الذكاء الاصطناعي
ذكرى أول عام لتشات جبت: إعادة تشكيل مستقبل التفاعل مع الذكاء الاصطناعي

عندما ننظر إلى ذكرى أول عام لتشات جبت، يبدو واضحًا أن هذا الأداة قد غيرت المشهد بشكل كبير. تم إطلاق تشات جبت في نهاية عام 2022، وتميزت بتصميمها المستخدم الصديق والنمط المحادثي الذي جعل التفاعل مع الذكاء الاصطناعي يشبه المحادثة مع شخص أكثر من الآلة. جذبت هذه النهج الجديدة الانتباه العام بسرعة. في غضون خمس أيام فقط بعد إطلاقها، جذبت تشات جبت مليون مستخدم. بحلول بداية عام 2023، ارتفع هذا الرقم إلى حوالي 100 مليون مستخدم شهريًا، وبحلول أكتوبر، كان المنصة يزورها حوالي 1.7 مليار زيارة في جميع أنحاء العالم. هذه الأرقام تتحدث عن شعبية الأداة وفائدتها.
على مدار العام الماضي، وجد المستخدمون طرقًا إبداعية لاستخدام تشات جبت، من المهام البسيطة مثل كتابة البريد الإلكتروني وتحديث السيرة الذاتية إلى بدء أعمال ناجحة. ولكن الأمر لا يتعلق فقط بكيفية استخدام الناس لها؛ فقد نمت التكنولوجيا نفسها وتحسنت. في البداية، كانت تشات جبت خدمة مجانية تقدم استجابات نصية مفصلة. الآن، هناك تشات جبت بلس، الذي يتضمن تشات جبت-4. هذا الإصدار المحدّث مدرب على المزيد من البيانات، ويقدم أقل عدد من الإجابات الخاطئة، ويفهم التعليمات المعقدة بشكل أفضل.
أحد أكبر التحديثات هو أن تشات جبت يمكنها الآن التفاعل بطرق متعددة – يمكنها الاستماع والتحدث ومعالجة الصور. هذا يعني أنك يمكنك التحدث معها من خلال تطبيق الهاتف المحمول وแสดงها الصور للحصول على استجابات. هذه التغييرات فتحت إمكانيات جديدة للذكاء الاصطناعي وغيّرت كيف ننظر إلى دور الذكاء الاصطناعي في حياتنا.
من بدايتها كتجربة تقنية إلى وضعها الحالي كلاعب رئيسي في عالم التكنولوجيا، رحلة تشات جبت مثيرة للإعجاب. في البداية، تم النظر إليها على أنها وسيلة لاختبار وتحسين التكنولوجيا من خلال الحصول على تعليقات من العامة. ولكنها سرعان ما أصبحت جزءًا أساسيًا من مشهد الذكاء الاصطناعي. هذا النجاح يظهر مدى فعالية تحسين النماذج اللغة الكبيرة (LLM) باستخدام التعلم الإشرافي وآراء البشر. ونتيجة لذلك، يمكن لتشات جبت التعامل مع مجموعة واسعة من الأسئلة والمهام.
سباق تطوير أنظمة الذكاء الاصطناعي الأكثر قدرة وتنوعًا أدى إلى انتشار النماذج المفتوحة والمملوكة. لفهم قدراتها العامة، يتطلب الأمر مقاييس شاملة عبر طيف واسع من المهام. هذا القسم يبحث في هذه المقاييس، ويشرح كيف تقف النماذج المختلفة، بما في ذلك تشات جبت، في مواجهة بعضها البعض.
تقييم LLMs: المقاييس
- MT-Bench: هذا المقاييس يختبر القدرة على المحادثة المتعددة والتعليمات التي تتبعها عبر ثمانية مجالات: الكتابة، والتمثيل، واستخراج المعلومات، والاستدلال، والرياضيات، والبرمجة، ومعارف العلوم والرياضيات، والعلوم الإنسانية والاجتماعية. يتم استخدام نماذج LLMs الأقوى مثل GPT-4 كمقييمين.
- AlpacaEval: يستند هذا المقاييس إلى مجموعة تقييم AlpacaFarm، ويقوم بتقييم النماذج باستخدام استجابات من نماذج LLMs متقدمة مثل GPT-4 وClaude، ويتابع معدل الفوز للنماذج المرشحة.
- لوحة ترتيب LLMs المفتوحة: باستخدام هارنيس تقييم النماذج اللغة، تقييم هذه اللوحة النماذج LLMs على سبعة مقاييس رئيسية، بما في ذلك تحديات الاستدلال واختبارات المعرفة العامة، في كل من الإعدادات بدون صور وعدد قليل من الصور.
