDA 11 + 12 Toolkits
Различните пакети, инсталирани в Musubi, се нуждаят от различни версии на NVIDIA CUDA, който ускорява и оптимизира обучението на графични карти NVIDIA.
Причината да инсталираме версиите на Visual Studio първи е, че инсталаторите на NVIDIA CUDA търсят и се интегрират с всички съществуващи инсталации на Visual Studio.
Изтеглете инсталационен пакет CUDA от серия 11+ от:
https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local (Изтегли "exe (локален") )
Изтеглете инсталационен пакет от 12+ серии CUDA Toolkit от:
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64
Процесът на инсталиране е идентичен и за двата инсталатора. Игнорирайте всички предупреждения за съществуването или несъществуването на инсталационни пътища в променливите на Windows Environment – ще се погрижим за това ръчно по-късно.
Инсталирайте NVIDIA CUDA Toolkit V11+
Стартирайте инсталатора за CUDA Toolkit от серия 11+.


At Опции за инсталиране, избирам Персонализирано (разширено) и продължете.

Премахнете отметката от опцията NVIDIA GeForce Experience и щракнете Напред.

Оставям Изберете Местоположение за инсталиране по подразбиране (това е важно):

Кликнете Напред и оставете инсталацията да приключи.

Игнорирайте всички предупреждения или бележки, които инсталаторът дава Nsight Visual Studio интеграция, която не е необходима за нашия случай на употреба.
Инсталирайте NVIDIA CUDA Toolkit V12+
Повторете целия процес за отделната инсталационна програма за 12+ NVIDIA Toolkit, която сте изтеглили:

Процесът на инсталиране за тази версия е идентичен с този, посочен по-горе (версия 11+), с изключение на едно предупреждение относно пътищата на средата, което можете да игнорирате:

Когато инсталацията на 12+ CUDA версия приключи, отворете команден ред в Windows и въведете и въведете:
nvcc --version
Това трябва да потвърди информацията за инсталираната версия на драйвера:

За да проверите дали вашата карта е разпозната, въведете и въведете:
nvidia-smi

5: Инсталирайте GIT
GIT ще се справи с инсталирането на хранилището на Musubi на вашата локална машина. Изтеглете инсталатора на GIT от:
https://git-scm.com/downloads/win („64-битова настройка на Git за Windows“)

Стартирайте инсталатора:

Използвайте настройките по подразбиране за Изберете Компоненти:
Оставете редактора по подразбиране на Vim:

Нека GIT реши относно имената на клоновете:

Използвайте препоръчителните настройки за Път Заобикаляща среда:

Използвайте препоръчителните настройки за SSH:

Използвайте препоръчителните настройки за HTTPS транспортен бекенд:
Използвайте препоръчителните настройки за преобразувания в края на реда:

Изберете конзолата по подразбиране на Windows като терминален емулатор:
Използвайте настройките по подразбиране (Превъртане напред или обединяване) за Git Pull:

Използвайте Git-Credential Manager (настройката по подразбиране) за Credential Helper:

In Конфигуриране на допълнителни опции, оставете Разрешете кеширането на файловата система отметнато и Активиране на символни връзки без отметка (освен ако не сте напреднал потребител, който използва твърди връзки за централизирано хранилище на модели).

Завършете инсталацията и проверете дали Git е инсталиран правилно, като отворите CMD прозорец и напишете и въведете:
git --version

Вход в GitHub
По-късно, когато се опитате да клонирате GitHub хранилища, може да бъдете предизвикани за вашите идентификационни данни за GitHub. За да предвидите това, влезте в акаунта си в GitHub (създайте такъв, ако е необходимо) във всеки браузър, инсталиран на вашата система Windows. По този начин методът за удостоверяване 0Auth (изскачащ прозорец) трябва да отнема възможно най-малко време.
След това първоначално предизвикателство трябва да останете удостоверени автоматично.
6: Инсталирайте CMake
CMake 3.21 или по-нова е необходима за части от инсталационния процес на Musubi. CMake е архитектура за разработка на различни платформи, способна да организира различни компилатори и да компилира софтуер от изходния код.
Изтеглете го от:
https://cmake.org/download/ („Инсталатор на Windows x64“)
Стартирайте инсталатора:

Уверете се, Добавете Cmake към променливата на средата PATH е проверена.

Натискане Напред.

Въведете и въведете тази команда в командния ред на Windows:
cmake --version
Ако CMake е инсталиран успешно, той ще покаже нещо като:
cmake version 3.31.4
CMake suite maintained and supported by Kitware (kitware.com/cmake).

