تمثل القدرة على توليد أصول رقمية ثلاثية الأبعاد من نصوص محفزة واحدة من التطورات الأكثر إثارة في مجال الذكاء الاصطناعي والرسومات الحاسوبية. مع تقدير سوق الأصول الرقمية ثلاثية الأبعاد لينمو من $28.3 مليار في عام 2024 إلى $51.8 مليار بحلول عام 2029، فإن نماذج الذكاء الاصطناعي من النص إلى 3D على وشك لعب دور رئيسي في ثورة إنشاء المحتوى عبر صناعات مثل الألعاب والسينما والتجارة الإلكترونية وغيرها. ولكن كيف تعمل هذه الأنظمة بالضبط؟ في هذه المقالة، سنقوم بتحليل تفصيلي لل细يات الفنية وراء توليد 3D من النص.
تحدي توليد 3D
توليد الأصول ثلاثية الأبعاد من النص هو مهمة أكثر تعقيدًا من توليد الصور ثنائية الأبعاد. في حين أن الصور ثنائية الأبعاد هي في الأساس شبكات من البكسل، فإن الأصول ثلاثية الأبعاد تتطلب تمثيل الهندسة والtextures والمواد وأحيانًا الحركات في الفضاء ثلاثي الأبعاد. يزيد هذا البعد الإضافي والتعقيد من صعوبة المهمة.
تتضمن بعض التحديات الرئيسية في توليد 3D من النص:
تمثيل الهندسة ثلاثية الأبعاد والهيكل
توليد textures ومواد متسقة عبر السطح ثلاثي الأبعاد
ضمان المطابقة الفيزيائية والاتساق من عدة مناظير
التحكم في التفاصيل الدقيقة والهيكل العالمي في نفس الوقت
توليد أصول يمكن عرضها أو طباعتها بسهولة
لمواجهة هذه التحديات، تستخدم نماذج النص إلى 3D عدة تقنيات رئيسية.
المكونات الرئيسية لأنظمة النص إلى 3D
تتشارك معظم أنظمة توليد 3D من النص الحالية في عدة مكونات رئيسية:
ترميز النص: تحويل النص المحفز إلى تمثيل رقمي
تمثيل 3D: طريقة لتمثيل الهندسة ثلاثية الأبعاد والمظهر
نموذج توليد: النموذج الرئيسي للذكاء الاصطناعي لتوليد الأصل ثلاثي الأبعاد
العرض: تحويل التمثيل ثلاثي الأبعاد إلى صور ثنائية الأبعاد للعرض
دعونا نستكشف كل هذه المكونات بالتفصيل.
ترميز النص
الخطوة الأولى هي تحويل النص المحفز إلى تمثيل رقمي يمكن للنموذج العمل معه. يتم ذلك عادةً باستخدام نماذج لغة كبيرة مثل BERT أو GPT.
تمثيل 3D
هناك عدة طرق شائعة لتمثيل الهندسة ثلاثية الأبعاد في نماذج الذكاء الاصطناعي:
شبكات الفوكسيل: مصفوفات ثلاثية الأبعاد من القيم التي تمثل الاحتلال أو الميزات
سحب النقاط: مجموعات من النقاط ثلاثية الأبعاد
الشبكات: الرأس والوجوه التي تحدد سطحًا
الدالات الضمنية: دوال مستمرة تحدد سطحًا (مثل دوال المسافة الموقعة)
حقول الإشعاع العصبي (NeRFs): شبكات عصبونية تمثل الكثافة واللون في الفضاء ثلاثي الأبعاد
لكل منها تبادلات فيما يتعلق بالدقة واستخدام الذاكرة وسهولة التوليد. تستخدم العديد من النماذج الحديثة الدالات الضمنية أو NeRFs لأنها تسمح بنتائج عالية الجودة مع متطلبات حسابية معقولة.
على سبيل المثال، يمكننا تمثيل كرة بسيطة كدالة مسافة موقعة:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# تقييم SDF عند نقطة ثلاثية الأبعاد
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"المسافة إلى سطح الكرة: {distance}")
نموذج التوليد
الجزء الرئيسي من نظام النص إلى 3D هو نموذج التوليد الذي ينتج التمثيل ثلاثي الأبعاد من التضمين النصي. يستخدم معظم النماذج الحديثة بعض التنويعات من نموذج الانتشار.
تعمل نماذج الانتشار عن طريق إضافة الضوضاء تدريجيًا إلى البيانات، ثم تعلم عكس هذه العملية. بالنسبة لتوليد 3D، تحدث هذه العملية في مساحة التمثيل ثلاثي الأبعاد المختار.
قد يبدو رمز الكاذب المبسّط لخطوة تدريب نموذج انتشار على النحو التالي:
def diffusion_training_step(model, x_0, text_embedding):
# عينة زمنية عشوائية
t = torch.randint(0, num_timesteps, (1,))
# إضافة الضوضاء إلى الإدخال
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# توقع الضوضاء
predicted_noise = model(x_t, t, text_embedding)
# حساب الخسارة
loss = F.mse_loss(noise, predicted_noise)
return loss
# حلقة التدريب
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
خلال التوليد، نبدأ من ضوضاء نقية ونتكرر إزالة الضوضاء بشكل متكرر، مشروطًا بالتضمين النصي.