- BIG-bench: يغطي هذا المقاييس التعاوني أكثر من 200 مهمة لغة جديدة، ويشمل مجموعة متنوعة من الموضوعات واللغات. يهدف إلى اختبار قدرات النماذج LLMs وتوقع قدراتها المستقبلية.
- ChatEval: إطار مناقشة متعدد الوكلاء يسمح للفرق بالمناقشة والتقويم التلقائي لجودة الاستجابات من نماذج مختلفة حول أسئلة مفتوحة ومهام توليد اللغة الطبيعية التقليدية.
الأداء المقارن
فيما يتعلق بالمقاييس العامة، أظهرت النماذج LLMs المفتوحة تقدمًا ملحوظًا. على سبيل المثال، Llama-2-70B حقق نتائج مثيرة للإعجاب، خاصة بعد التحسين مع بيانات التعليمات. تم تحقيق نتائج مماثلة من قبل Zephyr-7B، وهو نموذج أصغر، والذي أظهر قدرات قابلة للمقارنة مع نماذج LLMs أكبر حجمًا، خاصة في AlpacaEval وMT-Bench.
WizardLM-70B، الذي تم تحسينه مع مجموعة متنوعة من بيانات التعليمات، سجل أعلى درجة بين النماذج LLMs المفتوحة على MT-Bench. ومع ذلك، كان لا يزال متأخرًا عن GPT-3.5-turbo وGPT-4.
دخول مثير للاهتمام، GodziLLa2-70B، حقق درجة تنافسية على لوحة ترتيب LLMs المفتوحة، مما يظهر إمكانات النماذج التجريبية التي تجمع بين مجموعات بيانات متنوعة. وبالمثل، Yi-34B، الذي تم تطويره من الصفر، برز بنتائج قابلة للمقارنة مع GPT-3.5-turbo، ويتجاوزها قليلاً في بعض المجالات.
توسيع النطاق: صعود النماذج LLMs العملاقة
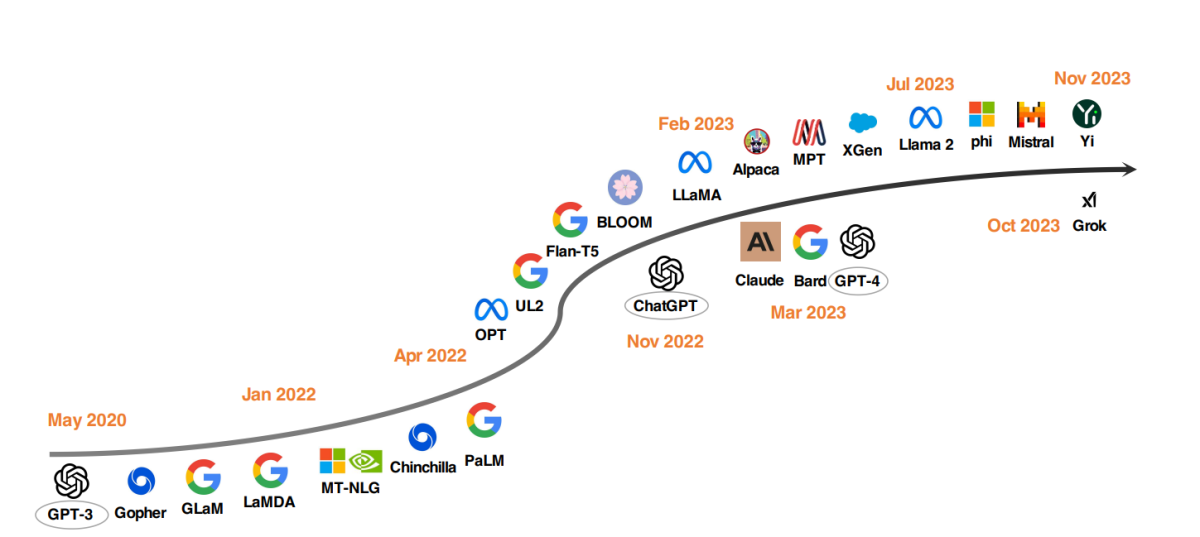
أفضل نماذج LLM منذ عام 2020
اتجاه ملحوظ في تطوير LLMs هو زيادة معاملات النموذج. قد مددت نماذج مثل Gopher وGLaM وLaMDA وMT-NLG وPaLM الحدود، مما أدى إلى نماذج تصل إلى 540 مليار معامل. أظهرت هذه النماذج قدرات استثنائية، ولكن طبيعتها المغلقة قد محدودت تطبيقها على نطاق أوسع. هذا الحد أثار اهتمامًا بتطوير نماذج LLMs مفتوحة المصدر، وهو اتجاه يكتسب زخمًا.