7: Инсталирайте Python 3.10
Интерпретаторът на Python е централен за този проект. Изтеглете версията 3.10 (най-добрият компромис между различните изисквания на пакетите Musubi) от:
https://www.python.org/downloads/release/python-3100/ („Инсталатор на Windows (64-битов)“)
Стартирайте инсталатора за изтегляне и оставете настройките по подразбиране:

В края на инсталационния процес щракнете Деактивирайте ограничението за дължина на пътя (изисква потвърждение от UAC администратор):

В командния ред на Windows въведете и въведете:
python --version
Това трябва да доведе до Python 3.10.0

Проверете пътищата
Клонирането и инсталирането на рамката Musubi, както и нормалната й работа след инсталацията, изисква нейните компоненти да познават пътя до няколко важни външни компонента в Windows, особено CUDA.
Така че трябва да отворим средата на пътя и да проверим дали всички реквизити са там.
Бърз начин да стигнете до контролите за Windows среда е да пишете Редактирайте променливите на системната среда в лентата за търсене на Windows.

Щракването върху това ще отвори Свойства на системата контролен панел. В долния десен ъгъл на Свойства на систематаЩракнете върху Променливи на околната среда бутон и прозорец, извикан Променливи на околната среда отваря се. В Системни променливи панел в долната половина на този прозорец, превъртете надолу до Път и щракнете двукратно върху него. Това отваря прозорец, наречен Редактирайте променливите на средата. Плъзнете ширината на този прозорец по-широко, за да можете да видите пълния път на променливите:

Тук важните записи са:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.42.34433\bin\Hostx64\x64
C:\Program Files\Git\cmd
C:\Program Files\CMake\bin
В повечето случаи правилните променливи на пътя вече трябва да присъстват.
Добавете всички пътища, които липсват, като щракнете НОВ отляво на Редактиране на променливата на средата прозорец и поставяне в правилния път:

НЕ просто копирайте и поставяйте от пътищата, изброени по-горе; проверете дали всеки еквивалентен път съществува във вашата собствена инсталация на Windows.
Ако има незначителни вариации на пътя (особено при инсталации на Visual Studio), използвайте пътищата, изброени по-горе, за да намерите правилните целеви папки (т.е. x64 in Домакин64 във вашата собствена инсталация. След това залепете тези пътеки в Редактиране на променливата на средата прозорец.
След това рестартирайте компютъра.
Инсталиране на Musubi
Надстройте PIP
Използването на най-новата версия на инсталатора на PIP може да изглади някои от етапите на инсталиране. В командния ред на Windows с администраторски права (вижте Кота, по-долу), въведете и въведете:
pip install --upgrade pip
Кота
Някои команди може да изискват повишени привилегии (т.е. да се изпълняват като администратор). Ако получите съобщения за грешка относно разрешенията на следващите етапи, затворете прозореца на командния ред и го отворете отново в администраторски режим, като напишете CMD в полето за търсене на Windows, като щракнете с десния бутон върху Command Prompt и избиране Изпълнявай като администратор:

За следващите етапи ще използваме Windows Powershell вместо командния ред на Windows. Можете да намерите това, като въведете PowerShell в полето за търсене на Windows и (ако е необходимо) щракнете с десния бутон върху него, за да Изпълнявай като администратор:

Инсталирайте Torch
В Powershell въведете и въведете:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Бъдете търпеливи, докато многото пакети се инсталират.
Когато приключите, можете да проверите инсталацията на PyTorch с активиран GPU, като напишете и въведете:
python -c "import torch; print(torch.cuda.is_available())"
Това трябва да доведе до:
C:\WINDOWS\system32>python -c "import torch;
print(torch.cuda.is_available())"
True
Инсталирайте Triton за Windows
След това инсталирането на Triton за Windows компонент. В повишения Powershell въведете (на един ред):
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post8/triton-3.1.0-cp310-cp310-win_amd64.whl
(Инсталаторът triton-3.1.0-cp310-cp310-win_amd64.whl работи както за процесори Intel, така и за AMD, стига архитектурата да е 64-битова и средата съответства на версията на Python)
След стартиране това трябва да доведе до:
Successfully installed triton-3.1.0
Можем да проверим дали Triton работи, като го импортираме в Python. Въведете тази команда:
python -c "import triton; print('Triton is working')"
Това трябва да изведе:
Triton is working
За да проверите дали Triton е с активиран GPU, въведете:
python -c "import torch; print(torch.cuda.is_available())"
Това трябва да доведе до True:

Създайте виртуална среда за Musubi
Отсега нататък ще инсталираме всеки допълнителен софтуер в a Виртуална среда на Python (или venv). Това означава, че всичко, което трябва да направите, за да деинсталирате целия следващ софтуер, е да плъзнете инсталационната папка на venv в кошчето.
Нека създадем тази инсталационна папка: направете папка, наречена Мусуби на вашия работен плот. Следните примери предполагат, че тази папка съществува: C:\Users\[Your Profile Name]\Desktop\Musubi\.
В Powershell отидете до тази папка, като въведете:
cd C:\Users\[Your Profile Name]\Desktop\Musubi
Искаме виртуалната среда да има достъп до това, което вече сме инсталирали (особено Triton), така че ще използваме --system-site-packages знаме. Въведете това:
python -m venv --system-site-packages musubi
Изчакайте средата да бъде създадена и след това я активирайте, като въведете:
.\musubi\Scripts\activate
От този момент нататък можете да разберете, че сте в активираната виртуална среда по факта, че (musubi) се появява в началото на всички ваши подкани.

