
Изкуствен интелект
Разрешаване на проблема с JPEG артефакта в набори от данни за компютърно зрение
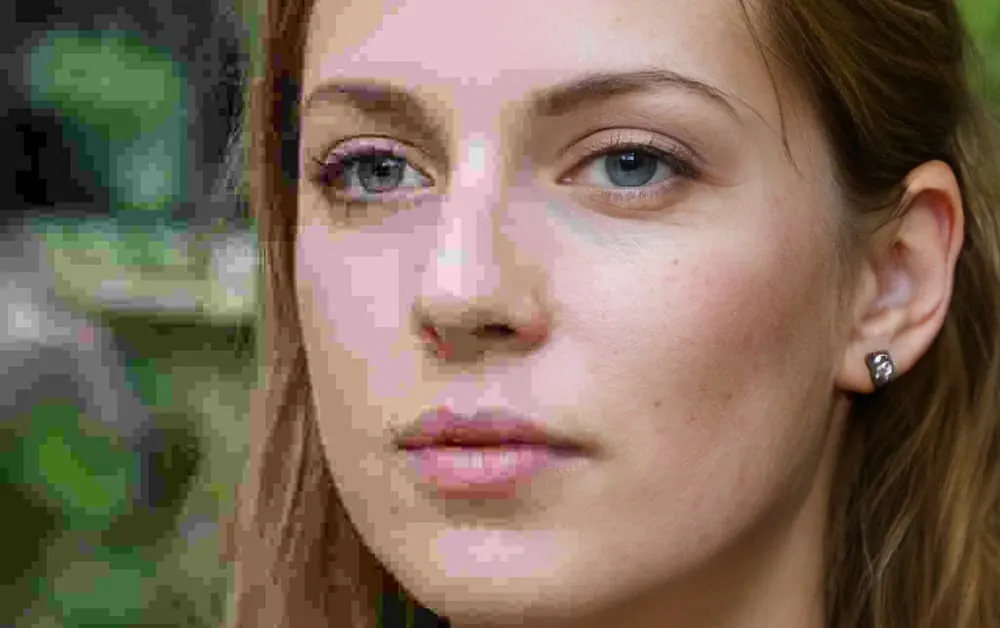
Ново проучване от Университета на Мериленд и Facebook AI откри „значително намаление на производителността“ за системи за дълбоко обучение, които използват силно компресирани JPEG изображения в своите набори от данни, и предлага някои нови методи за смекчаване на ефектите от това.
- докладва, озаглавена Анализиране и смекчаване на дефекти на JPEG компресия в Deep Learning, твърди, че е „значително по-всеобхватен“ от предишни проучвания за ефектите на артефактите при обучението на набори от данни за компютърно зрение. Документът установява, че „[тежката] до умерена JPEG компресия води до значителна загуба на производителност на стандартните показатели“ и че невронните мрежи може би не са толкова устойчиви на подобни смущения, както предишната работа подсказва.

Снимка на куче от набора от данни MobileNetV2018 за 2 г. При качество 10 (вляво) система за класификация не успява да идентифицира правилната порода „Пемброк уелско корги“, вместо това предполага „Норич териер“ (системата вече знае, че това е снимка на куче, но не и породата); второто отляво, готова версия на изображението с корекция на JPEG артефакти отново не успява да идентифицира правилната порода; втората отдясно, насочената корекция на артефакт възстановява правилната класификация; и вдясно, оригиналната снимка, правилно класифицирана. Източник: https://arxiv.org/pdf/2011.08932.pdf
Артефакти на компресия като „данни“
Екстремната JPEG компресия вероятно ще създаде видими или полувидими граници около 8×8 блокчета от които JPEG се сглобява в пикселна мрежа. След като тези блокиращи или „звънящи“ артефакти се появят, те вероятно ще бъдат погрешно интерпретирани от системите за машинно обучение като елементи от реалния свят на обекта на изображението, освен ако не се направи някаква компенсация за това.

