人工智能
Deepfake 视频中的保真度与现实主义

并非所有深度造假从业者都有相同的目标:图像合成研究领域的推动力——得到了有影响力的支持者的支持,例如 Adobe, NVIDIA公司 与 Facebook – 是为了推进最先进的技术,以便机器学习技术最终能够在最具挑战性的条件下以高分辨率重新创建或合成人类活动(保真度).
相比之下,那些希望利用深度伪造技术传播虚假信息的人,其目标是通过许多其他方法,创造出逼真的真人模拟,而不仅仅是深度伪造人脸的真实性。在这种情况下,诸如背景和可信度等附加因素几乎等同于视频模拟人脸的潜力。 (现实主义).
这种“花招”方法延伸到深度伪造视频最终图像质量的下降,以便整个视频(而不仅仅是深度伪造脸部所代表的欺骗性部分)具有与媒体预期质量一致的凝聚力“外观”。
“凝聚力”并不一定意味着“好”——只要原始内容和插入的、掺假的内容质量一致,并符合预期就足够了。就 Skype 和 Zoom 等平台上的 VOIP 流媒体输出而言,标准可能非常低,存在卡顿、视频抖动以及一系列潜在的压缩伪影,以及旨在降低其影响的“平滑”算法——这些算法本身就构成了一系列额外的“不真实”效果,我们已经接受了这些效果是直播局限性和怪异性的必然结果。
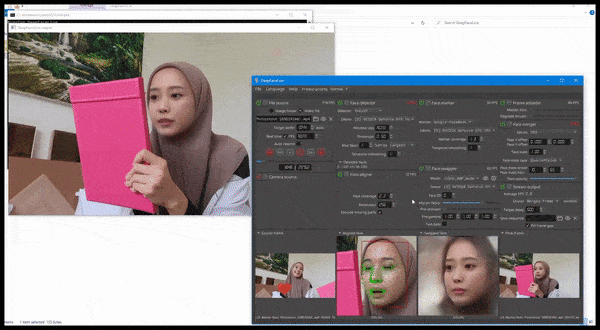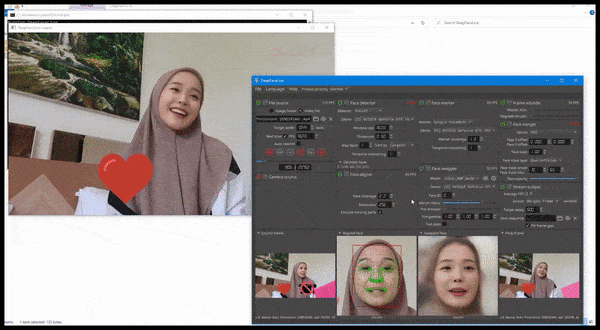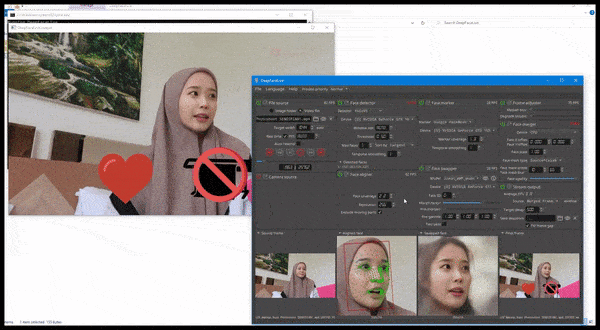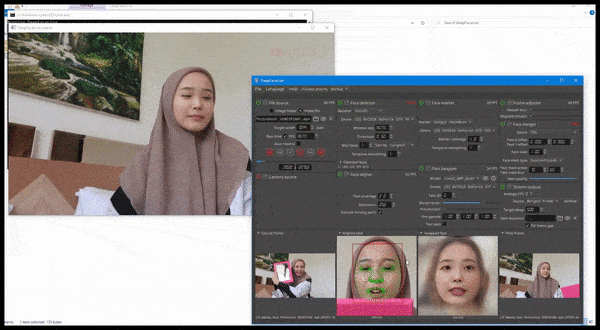
DeepFaceLive 的实际应用:这款顶级 DeepFaceLab 的流媒体版本可以通过在有限的视频质量环境中呈现假货来提供情境真实感,并解决播放问题和其他经常出现的连接问题。 来源:https://www.youtube.com/watch?v=IL517EgYH8U
内置退化
事实上,两个最受欢迎的深度伪造软件包(均源自备受争议的 2017 年源代码)都包含旨在通过降低生成人脸的质量,将深度伪造的人脸融入“历史”或低质量视频的环境中的组件。在 深度人脸实验室, 双三次降级功率 参数实现了这一点,并且在 换脸,Ffmpeg 配置中的“grain”设置同样有助于通过在编码期间保留颗粒来整合虚假面部*。