Клонирайте хранилището
Придвижете се до новосъздадения Мусуби папка (която е вътре в Мусуби папка на вашия работен плот):
cd musubi
Сега, когато сме на правилното място, въведете следната команда:
git clone https://github.com/kohya-ss/musubi-tuner.git
Изчакайте клонирането да завърши (няма да отнеме много време).

Изисквания за инсталиране
Отидете до инсталационната папка:
cd musubi-tuner
Enter:
pip install -r requirements.txt
Изчакайте много инсталации да завършат (това ще отнеме повече време).

Автоматизиране на достъпа до Hunyuan Video Venv
За лесно активиране и достъп до новия venv за бъдещи сесии, поставете следното в Notepad и го запазете с името активирай.bat, запазвайки го с Всички файлове опция (вижте изображението по-долу).
@echo off
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate
cd C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner
cmd
(Заменете [Your Profile Name]с истинското име на вашия потребителски профил в Windows)

Няма значение на кое място ще запишете този файл.
Отсега нататък можете да щракнете два пъти активирай.bat и започнете работа веднага.

Използване на Musubi Tuner
Изтегляне на моделите
Процесът на обучение на Hunyuan Video LoRA изисква изтеглянето на поне седем модела, за да се поддържат всички възможни опции за оптимизация за предварително кеширане и обучение на Hunyuan video LoRA. Заедно тези модели тежат повече от 60 GB.
Текущи инструкции за изтеглянето им можете да намерите на https://github.com/kohya-ss/musubi-tuner?tab=readme-ov-file#model-download
Това обаче са инструкциите за изтегляне към момента на писане:
clip_l.safetensors
llava_llama3_fp16.safetensors
llava_llama3_fp8_scaled.safetensors
може да се изтегли на:
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/text_encoders
mp_rank_00_model_states.pt
mp_rank_00_model_states_fp8.pt
mp_rank_00_model_states_fp8_map.pt
може да се изтегли на:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/transformers
pytorch_model.pt
може да се изтегли на:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/vae
Въпреки че можете да ги поставите във всяка директория, която изберете, за съгласуваност с по-късните скриптове, нека ги поставим в:
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\
Това е в съответствие с подредбата на директорията преди тази точка. Всички команди или инструкции по-нататък ще предполагат, че това е мястото, където са разположени моделите; и не забравяйте да замените [Името на вашия профил] с вашето истинско име на папка с профил в Windows.
Подготовка на набор от данни
Пренебрегвайки противоречията в общността по въпроса, справедливо е да се каже, че ще ви трябват някъде между 10-100 снимки за набор от данни за обучение за вашия Hunyuan LoRA. Могат да се получат много добри резултати дори с 15 изображения, стига изображенията да са добре балансирани и с добро качество.
Hunyuan LoRA може да се обучава както на изображения, така и на много кратки видеоклипове с ниска разделителна способност, или дори комбинация от всеки – въпреки че използването на видеоклипове като данни за обучение е предизвикателство дори за 24GB карта.
Видеоклиповете обаче са наистина полезни само ако вашият герой се движи по толкова необичаен начин, че моделът на фондация Hunyuan Video може да не знае за това, или да можете да познаете.
Примерите биха включвали Заека Роджър, ксеноморф, Маската, Спайдърмен или други личности, които притежават уникален характерно движение.
Тъй като Hunyuan Video вече знае как се движат обикновените мъже и жени, не са необходими видеоклипове, за да се получи убедителен характер от човешки тип Hunyuan Video LoRA. Така че ще използваме статични изображения.
Подготовка на изображението
The Bucket List
Версията на TLDR:
Най-добре е или да използвате изображения, които са с еднакъв размер за вашия набор от данни, или да използвате 50/50 разделени между два различни размера, т.е. 10 изображения, които са 512x768px и 10, които са 768x512px.
Обучението може да мине добре, дори ако не го направите – Hunyuan Video LoRAs може да бъде изненадващо прощаващ.
По-дългата версия
Както при Kohya-ss LoRA за статични генериращи системи като стабилна дифузия, кофата се използва за разпределяне на работното натоварване между изображения с различни размери, което позволява да се използват по-големи изображения, без да се причиняват грешки при недостиг на памет по време на обучение (т.е. групирането „нарязва“ изображенията на парчета, които GPU може да обработва, като същевременно поддържа семантична цялост на цялото изображение).
За всеки размер на изображението, който включвате във вашия набор от данни за обучение (т.е. 512x768px), ще бъде създадена кофа или „подзадача“ за този размер. Така че, ако имате следното разпределение на изображения, това е начинът, по който вниманието на кофата става небалансирано и има риск на някои снимки да се обърне по-голямо внимание в обучението, отколкото на други:
2x 512x768px изображения
7x 768x512px изображения
1x 1000x600px изображение
3x 400x800px изображения
Можем да видим, че вниманието на кофата е разпределено неравномерно между тези изображения:

