人工智能
不,他们没有限制克劳德——事实上情况更糟

好吧,我们来谈谈发生了什么事 克劳德,因为如果您在过去一个月内一直在使用它,您可能会注意到有些不对劲。
过去六周里,克劳德的用户们都疯了。从八月初开始, Reddit、X 和开发者论坛上开始充斥着各种投诉。问题无处不在:
- 曾经完美运行的代码突然崩溃
- Claude 会声称它修改了文件,但实际上并没有
- 英文回复中出现随机泰语或中文字符
- 指示被完全忽略
- 相同的提示给出截然不同的响应质量
- Claude Code 用户表示,与之前相比,这款游戏感觉“像被切除了脑叶”
投诉愈演愈烈,到了八月底,人们甚至开始怀疑 Anthropic 暗中限制 Claude 的网速以节省成本。各种阴谋论层出不穷——他们或许在高峰时段降低了服务质量,或许悄悄换了更便宜的型号,又或许是为了控制服务器成本而故意降级。
用户付费 克劳德·普罗 并获得了感觉像 Claude Lite 一样的功能。那些围绕 Claude 构建工作流程的开发人员突然发现他们的生产力下降了。话虽如此,有些用户却完全没有遇到任何问题,这让一切变得更加混乱。
Anthropic 终于承认:是的,我们遇到了问题
经过数周的用户投诉和日益增长的挫败感, Anthropic 刚刚发布了一份大规模技术分析报告 这句话的意思基本上是:“你是对的。克劳德崩溃了。事情是这样的。”
答案很有趣。
事实证明,问题并非单一的。而是三个完全独立的基础设施漏洞,它们同时出现,造成了一场人工智能性能下降的完美风暴。它们并没有节流,也没有偷工减料。只是三个不同的组件同时出现故障,导致他们花了六周时间才完全理解并修复。
让我来分析一下到底哪里出了问题,因为这实际上有助于我们了解这些人工智能系统是如何以无人预料的方式失败的。
三重漏洞灾难:混乱的时间线
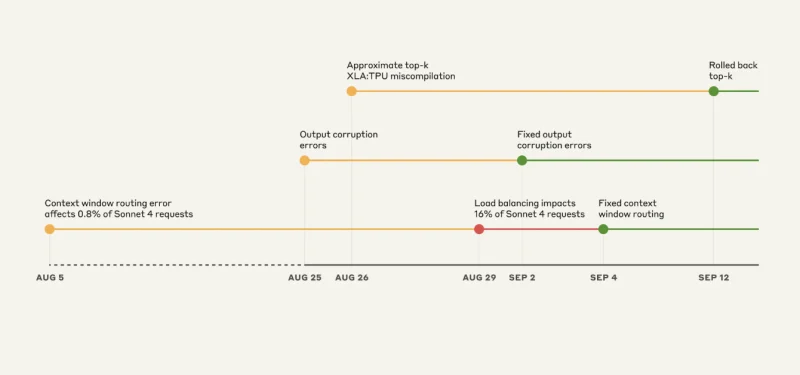
来源:Anthropic
错误 #1:错误的服务器问题
如果你不是亲身经历过,这几乎会很有趣。Claude Sonnet 4 的设计目标是处理 200,000 万个令牌上下文。但从 5 月 1 日开始,一些请求被路由到配置为处理 XNUMX 万个令牌上下文的服务器上。
最初,只有 0.8% 的请求受到影响。没什么大不了的,对吧?错了。
29 月 16 日,一次例行负载均衡器更新让这个小问题变成了大问题。突然间,在峰值时,4% 的 Sonnet XNUMX 请求被发送到了错误的服务器。而且路由“粘滞”了。一旦路由错误,就会一直被路由错误。
影响:
- 大约 30% 的 Claude Code 用户在窗口期内至少有一个请求被误传
- 受影响用户的响应时间缩短
- 同一用户会反复遇到该问题,而其他用户则没有任何问题
Bug #2:随机字符生成器
25 月 XNUMX 日,Anthropic 的 TPU 服务器配置出现错误。结果导致 Claude 开始在英文回复中随机插入泰语和中文字符。
想象一下让 Claude 调试你的 Python 代码并得到以下结果:
def calculate_total(items):
total = 0
for item in items:
總計 += item.price # <- What?