العرض
لعرض النتائج وحساب الخسائر أثناء التدريب، намط إلى عرض تمثيلنا ثلاثي الأبعاد إلى صور ثنائية الأبعاد. يتم ذلك عادةً باستخدام تقنيات العرض القابلة للتفاضل التي تسمح بتدفق التدرج العكسي خلال عملية العرض.
对于 تمثيلات الشبكة، قد نستخدم معرضًا قائمًا على ترسيم:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# إنشاء معرض
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# إعداد الكاميرا
cameras = pr.FoVPerspectiveCameras()
# العرض
images = renderer(vertices, faces, cameras=cameras)
return images
# استخدام المثال
vertices = torch.rand(1, 100, 3) # رأس عشوائي
faces = torch.randint(0, 100, (1, 200, 3)) # وجوه عشوائية
rendered_images = render_mesh(vertices, faces)
对于 التمثيلات الضمنية مثل NeRFs، نستخدم عادةً تقنيات المسار المارشي.
جمع كل شيء معًا: خط أنابيب النص إلى 3D
الآن بعد أن غطينا المكونات الرئيسية، دعونا ننتقل إلى كيفية دمجها في خط أنابيب توليد 3D من النص النموذجي:
ترميز النص: يتم ترميز النص المحفز إلى تمثيل متجانس باستخدام نموذج لغة.
التوليد الأولي: يولد نموذج انتشار، مشروطًا بالتضمين النصي، تمثيلًا أوليًا ثلاثي الأبعاد (مثل NeRF أو دالة ضمنية).
اتساق متعدد المناظير
التحسين: قد تُحسن الشبكات الإضافية الهندسة أو تضيف textures أو تعزز التفاصيل.
الإخراج النهائي: يتم تحويل التمثيل ثلاثي الأبعاد إلى تنسيق مرغوب (مثل شبكة مخططة) للاستخدام في التطبيقات الخلفية.
هنا مثال مبسط عن كيفية ظهور ذلك في الكود:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# ترميز النص
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# توليد تمثيل 3D أولي
initial_3d = self.diffusion_model(text_embedding)
# عرض مناظير متعددة
views = self.renderer(initial_3d, num_views=4)
# تحسين بناءً على اتساق متعدد المناظير
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# الاستخدام
model = TextTo3D()
text_prompt = "سيارة رياضية حمراء"
generated_3d = model(text_prompt)
أفضل نماذج الأصول ثلاثية الأبعاد المتاحة
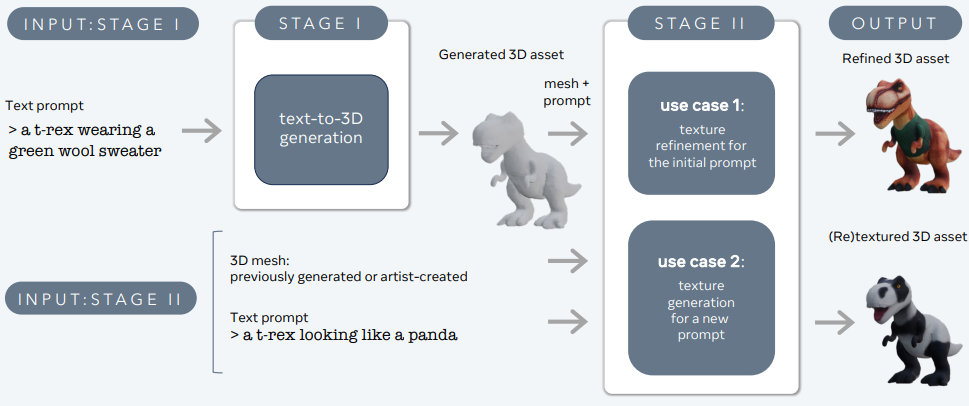
3DGen – Meta
3DGen مصمم لمواجهة مشكلة توليد المحتوى ثلاثي الأبعاد – مثل الشخصيات والملحقات والمناظر – من وصف نصي.
دعم 3DGen للترسيم المبني على الفيزياء (PBR)، الذي يعد ضروريًا لإنارة الأصول ثلاثية الأبعاد الواقعية في التطبيقات الحقيقية. كما يتيح إعادة النسيج التوليدي للشapes ثلاثية الأبعاد المولدة مسبقًا أو المخترعة من قبل الفنانين باستخدام مدخلات نصية جديدة. يتضمن خط الأنابيب دمج两个 مكونات رئيسية: Meta 3D AssetGen و Meta 3D TextureGen، التي تتعامل مع توليد النص إلى 3D وتوليد النص إلى النسيج على التوالي.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) مسؤول عن توليد الأصول ثلاثية الأبعاد الأولية من نصوص محفزة. ينتج هذا المكون شبكة ثلاثية الأبعاد مع textures وخرائط مواد PBR في حوالي 30 ثانية.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) يُحسن textures المولدة بواسطة AssetGen. يمكن استخدامه أيضًا لتوليد textures جديدة للشبكات ثلاثية الأبعاد الحالية بناءً على وصف نصي إضافي. يستغرق هذا المرحلة حوالي 20 ثانية.