Затова или се придържайте към един размер на формата, или се опитайте да запазите разпределението на различните размери относително еднакво.
И в двата случая избягвайте много големи изображения, тъй като това вероятно ще забави обучението, което ще доведе до незначителна полза.
За простота използвах 512x768px за всички снимки в моя набор от данни.
Опровержение: Моделът (човек), използван в набора от данни, ми даде пълно разрешение да използвам тези снимки за тази цел и упражни одобрение за всички базирани на AI резултати, изобразяващи нейното подобие, представени в тази статия.

Моят набор от данни се състои от 40 изображения във формат PNG (въпреки че JPG също е добре). Изображенията ми бяха съхранени в C:\Users\Martin\Desktop\DATASETS_HUNYUAN\examplewoman
Трябва да създадете скривалище папка в папката с изображения за обучение:

Сега нека създадем специален файл, който ще конфигурира обучението.
TOML файлове
Процесите на обучение и предварително кеширане на Hunyuan Video LoRAs получават файловите пътища от плосък текстов файл с .toml удължаване.
За моя тест TOML се намира в C:\Users\Martin\Desktop\DATASETS_HUNYUAN\training.toml
Съдържанието на моето обучение TOML изглежда така:
[general]
resolution = [512, 768]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman"
cache_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman\\cache"
num_repeats = 1
(Двойните обратни наклонени черти за директории с изображения и кеш не винаги са необходими, но те могат да помогнат да се избегнат грешки в случаите, когато има интервал в пътя. Обучих модели с .toml файлове, които използват single-forward и single- наклонени черти назад)
Можем да видим в resolution раздел, че ще бъдат взети под внимание две разделителни способности – 512px и 768px. Можете също така да оставите това на 512 и пак да получите добри резултати.
Надписи
Hunyuan Video е a текст+vision фундаментален модел, така че имаме нужда от описателни надписи за тези изображения, които ще бъдат разгледани по време на обучението. Процесът на обучение ще се провали без надписи.
Има множество на системи за надписи с отворен код, които бихме могли да използваме за тази задача, но нека да бъдем прости и да използваме тагуи система. Въпреки че се съхранява в GitHub и въпреки че изтегля някои много тежки модели за задълбочено обучение при първото стартиране, той идва под формата на прост изпълним файл на Windows, който зарежда библиотеки на Python и ясен GUI.
След като стартирате Taggui, използвайте Файл > Зареждане на директория за навигиране до вашия набор от данни за изображения и по избор да поставите идентификатор на токен (в този случай, примерна жена), които ще бъдат добавени към всички надписи:

(Не забравяйте да изключите Зареждане в 4 бита когато Taggui се отвори за първи път – ще изведе грешки по време на надписи, ако това е оставено)
Изберете изображение в лявата колона за преглед и натиснете CTRL+A, за да изберете всички изображения. След това натиснете бутона Start Auto-Captioning отдясно:

Ще видите Taggui да изтегля модели в малкия CLI в дясната колона, но само ако това е първият път, когато стартирате надписа. В противен случай ще видите визуализация на надписите.

Сега всяка снимка има съответен .txt надпис с описание на съдържанието на изображението:

Можете да кликнете върху Разширени опции в Taggui, за да увеличите дължината и стила на надписите, но това е извън обхвата на този преглед.
Излезте от Taggui и нека преминем към...
Латентно предварително кеширане
За да се избегне прекомерно натоварване на графичния процесор по време на обучение, е необходимо да се създадат два типа предварително кеширани файлове – един за представяне на скритото изображение, получено от самите изображения, и друг за оценка на текстово кодиране, свързано със съдържанието на надписи.
За да опростите и трите процеса (2x кеш + обучение), можете да използвате интерактивни .BAT файлове, които ще ви задават въпроси и ще предприемат процесите, когато предоставите необходимата информация.
За скритото предварително кеширане, копирайте следния текст в Notepad и го запазете като .BAT файл (т.е. наименувайте го нещо като latent-precache.bat), както по-рано, като се уверите, че типът файл в падащото меню в Save As диалогът е Всички файлове (вижте изображението по-долу):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with latent pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the latent pre-caching script
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_latents.py --dataset_config %TOML_PATH% --vae C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\pytorch_model.pt --vae_chunk_size 32 --vae_tiling
) else (
echo Operation canceled.
)
REM Keep the window open
pause
(Уверете се, че сте заменили [Име на вашия профил] с вашето истинско име на папка с профил в Windows)