По-горе, система за машинно обучение за компютърно зрение извлича „чисто“ градиентно изображение от картина с добро качество. По-долу „блокиращите“ артефакти при запис на изображението с по-ниско качество затъмняват характеристиките на обекта и в крайна сметка могат да „заразят“ характеристиките, получени от набор от изображения, особено в случаите, когато в набора от данни се срещат изображения с високо и ниско качество , като например в колекции, скрапирани в мрежата, към които е приложено само общо почистване на данни. Източник: http://www.cs.utep.edu/ofuentes/papers/quijasfuentes2014.pdf
Както се вижда на първото изображение по-горе, такива артефакти могат да повлияят на задачите за класифициране на изображения, с последици и за алгоритмите за разпознаване на текст, които може да не успеят да идентифицират правилно засегнатите от артефакт знаци.
В случай на системи за обучение за синтез на изображения (като софтуер за дълбоко фалшифициране или системи за генериране на изображения, базирани на GAN), „измамен“ блок от нискокачествени, силно компресирани изображения в набор от данни може или да понижи средното качество на възпроизвеждане, или иначе да бъдат включени и по същество заменени от по-голям брой функции с по-високо качество, извлечени от по-добри изображения в комплекта. И в двата случая са желателни по-добри данни – или поне последователни данни.
JPEG – Обикновено „Достатъчно добър“
JPEG компресията е необратимо загубен кодек, който може да се приложи към различни формати на изображения, въпреки че се прилага основно към JFIF файла с изображения халат. Въпреки това форматът JPEG (.jpg) е кръстен на свързания с него метод за компресиране, а не на JFIF обвивката за данните на изображението.
През последните години се появиха цели архитектури за машинно обучение, които включват смекчаване на артефакти в стил JPEG като част от управлявани от AI рутинни процедури за мащабиране/възстановяване, а премахването на артефакти за компресия, базирано на AI, вече е включено в редица търговски продукти, като изображението Topaz/ видео апартаментИ невронни особености на последните версии на Adobe Photoshop.
Тъй като 1986 JPEG схемата, която понастоящем се използва често, беше почти заключена в началото на 1990-те години на миналия век, не е възможно да се добавят метаданни към изображение, което да показва на кое ниво на качество (1-100) е записано JPEG изображение – поне не без промяна на тридесет години наследени потребителски, професионални и академични софтуерни системи, които не са очаквали такива метаданни да бъдат налични.
Следователно, не е необичайно да се адаптират тренировъчните процедури за машинно обучение към оцененото или известно качество на данните за JPEG изображения, както направиха изследователите за новата статия (вижте по-долу). При липса на запис на метаданни за „качество“, в момента е необходимо или да се знаят подробностите за това как е компресирано изображението (т.е. компресирано от източник без загуби), или да се оцени качеството чрез перцептивни алгоритми или ръчна класификация.
Икономичен компромис
JPEG не е единственият метод за компресия със загуби, който може да повлияе на качеството на наборите от данни за машинно обучение; настройките за компресиране в PDF файлове също могат да отхвърлят информация по този начин и да бъдат зададени на много ниски нива на качество, за да се спести дисково пространство за локални или мрежови архивни цели.
Това може да се види чрез вземане на проби от различни PDF файлове в archive.org, някои от които са компресирани толкова силно, че представляват значително предизвикателство за системите за разпознаване на изображения или текст. В много случаи, като например защитени с авторски права книги, тази интензивна компресия изглежда е била приложена като форма на евтино DRM, почти по същия начин, по който притежателите на авторски права могат да изберат да намалят разделителната способност на качени от потребителите видеоклипове в YouTube, на които притежават IP, оставяйки „блоковите“ видеоклипове като промоционални жетони, за да вдъхновяват покупките с „пълна резолюция“, вместо да ги изтривате.
В много други случаи разделителната способност или качеството на изображението е ниско, просто защото данните са много стари и произхождат от ера, когато локалното и мрежовото съхранение е било по-скъпо и когато ограничените мрежови скорости са предпочитали силно оптимизираните и преносими изображения пред възпроизвеждането с високо качество .
