AI 101
Wat is CNN's (Convolutional Neural Networks)?
Miskien het jy gewonder hoe Facebook of Instagram outomaties gesigte in 'n prent kan herken, of hoe Google jou op die web vir soortgelyke foto's laat soek deur net 'n foto van jou eie op te laai. Hierdie kenmerke is voorbeelde van rekenaarvisie, en hulle word aangedryf deur konvolusionele neurale netwerke (CNN's). Maar wat presies is konvolusionele neurale netwerke? Kom ons neem 'n diep duik in die argitektuur van 'n CNN en verstaan hoe hulle werk.
Wat is neurale netwerke?
Voordat ons begin praat oor konvolusionele neurale netwerke, laat ons 'n oomblik neem om gereelde neurale netwerk te definieer. Daar is 'n ander artikel oor die onderwerp van beskikbare neurale netwerke, so ons sal nie hier te diep daarop ingaan nie. Om hulle egter kortliks te definieer, is dit berekeningsmodelle wat deur die menslike brein geïnspireer is. ’n Neurale netwerk werk deur data in te neem en die data te manipuleer deur “gewigte” aan te pas, wat aannames is oor hoe die invoerkenmerke met mekaar en die voorwerp se klas verband hou. Soos die netwerk opgelei word, word die waardes van die gewigte aangepas en hulle sal hopelik konvergeer op gewigte wat die verhoudings tussen kenmerke akkuraat vasvang.
Dit is hoe 'n voorwaartse neurale netwerk werk, en CNN'e bestaan uit twee helftes: 'n voorwaartse neurale netwerk en 'n groep konvolusionele lae.
Wat is Convolution Neurale Networks (CNN's)?
Wat is die "konvolusies" wat in 'n konvolusionele neurale netwerk gebeur? 'n Konvolusie is 'n wiskundige bewerking wat 'n stel gewigte skep, wat in wese 'n voorstelling van dele van die beeld skep. Hierdie stel gewigte word na verwys as 'n pit of filter. Die filter wat geskep word, is kleiner as die hele insetprent, wat net 'n onderafdeling van die prent dek. Die waardes in die filter word vermenigvuldig met die waardes in die prent. Die filter word dan oorgeskuif om 'n voorstelling van 'n nuwe deel van die beeld te vorm, en die proses word herhaal totdat die hele beeld bedek is.
Nog 'n manier om hieroor te dink, is om 'n baksteenmuur voor te stel, met die stene wat die pixels in die insetbeeld verteenwoordig. 'n "Venster" word heen en weer langs die muur geskuif, wat die filter is. Die stene wat deur die venster sigbaar is, is die pixels met hul waarde vermenigvuldig met die waardes binne die filter. Om hierdie rede word hierdie metode om gewigte met 'n filter te skep dikwels na verwys as die "skuifvensters"-tegniek.
Die uitset van die filters wat om die hele insetbeeld geskuif word, is 'n tweedimensionele skikking wat die hele beeld verteenwoordig. Hierdie skikking word 'n "kenmerkkaart" genoem.
Waarom konvolusies noodsaaklik is
Wat is in elk geval die doel daarvan om konvolusies te skep? Konvolusies is nodig omdat 'n neurale netwerk die pixels in 'n beeld as numeriese waardes moet kan interpreteer. Die funksie van die konvolusionele lae is om die beeld om te skakel in numeriese waardes wat die neurale netwerk kan interpreteer en dan relevante patrone uit te haal. Die taak van die filters in die konvolusionele netwerk is om 'n tweedimensionele reeks waardes te skep wat na die latere lae van 'n neurale netwerk oorgedra kan word, dié wat die patrone in die beeld sal leer.
Filters en kanale
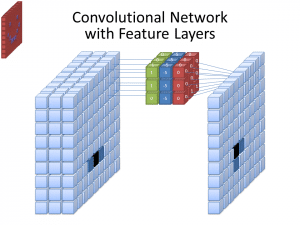
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN's gebruik nie net een filter om patrone van die invoerbeelde te leer nie. Veelvuldige filters word gebruik, aangesien die verskillende skikkings wat deur die verskillende filters geskep word, lei tot 'n meer komplekse, ryk voorstelling van die insetbeeld. Algemene getalle filters vir CNN'e is 32, 64, 128 en 512. Hoe meer filters daar is, hoe meer geleenthede het die CNN om die insetdata te ondersoek en daaruit te leer.
'n CNN ontleed die verskille in pixelwaardes om die grense van voorwerpe te bepaal. In 'n grysskaalbeeld sou die CNN slegs kyk na die verskille in swart en wit, lig-tot-donker terme. Wanneer die beelde kleurbeelde is, neem die CNN nie net donker en lig in ag nie, maar moet dit ook die drie verskillende kleurkanale – rooi, groen en blou – in ag neem. In hierdie geval beskik die filters oor 3 kanale, net soos die beeld self. Die aantal kanale wat 'n filter het, word na verwys as sy diepte, en die aantal kanale in die filter moet ooreenstem met die aantal kanale in die prent.
Convolutional Neural Network (CNN) argitektuur
Kom ons kyk na die volledige argitektuur van 'n konvolusionele neurale netwerk. 'n Konvolusionele laag word aan die begin van elke konvolusienetwerk gevind, aangesien dit nodig is om die beelddata in numeriese skikkings te transformeer. Konvolusionele lae kan egter ook na ander konvolusionele lae kom, wat beteken dat hierdie lae bo-op mekaar gestapel kan word. Om veelvuldige konvolusionele lae te hê, beteken dat die uitsette van een laag verdere konvolusies kan ondergaan en saam in relevante patrone gegroepeer kan word. Prakties beteken dit dat die netwerk meer komplekse kenmerke van die beeld begin "herken" namate die beelddata deur die konvolusionele lae gaan.
Die vroeë lae van 'n ConvNet is verantwoordelik vir die onttrekking van die lae-vlak kenmerke, soos die pixels waaruit eenvoudige lyne bestaan. Latere lae van die ConvNet sal hierdie lyne saamvoeg in vorms. Hierdie proses om van oppervlak-vlak-analise na diepvlak-analise te beweeg, duur voort totdat die ConvNet komplekse vorms soos diere, menslike gesigte en motors herken.
Nadat die data deur al die konvolusionele lae gegaan het, gaan dit voort na die dig gekoppelde deel van die CNN. Die dig-gekoppelde lae is hoe 'n tradisionele toevoer-neurale netwerk lyk, 'n reeks nodusse wat in lae gerangskik is wat met mekaar verbind is. Die data gaan deur hierdie digverbonde lae, wat die patrone leer wat deur die konvolusionele lae onttrek is, en sodoende word die netwerk in staat om voorwerpe te herken.