Сега можете да стартирате .BAT файла за автоматично латентно кеширане:

Когато бъдете подканени от различните въпроси от BAT файла, поставете или въведете пътя до вашия набор от данни, кеш папки и TOML файл.
Предварително кеширане на текст
Ще създадем втори BAT файл, този път за предварително кеширане на текст.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with text encoder output pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Use the python executable from the virtual environment
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_text_encoder_outputs.py --dataset_config %TOML_PATH% --text_encoder1 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\llava_llama3_fp16.safetensors --text_encoder2 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\clip_l.safetensors --batch_size 16
) else (
echo Operation canceled.
)
REM Keep the window open
pause
Заменете името на вашия профил в Windows и запазете това като текстов кеш.bat (или всяко друго име, което желаете), на всяко удобно място, съгласно процедурата за предишния BAT файл.
Стартирайте този нов BAT файл, следвайте инструкциите и необходимите текстово кодирани файлове ще се появят в скривалище папка:

Обучение на Hunyuan Video Lora
Обучението на действителния LoRA ще отнеме значително повече време от тези два подготвителни процеса.
Въпреки че има и множество променливи, за които можем да се тревожим (като размер на партида, повторения, епохи и дали да използваме пълни или квантувани модели, между другото), ще запазим тези съображения за друг ден и ще разгледаме по-задълбочено тънкостите на създаването на LoRA.
Засега нека минимизираме малко възможностите за избор и да обучим LoRA на „средни“ настройки.
Ще създадем трети BAT файл, този път за започване на обучение. Поставете това в Notepad и го запазете като BAT файл, както преди, като обучение.прилеп (или всяко име, което желаете):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p DATASET_CONFIG=Enter the path to the dataset configuration file:
set /p EPOCHS=Enter the number of epochs to train:
set /p OUTPUT_NAME=Enter the output model name (e.g., example0001):
set /p LEARNING_RATE=Choose learning rate (1 for 1e-3, 2 for 5e-3, default 1e-3):
if "%LEARNING_RATE%"=="1" set LR=1e-3
if "%LEARNING_RATE%"=="2" set LR=5e-3
if "%LEARNING_RATE%"=="" set LR=1e-3
set /p SAVE_STEPS=How often (in steps) to save preview images:
set /p SAMPLE_PROMPTS=What is the location of the text-prompt file for training previews?
echo You entered:
echo Dataset configuration file: %DATASET_CONFIG%
echo Number of epochs: %EPOCHS%
echo Output name: %OUTPUT_NAME%
echo Learning rate: %LR%
echo Save preview images every %SAVE_STEPS% steps.
echo Text-prompt file: %SAMPLE_PROMPTS%
REM Prepare the command
set CMD=accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 ^
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\hv_train_network.py ^
--dit C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\mp_rank_00_model_states.pt ^
--dataset_config %DATASET_CONFIG% ^
--sdpa ^
--mixed_precision bf16 ^
--fp8_base ^
--optimizer_type adamw8bit ^
--learning_rate %LR% ^
--gradient_checkpointing ^
--max_data_loader_n_workers 2 ^
--persistent_data_loader_workers ^
--network_module=networks.lora ^
--network_dim=32 ^
--timestep_sampling sigmoid ^
--discrete_flow_shift 1.0 ^
--max_train_epochs %EPOCHS% ^
--save_every_n_epochs=1 ^
--seed 42 ^
--output_dir "C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models" ^
--output_name %OUTPUT_NAME% ^
--vae C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/pytorch_model.pt ^
--vae_chunk_size 32 ^
--vae_spatial_tile_sample_min_size 128 ^
--text_encoder1 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/llava_llama3_fp16.safetensors ^
--text_encoder2 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/clip_l.safetensors ^
--sample_prompts %SAMPLE_PROMPTS% ^
--sample_every_n_steps %SAVE_STEPS% ^
--sample_at_first
echo The following command will be executed:
echo %CMD%
set /p CONFIRM=Do you want to proceed with training (y/n)?
if /i "%CONFIRM%"=="y" (
%CMD%
) else (
echo Operation canceled.
)
REM Keep the window open
cmd /k
Както обикновено, не забравяйте да замените всички екземпляри of [Име на вашия профил] с вашето правилно име на Windows профил.
Уверете се, че директорията C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\ съществува и го създайте на това място, ако не.
Прегледи на обучението
Има много основна функция за предварителен преглед на обучението, активирана наскоро за треньора на Musubi, която ви позволява да принудите тренировъчния модел да постави на пауза и да генерира изображения въз основа на подкани, които сте запазили. Те се записват в автоматично създадена папка, наречена Проба, в същата директория, в която са записани обучените модели.