مُحفز تشات جبت
تمثل إطلاق OpenAI لتشات جبت نقطة تحول في أبحاث معالجة اللغة الطبيعية. للتنافس مع OpenAI، أطلقت شركات مثل Google وAnthropic نماذجها الخاصة، Bard وClaude، على التوالي. بينما تظهر هذه النماذج أداءً قابلاً للمقارنة مع تشات جبت في العديد من المهام، لا تزال متأخرة عن أحدث نموذج من OpenAI، GPT-4. يُعزى نجاح هذه النماذج بشكل رئيسي إلى تقنية التعلم التكراري من آراء البشر (RLHF)، وهي تقنية تلقى تركيزًا بحثيًا متزايدًا لتحسينها.
شائعات وتكهنات حول Q\* (نجم Q) من OpenAI
التقارير الحديثة تشير إلى أن الباحثين في OpenAI قد حققوا تقدمًا كبيرًا في الذكاء الاصطناعي من خلال تطوير نموذج جديد يسمى Q\* (يُلفظ Q نجم). يُزعم أن Q\* لديها القدرة على أداء حسابات على مستوى المدرسة الابتدائية، وهو إنجاز أثار مناقشات بين الخبراء حول إمكاناته كخطوة نحو الذكاء الاصطناعي العام (AGI). على الرغم من أن OpenAI لم تتعلي على هذه التقارير، إلا أن القدرات المزعومة ل Q\* أ.generated حماسة وتكهنات كبيرة على وسائل التواصل الاجتماعي و giữa محبي الذكاء الاصطناعي.
تطوير Q\* ملحوظ لأن النماذج الحالية مثل تشات جبت وGPT-4، على الرغم من قدراتها على بعض المهام الرياضية، ليست قادرة على التعامل معها بثبات. التحدي يكمن في الحاجة إلى أن يتعرف النماذج على الأنماط، كما تفعل حاليًا من خلال التعلم العميق والتحويلات، ولكن أيضًا على التفكير والفهم المفاهيمي. الرياضيات، كونه معيارًا للتفكير، تتطلب من الذكاء الاصطناعي التخطيط والتنفيذ الخطوات المتعددة، مما يظهر فهمًا عميقًا للمفاهيم المجردة. هذه القدرة ستمثل قفزة كبيرة في قدرات الذكاء الاصطناعي، وربما تمتد إلى ما وراء الرياضيات إلى مهام معقدة أخرى.
حركة LLMs المفتوحة المصدر
لدعم البحث في نماذج LLMs المفتوحة المصدر، أصدرت Meta سلسلة نماذج Llama، مما أدى إلى موجة جديدة من التطورات القائمة على Llama. تشمل هذه النماذج مثل Alpaca وVicuna وLima وWizardLM، والتي تم تحسينها مع بيانات التعليمات. كما أن البحث يتفرع إلى تعزيز قدرات الوكيل والاستدلال المنطقي ونمذجة السياق الطويل داخل إطار Llama.
تأثير تشات جبت والنماذج المفتوحة المصدر على الرعاية الصحية
نحن ننظر إلى مستقبل حيث تساعد النماذج LLMs في كتابة الملاحظات السريرية وملء الاستمارات للتعويضات ودعم الأطباء في التشخيص وتخطيط العلاج. لقد لفتت هذه التطورات انتباه كلاً من العمالقة التكنولوجية ومؤسسات الرعاية الصحية.
مناقشات Microsoft مع Epic، وهي شركة رائدة في برامج سجلات الصحة الإلكترونية، تشير إلى دمج النماذج LLMs في الرعاية الصحية. هناك مبادرات قيد التنفيذ في UC San Diego Health وStanford University Medical Center. وبالمثل، شراكات Google مع Mayo Clinic وخدمة التوثيق السريرية بالذكاء الاصطناعي من Amazon Web Services تحدد خطوات كبيرة في هذا الاتجاه.
ومع ذلك، تثير هذه التطورات السريعة مخاوف حول تسليم السيطرة على الطب للشركات. طبيعة النماذج LLMs المملوكة تجعل من الصعب تقييمها. تعديلها أو إيقافها لأسباب ربحية يمكن أن يضعف رعاية المرضى والخصوصية والأمان.
الاحتياج الملح هو لمقاربة مفتوحة وشاملة لتطوير النماذج LLMs في الرعاية الصحية. يجب على مؤسسات الرعاية الصحية والباحثين والأطباء والمرضى التعاون على المستوى العالمي لبناء نماذج LLMs مفتوحة المصدر للرعاية الصحية. هذا النهج، مشابه لاتحاد المليار معامل، سيمكن من تجميع الموارد الحاسوبية والمالية والخبرات.