Твърди се, че JPEG не е най-доброто решение сега, е "укрепено" като неподвижна наследена инфраструктура, която по същество е преплетена с основите на интернет.
Наследствено бреме
Въпреки че по-късните нововъведения като JPEG 2000, PNG и (най-наскоро) форматът .webp предлагат превъзходно качество, повторното вземане на проби от по-стари, много популярни набори от данни за машинно обучение би могло да „нулира“ приемствеността и историята на годишните предизвикателства за компютърно зрение в академичната общност – пречка, която би се прилагала и в случай на повторно запазване на PNG изображения с набор от данни при настройки с по-високо качество. Това може да се разглежда като вид технически дълг.
Докато уважаемите библиотеки за обработка на изображения, управлявани от сървъри, като ImageMagick, поддържат по-добри формати, включително .webp, изискванията за трансформиране на изображения често възникват в наследени системи, които не са настроени за нищо друго освен JPG или PNG (което предлага компресия без загуби, но за сметка на латентност и дисково пространство). Дори WordPress, захранването на CMS близо 40% от всички уебсайтове, само добавена поддръжка за .webp преди три месеца.
PNG беше късно (може би твърде късно) навлизане в сектора на форматите на изображения, възниквайки като решение с отворен код през втората част на 1990-те години в отговор на декларация от 1995г от Unisys и CompuServe, че отсега нататък ще се плащат възнаграждения върху формата за компресия LZW, използван в GIF файлове, които обикновено се използват тогава за лога и елементи с плосък цвят, дори ако форматът възкресение в началото на 2010 г. се съсредоточи върху способността си да предоставя бързо анимирано съдържание с ниска честотна лента (по ирония на съдбата, анимираните PNG никога не са спечелили популярност или широка подкрепа и дори са забранен от Twitter в 2019).
Въпреки недостатъците си, JPEG компресията е бърза, спестяваща пространството и е дълбоко вградена в системи от всякакъв тип – и следователно няма вероятност да изчезне напълно от сцената на машинното обучение в близко бъдеще.
Извличане на най-доброто от AI/JPEG Detente
До известна степен общността за машинно обучение се е приспособила към недостатъците на JPEG компресията: през 2011 г. Европейското дружество по радиология (ESR) публикува проучване относно „Използваемостта на необратимо компресиране на изображения при радиологични изображения“, предоставяйки насоки за „приемлива“ загуба; когато преподобният MNIST набор от данни за разпознаване на текст (чиито данни за изображения първоначално бяха предоставени в нов двоичен формат) беше пренесен в „обикновен“ формат на изображение, JPEG, не PNG, бе избран; и предложено по-ранно (2020 г.) сътрудничество от авторите на новия документ "нова архитектура" за калибриране на системи за машинно обучение към недостатъците на различното качество на JPEG изображението, без да е необходимо моделите да бъдат обучавани за всяка настройка за качество на JPEG – функция, използвана в новата работа.
Наистина, изследването на полезността на JPEG данни с различен качество е относително процъфтяваща област в машинното обучение. Един (несвързан) проект от 2016 г. от Центъра за изследване на автоматизацията към Университета на Мериленд, всъщност центрира върху DCT домейна (където JPEG артефакти възникват при настройки с ниско качество) като път към дълбоко извличане на функции; друг проект от 2019 г. се концентрира върху четене на ниво байт на JPEG данни без времеемката необходимост от действително декомпресиране на изображенията (т.е. отварянето им в някакъв момент в автоматизиран работен процес); и а проучване от Франция през 2019 г. активно използва JPEG компресия в услуга на рутинни процедури за разпознаване на обекти.
Тестване и заключения
За да се върнем към последното проучване от UoM и Facebook, изследователите се опитаха да тестват разбираемостта и полезността на JPEG върху изображения, компресирани между 10-90 (под което изображението е невъзможно смутено, а над което е равно на компресия без загуби). Изображенията, използвани в тестовете, бяха предварително компресирани при всяка стойност в рамките на целевия диапазон на качество, което включва най-малко осем тренировъчни сесии.