За да активирате това, ще трябва да запазите най-малко една подкана в текстов файл. BAT за обучение, който създадохме, ще ви помоли да въведете местоположението на този файл; следователно можете да наименувате файла с подкани както желаете и да го запишете навсякъде.
Ето няколко бързи примера за файл, който ще изведе три различни изображения, когато бъде поискано от рутинната програма за обучение:

Както можете да видите в примера по-горе, можете да поставите флагове в края на подканата, които ще засегнат изображенията:
–w е Широчината (по подразбиране е 256px, ако не е зададено, според документите)
– h е височина (по подразбиране е 256px, ако не е зададено)
–f е брой рамки. Ако е зададено на 1, се създава изображение; повече от едно, видео.
–d е семето. Ако не е зададено, то е произволно; но трябва да го настроите да виждате как се развива една подкана.
–s е броят на стъпките в генерирането, по подразбиране е 20.
виждам официалната документация за допълнителни флагове.
Въпреки че визуализациите на обучението могат бързо да разкрият някои проблеми, които могат да ви накарат да отмените обучението и да преразгледате данните или настройката, като по този начин спестите време, не забравяйте, че всяка допълнителна подкана забавя обучението още малко.
Също така, колкото по-големи са ширината и височината на изображението за предварителен преглед на обучението (както е зададено в изброените по-горе флагове), толкова повече това ще забави обучението.
Стартирайте своя тренировъчен BAT файл.
Въпрос 1 е „Въведете пътя до конфигурацията на набора от данни. Поставете или въведете правилния път към вашия TOML файл.
Въпрос 2 е „Въведете броя на епохите за обучение“. Това е променлива тип проба-грешка, тъй като се влияе от количеството и качеството на изображенията, както и от надписите и други фактори. Като цяло, най-добре е да го зададете твърде високо, отколкото твърде ниско, тъй като винаги можете да спрете обучението с Ctrl+C в прозореца за обучение, ако смятате, че моделът е напреднал достатъчно. Задайте го на 100 в първия случай и вижте как върви.
Въпрос 3 е „Въведете името на изходния модел“. Назовете вашия модел! Може би е най-добре името да е сравнително кратко и просто.
Въпрос 4 е „Изберете скорост на обучение“, която по подразбиране е 1e-3 (опция 1). Това е добро място за начало, в очакване на допълнителен опит.
Въпрос 5 е „Колко често (в стъпки) да се запазват изображения за визуализация. Ако зададете това твърде ниско, ще видите малък напредък между записите на предварителни изображения и това ще забави обучението.
Въпрос 6 е „Какво е местоположението на файла с текстови подкани за визуализации на обучение?“. Поставете или въведете пътя към вашия текстов файл с подкани.
След това BAT ви показва командата, която ще изпрати към модела Hunyuan, и ви пита дали искате да продължите, да/не.
Продължете и започнете обучението:
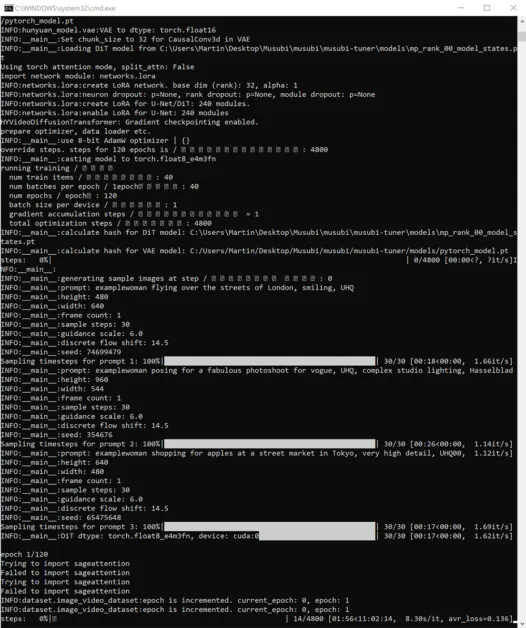
През това време, ако проверите секцията GPU в раздела Performance на Windows Task Manager, ще видите, че процесът отнема около 16 GB VRAM.

Това може да не е произволна цифра, тъй като това е количеството VRAM, налично на доста графични карти на NVIDIA, а кодът нагоре може да е оптимизиран, за да побере задачите в 16GB в полза на тези, които притежават такива карти.
Това каза, че е много лесно да се увеличи това използване, като се изпращат повече прекомерни флагове към командата за обучение.
По време на тренировка ще видите в долната дясна страна на прозореца на CMD цифра колко време е изминало от началото на тренировката и прогноза за общото време на тренировка (което ще варира значително в зависимост от зададените флагове, броя на тренировъчните изображения , брой изображения за преглед на обучението и няколко други фактора).