Point-E (OpenAI)
Point-E، تم تطويره بواسطة OpenAI، هو نموذج توليد 3D من النص آخر ملحوظ. على عكس DreamFusion، الذي ينتج تمثيلات NeRF، يولد Point-E سحبًا من النقاط ثلاثية الأبعاد.
الميزات الرئيسية لPoint-E:
أ) خط أنابيب من مرحلتين: يولد Point-E أولًا منظرًا ثنائيًا الأبعاد اصطناعيًا باستخدام نموذج انتشار النص إلى الصورة، ثم يستخدم هذه الصورة لتشغيل نموذج انتشار ثاني ينتج سحابًا من النقاط ثلاثية الأبعاد.
ب) الكفاءة: صمم Point-E ليكون كفؤًا حاسوبيًا، قادرًا على توليد سحب من النقاط ثلاثية الأبعاد في ثوان على جهاز كمبيوتر واحد.
ج) معلومات اللون: يمكن للنموذج توليد سحبًا من النقاط ثلاثية الأبعاد ملونة، مما يحافظ على المعلومات الهندسية والمظهر.
الlimitations:
دقة أقل مقارنة بالمناهج القائمة على الشبكات أو NeRFs
تتطلب سحب النقاط معالجة إضافية لاستخدامها في العديد من التطبيقات الخلفية
Shap-E (OpenAI):
بناءً على Point-E، قدم OpenAI Shap-E، الذي يولد شبكات ثلاثية الأبعاد بدلاً من سحب النقاط. هذا يعالج بعض قيود Point-E مع الحفاظ على الكفاءة الحاسوبية.
ب) استخراج الشبكة: يستخدم النموذج تنفيذًا قابلًا للتفاضل لخوارزمية المكعبات المتجولة لتحويل التمثيل الضمني إلى شبكة متعددة السطوح.
ج) توليد النسيج: يمكن لShap-E أيضًا توليد textures للشبكات ثلاثية الأبعاد، مما ينتج عنه مخرجات أكثر جاذبية بصريًا.
المزايا:
أوقات توليد سريعة (ثوان إلى دقائق)
إخراج الشبكة المباشر مناسب للعرض والتطبيقات الخلفية
القدرة على توليد الهندسة والنسيج في نفس الوقت
GET3D (NVIDIA):
GET3D، تم تطويره بواسطة باحثون في NVIDIA، هو نموذج آخر قوي لتوليد 3D من النص يركز على إنتاج شبكات ثلاثية الأبعاد مخططة عالية الجودة.
الميزات الرئيسية لGET3D:
أ) تمثيل سطح صريح: على عكس DreamFusion أو Shap-E، يولد GET3D تمثيلات سطح صريحة (شبكات) دون تمثيلات ضمنية وسيطة.
ب) توليد النسيج: يتضمن النموذج تقنية عرض قابلة للتفاضل لتعلم وتوليد textures عالية الجودة للشبكات ثلاثية الأبعاد.
ج) هيكل قائم على GAN: يستخدم GET3D نهجًا قائمًا على GAN، مما يسمح بأوقات توليد سريعة مرةً ما يتم تدريب النموذج.
المزايا:
هندسة وtextures عالية الجودة
أوقات استدلال سريعة
التكامل المباشر مع محركات العرض ثلاثية الأبعاد
القيود:
يتطلب بيانات تدريب ثلاثية الأبعاد، والتي يمكن أن تكون نادرة لبعض فئات الكائنات
الختام
تمثل تقنية توليد 3D من النص بالذكاء الاصطناعي تحولًا جوهريًا في كيفية إنشاءنا وتفاعلنا مع المحتوى ثلاثي الأبعاد. من خلال الاستفادة من تقنيات الذكاء الاصطناعي المتقدمة، يمكن لهذه النماذج إنتاج أصول ثلاثية الأبعاد معقدة وعالية الجودة من وصف نصي بسيط. مع استمرار تطور التكنولوجيا، يمكننا期待 رؤية أنظمة توليد 3D من النص أكثر تطورًا وقدرة على التكيف، والتي ستثور في الصناعات من الألعاب إلى التصميم والهندسة المعمارية.
لقد قمت بإنفاق الخمس سنوات الماضية في غمرة العالم المثير للاهتمام من تعلم الآلة والتعلم العميق. وقد أدت شغفي وخبرتي إلى المساهمة في أكثر من 50 مشروعًا للهندسة البرمجية متنوعًا، مع التركيز بشكل خاص على الذكاء الاصطناعي / تعلم الآلة. كما أدت فضولي المستمر إلى جذبي نحو معالجة اللغة الطبيعية، وهو مجال أنا حريص على استكشافه بشكل أكبر.