return ผลรวม
这影响了:
- Opus 4.1 和 Opus 4:25 月 28 日至 XNUMX 日
- 十四行诗 4:25 月 2 日 - XNUMX 月 XNUMX 日
技术原因在于一个词条生成错误,它给原本不该出现的字符分配了高概率。这实际上破坏了克劳德选择下一个要说的单词的基本机制。
Bug #3:隐形编译器 Bug
从工程角度来看,这是一件可怕的事情。谷歌的 XLA 编译器中存在一个潜伏的 bug。当 Anthropic 在 25 月 XNUMX 日部署代码来改进 token 选择时,他们意外地触发了这个 bug。
这个漏洞的作用实在是太奇怪了——它会导致克劳德在生成文本时无意中排除最有可能的标记。克劳德知道正确答案,但却被物理因素阻止了说出来。
真正糟糕的部分是什么?他们实际上早在 2024 年 XNUMX 月就绕过了这个漏洞,却浑然不知。当他们在 XNUMX 月“修复”了他们认为的根本原因时,却删除了解决方法,从而暴露了真正的问题。
为什么花了六周时间才修复
你可能会想:像 Anthropic 这样拥有世界一流工程师的公司怎么会花六周时间来解决这个问题呢?
答案揭示了这些系统到底有多么复杂:
1.隐私控制阻止调试
“我们的内部隐私和安全控制限制了工程师如何以及何时可以访问用户与 Claude 的互动,特别是当这些互动没有作为反馈报告给我们时。”
除非用户明确反馈,否则他们根本无法发现问题所在。这对隐私保护有利,但对调试却不利。
2. 虫子藏起来了
克劳德经常能从个别错误中恢复过来,使得性能下降看起来像是正常方差,而不是系统性故障。他们的基准测试和评估并没有捕捉到这一点,因为模型会进行自我修正,刚好足以通过测试。
3. 多平台混乱
Claude 在 AWS Trainium 上运行, NVIDIA公司 GPU 和 Google TPU——三个完全不同的硬件平台。每个 bug 在每个平台上的表现都不同:
- AWS Bedrock:高峰期 0.18% 的 Sonnet 4 请求受到影响
- Google Vertex AI:受影响率低于 0.0004%
- 直接 API:受影响人数高达 16%
这使得它看起来像多个不相关的问题而不是三个特定的错误。
4. 重叠症状
由于三个漏洞同时存在,各种症状各异。一个用户可能显示泰语字符,另一个用户可能响应变差,而第三个用户则可能运行正常。没有明确的规律可循。
这对人工智能可靠性意味着什么
整个故事揭示了人工智能系统当前状态的一些关键问题:它们比看起来要脆弱得多。
我们讨论的不仅仅是人工智能模型本身。我们讨论的是:
- 路由基础设施可能会将请求发送到错误的地方
- 特定于硬件的实现,其行为有所不同
- 可能潜伏数月的编译器错误
- 负载均衡器可能会将小问题放大为重大中断
一次配置错误、一个编译器错误、一次路由错误——突然间你的人工智能助手就会忘记如何编码或开始说不该说的语言。
它真的修好了吗?
Anthropic 表示,截至 16 月 XNUMX 日,他们已经解决了所有三个问题。他们:
- 修复了路由逻辑
- 回滚有问题的配置
- 从近似到精确的 top-k 操作(为了提高准确性,性能会受到影响)
- 增加了持续生产监控
但是, 用户仍在报告问题一些开发者表示,《克劳德密码》的表现与之前相比仍然有所下降。例如:
- 虫子的持续影响
- 尚未发现的新问题
- 数周问题之后的心理偏见
- 或实际持续退化
…我们还不知道。
底线
这种情况完美地展现了复杂的人工智能系统如何以完全出乎意料的方式失效。三个独立的漏洞,在几周内相继触发,造成了严重的质量下降,诊断和修复耗时六周。
我们应该对 Anthropic 的透明度表示赞赏。发布详细的技术分析报告比大多数公司做得更好。但这也表明,在我们日益依赖的这些系统背后,有多少问题可能出现。
对于任何基于 Claude 或任何 LLM 进行构建的人来说:你需要冗余、验证和备份计划。因为正如我们刚刚看到的,即使是最好的 AI 系统也可能同时面临三个不同的问题,而且可能需要数周时间才能弄清楚到底发生了什么。
支持这些人工智能模型的基础设施与模型本身同样重要。而目前,这些基础设施正面临严重的发展困境。