Типичното време за обучение е около 3-4 часа при средни настройки, в зависимост от наличния хардуер, броя на изображенията, настройките на флага и други фактори.
Използване на вашите обучени модели LoRA във видео на Hunyuan
Избор на контролни точки
Когато обучението приключи, ще имате модел на контролна точка за всяка епоха на обучение.

Тази честота на записване може да бъде променена от потребителя, за да записва по-често или по-рядко, според желанието, чрез промяна на --save_every_n_epochs [N] номер в учебния BAT файл. Ако сте добавили ниска цифра за записвания на стъпки, когато настройвате обучение с BAT, ще има голям брой запазени файлове с контролни точки.
Коя контролна точка да избера?
Както бе споменато по-рано, най-ранно обучените модели ще бъдат най-гъвкави, докато по-късните контролни точки могат да предложат най-много подробности. Единственият начин да тествате тези фактори е да стартирате някои от LoRA и да генерирате няколко видеоклипа. По този начин можете да разберете кои контролни точки са най-продуктивни и представляват най-добрия баланс между гъвкавост и вярност.
ComfyUI
Най-популярната (макар и не единствената) среда за използване на Hunyuan Video LoRA в момента е ComfyUI, базиран на възли редактор със сложен Gradio интерфейс, който работи във вашия уеб браузър.

Източник: https://github.com/comfyanonymous/ComfyUI
Инструкциите за инсталиране са ясни и наличен в официалното хранилище на GitHub (ще трябва да се изтеглят допълнителни модели).
Конвертиране на модели за ComfyUI
Вашите обучени модели се записват във формат (дифузори), който не е съвместим с повечето реализации на ComfyUI. Musubi може да конвертира модел във формат, съвместим с ComfyUI. Нека настроим BAT файл, за да приложим това.
Преди да стартирате този BAT, създайте C:\Users\[Your Profile Name]\Desktop\Musubi\CONVERTED\ папка, която скриптът очаква.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
:START
REM Get user input
set /p INPUT_PATH=Enter the path to the input Musubi safetensors file (or type "exit" to quit):
REM Exit if the user types "exit"
if /i "%INPUT_PATH%"=="exit" goto END
REM Extract the file name from the input path and append 'converted' to it
for %%F in ("%INPUT_PATH%") do set FILENAME=%%~nF
set OUTPUT_PATH=C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\CONVERTED\%FILENAME%_converted.safetensors
set TARGET=other
echo You entered:
echo Input file: %INPUT_PATH%
echo Output file: %OUTPUT_PATH%
echo Target format: %TARGET%
set /p CONFIRM=Do you want to proceed with the conversion (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the conversion script with correctly quoted paths
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\convert_lora.py --input "%INPUT_PATH%" --output "%OUTPUT_PATH%" --target %TARGET%
echo Conversion complete.
) else (
echo Operation canceled.
)
REM Return to start for another file
goto START
:END
REM Keep the window open
echo Exiting the script.
pause
Както при предишните BAT файлове, запишете скрипта като „Всички файлове“ от Notepad, като го наименувате convert.bat (или каквото ви харесва).
След като запазите, щракнете двукратно върху новия BAT файл, който ще поиска местоположението на файл за конвертиране.