Моделите бяха обучени на стохастичен градиент на спускане по четири метода: изходно ниво, където не са добавени допълнителни смекчаващи мерки; контролирана фина настройка, където наборът за обучение има предимството на предварително обучени тегла и етикетирани данни (въпреки че изследователите признават, че това е трудно да се повтори в приложения на потребителско ниво); корекция на артефакти, където се извършва увеличаване/подобряване на компресираните изображения преди обучението; и корекция на артефакт, насочена към задачата, където мрежата с правилен артефакт се настройва фино при върнати грешки.
Обучението се проведе на голямо разнообразие от подходящи набори от данни, включително множество варианти на ResNet, FastRCNN, MobileNetV2, МаскаRCNN и Керас Начало V3.
Резултатите от загуба на проби след корекция на артефакт, насочена към задачата, са визуализирани по-долу (по-ниско = по-добро).
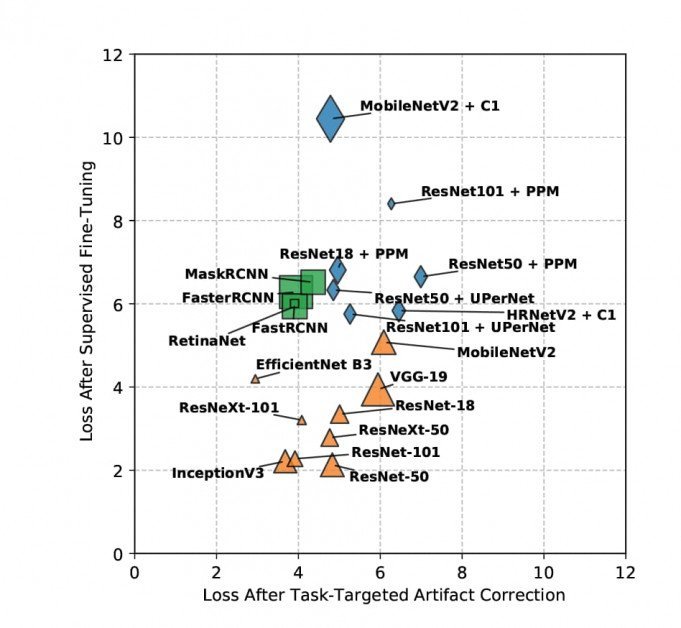
Не е възможно да се потопим дълбоко в детайлите на резултатите, получени в проучването, тъй като констатациите на изследователите са разделени между целта за оценка на JPEG артефактите и новите методи за облекчаване на това; обучението беше повторено за качество над толкова много набори от данни; и задачите включват множество цели като откриване на обекти, сегментиране и класифициране. По същество новият доклад се позиционира като цялостен справочен труд, разглеждащ множество проблеми.
Независимо от това, документът обобщава заключението, че „компресията на JPEG има рязко наказание навсякъде за тежки до умерени настройки на компресия“. Той също така твърди, че неговите нови немаркирани стратегии за смекчаване постигат превъзходни резултати сред други подобни подходи; че за сложни задачи контролираният от изследователите метод също превъзхожда своите връстници, въпреки че няма достъп до етикети за основна истина; и че тези нови методологии позволяват повторно използване на модела, тъй като получените тегла могат да се прехвърлят между задачи.
По отношение на задачите за класификация, документът изрично посочва, че „JPEG влошава качеството на градиента, както и предизвиква грешки при локализиране“.
Авторите се надяват да разширят бъдещите проучвания, за да обхванат други методи за компресиране, като например до голяма степен пренебрегнатите JPEG 2000, както и WebP, HEIF намлява BPG. Освен това те предполагат, че тяхната методология може да се приложи към аналогични изследвания на алгоритми за компресиране на видео.
Тъй като методът за коригиране на артефактите, насочен към задачите, се оказа толкова успешен в проучването, авторите също сигнализират за намерението си да пуснат тежестите, обучени по време на проекта, очаквайки, че „[много] приложения ще се възползват от използването на нашите TTAC тежести без модификация.“
nb Изходното изображение за статията идва от thispersondoesnotexist.com