Поставете или въведете пътя до обучения файл, който искате да конвертирате, щракнете yи натиснете enter.
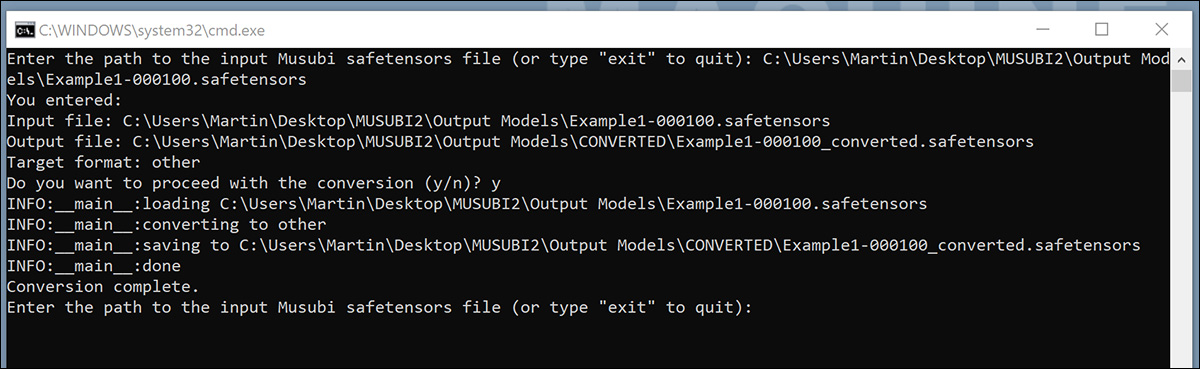
След като запазите конвертирания LoRA в КОНВЕРТИРАН папка, скриптът ще ви попита дали искате да конвертирате друг файл. Ако искате да тествате множество контролни точки в ComfyUI, конвертирайте селекция от моделите.
Когато сте преобразували достатъчно контролни точки, затворете командния прозорец на BAT.
Вече можете да копирате преобразуваните си модели в папката models\loras във вашата инсталация на ComfyUI.
Обикновено правилното местоположение е нещо като:
C:\Users\[Your Profile Name]\Desktop\ComfyUI\models\loras\
Създаване на Hunyuan Video LoRA в ComfyUI
Въпреки че базираните на възли работни потоци на ComfyUI първоначално изглеждат сложни, настройките на други по-опитни потребители могат да бъдат заредени чрез плъзгане на изображение (направено с ComfyUI на другия потребител) директно в прозореца на ComfyUI. Работните потоци могат също да бъдат експортирани като JSON файлове, които могат да бъдат импортирани ръчно или плъзнати в прозорец на ComfyUI.
Някои импортирани работни потоци ще имат зависимости, които може да не съществуват във вашата инсталация. Затова инсталирайте ComfyUI-мениджър, който може автоматично да извлича липсващите модули.

Източник: https://github.com/ltdrdata/ComfyUI-Manager
За да заредите един от работните процеси, използвани за генериране на видеоклипове от моделите в този урок, изтеглете този JSON файл и го плъзнете във вашия прозорец ComfyUI (въпреки че има много по-добри примери за работен процес, налични в различните общности на Reddit и Discord, които са приели Hunyuan Video, а моят собствен е адаптиран от един от тях).
Това не е мястото за разширен урок за използването на ComfyUI, но си струва да споменем няколко от важните параметри, които ще повлияят на изхода ви, ако изтеглите и използвате JSON оформлението, към което направих връзка по-горе.

1) Ширина и Височина
Колкото по-голямо е вашето изображение, толкова по-дълго ще отнеме генерирането и толкова по-голям е рискът от грешка при липса на памет (OOM).
2) Дължина
Това е числената стойност за броя на кадрите. Колко секунди добавя зависи от кадровата честота (настроена на 30 кадъра в секунда в това оформление). Можете да конвертирате секунди>кадри въз основа на fps в Omnicalculator.
3) Размер на партидата
Колкото по-висок зададете размера на партидата, толкова по-бърз може да дойде резултатът, но толкова по-голяма е тежестта на VRAM. Задайте това твърде високо и може да получите OOM.
4) Контрол след генериране
Това контролира произволното семе. Опциите за този подвъзел са фиксиран, нарастване, намаляване намлява случайно. Ако го оставите на фиксиран и не променяйте текстовата подкана, ще получите едно и също изображение всеки път. Ако промените текстовата подкана, изображението ще се промени в ограничена степен. The нарастване намлява намаляване настройките ви позволяват да изследвате близките начални стойности, докато случайно ви дава напълно нова интерпретация на подканата.
5) Име Лора
Ще трябва да изберете свой собствен инсталиран модел тук, преди да опитате да генерирате.
6) Токен
Ако сте обучили вашия модел да задейства концепцията с токен (като напр "примерно лице"), поставете тази задействаща дума във вашата подкана.
7) Стъпки
Това представлява колко стъпки ще приложи системата към процеса на дифузия. С по-високи стъпки може да се получат по-добри детайли, но има таван за това колко ефективен е този подход и този праг може да бъде трудно да се намери. Общият диапазон от стъпки е около 20-30.
8) Размер на плочката
Това определя колко информация се обработва наведнъж по време на генерирането. По подразбиране е зададено на 256. Повишаването му може да ускори генерирането, но повишаването му твърде високо може да доведе до особено разочароващо OOM изживяване, тъй като идва в самия край на дълъг процес.
9) Времево припокриване
Генерирането на Hunyuan Video от хора може да доведе до „призрак“ или неубедително движение, ако това е зададено твърде ниско. Като цяло, текущата мъдрост е, че това трябва да бъде зададено на по-висока стойност от броя на кадрите, за да се получи по-добро движение.
Заключение
Въпреки че по-нататъшното изследване на използването на ComfyUI е извън обхвата на тази статия, опитът на общността в Reddit и Discords може да улесни кривата на обучение и има няколко онлайн ръководства които въвеждат основите.
Първо публикувано в четвъртък, 23 януари 2025 г