FaceSwap 中的“颗粒”设置有助于真实地融入非 HQ 视频内容,以及可能具有如今相对罕见的胶片颗粒效果的传统内容。
通常,deepfakes 会输出一系列带有 Alpha 通道的独立 PNG 文件,而不是完整且集成的 Deepfake 视频,每个图像仅显示合成面部输出,以便图像流可以在更复杂的平台中转换为视频。降低”效果的能力,例如 Adobe After Effects,在将虚假元素和真实元素结合在一起形成最终视频之前。
除了这些故意的降级之外,深度伪造作品的内容还经常被重新压缩,要么是通过算法(社交媒体平台试图通过制作用户上传的更轻量版本来节省带宽)在 YouTube 和 Facebook 等平台上进行,要么通过将原始作品重新处理为动画 GIF、细节部分或其他具有不同动机的工作流程,将原始版本视为起点,然后引入额外的压缩。
真实的 Deepfake 检测上下文
考虑到这一点,瑞士的一篇新论文提出了对 Deepfake 检测方法背后的方法进行修改,通过教导检测系统学习 Deepfake 内容在故意降级的环境中呈现时的特征。

随机数据增强应用于新论文中使用的数据集之一,具有高斯噪声、伽马校正和高斯模糊,以及 JPEG 压缩的伪影。 资料来源:https://arxiv.org/pdf/2203.11807.pdf
在新论文中,研究人员认为,先锋深度伪造检测程序依赖于不切实际的基准条件作为其应用指标的背景,并且“降级”的深度伪造输出可能会低于检测的最低质量阈值,即使它们现实中“肮脏”的内容可能会由于正确关注背景而欺骗观众。
研究人员设计了一种新颖的“真实世界”数据降级流程,成功提升了领先的深度伪造检测器的通用性,且与“干净”数据获得的原始检测率相比,准确率仅略有下降。他们还提出了一个全新的评估框架,用于评估深度伪造检测器在真实世界条件下的稳健性,该框架得到了大量消融研究的支持。
这个 纸 标题为 一种改进现实条件下基于学习的 Deepfake 检测的新方法,来自位于洛桑的多媒体信号处理小组 (MMSPG) 和洛桑联邦理工学院 (EPFL) 的研究人员。
有用的混乱
先前将降级输出纳入深度伪造检测方法的努力包括 混合神经网络,2018 年由 MIT 和 FAIR 提供的产品,以及 八月混合这是 DeepMind 和 Google 于 2020 年合作推出的一项数据增强方法,这两种方法都试图以一种有助于泛化的方式“混淆”训练材料。
这项新工作的研究人员还指出 先 研究 将高斯噪声和压缩伪影应用于训练数据,以建立派生特征与其所嵌入的噪声之间的关系边界。
这项新研究提供了一个流程,模拟了图像采集和压缩过程中可能出现的受损情况,以及分发过程中可能进一步降低图像输出质量的各种其他算法。通过将这一真实工作流程纳入评估框架,可以为深度伪造检测器生成更能抵抗伪影的训练数据。

新方法的概念逻辑和工作流程。
降级过程应用于用于深度伪造检测的两个流行且成功的数据集: 人脸取证++ 与 Celeb-DFv2。 此外,领先的 Deepfake 检测器框架 胶囊取证 与 XceptionNet 对两个数据集的掺假版本进行了培训。
检测器分别使用 Adam 优化器进行了 25 和 10 epoch 的训练。 对于数据集转换,在添加降级过程之前,从每个训练视频中随机采样 100 帧,并提取 32 帧用于测试。
工作流程考虑的扭曲是 噪声,其中零均值高斯噪声应用于六个不同的级别; 调整大小,模拟典型户外镜头的分辨率降低,这可以 通常会影响 探测器; 压片,其中对数据应用了不同的 JPEG 压缩级别; 平滑其中,针对该框架评估了“去噪”中使用的三个典型平滑滤波器; 增强,其中对比度和亮度已调整; 和 组合,其中上述三种方法的任意组合同时应用于单个图像。
测试和结果
在测试数据时,研究人员采用了三个指标:准确性(ACC); 接收器工作特性曲线下的面积(AUC); 和 F1分数.
研究人员针对掺假数据测试了两个 Deepfake 探测器的标准训练版本,发现它们缺乏:
总体而言,大多数真实的扭曲和处理对基于学习的常规训练的深度伪造检测器而言极其有害。例如,Capsule-Forensics 方法在未压缩的 FFpp 和 Celeb-DFv2 测试集上分别进行训练后,均表现出非常高的 AUC 得分,但随后在我们评估框架的修改数据上性能急剧下降。XceptionNet 检测器也观察到了类似的趋势。
相比之下,通过对转换后的数据进行训练,两个检测器的性能显着提高,每个检测器现在更有能力检测看不见的欺骗性媒体。
“数据增强方案显著提高了两个检测器的鲁棒性,同时它们在原始未改变的数据上仍然保持高性能。”

研究中评估的两个 Deepfake 探测器使用的原始数据集和增强数据集之间的性能比较。
论文的结论是:
“当前的检测方法旨在在特定基准上实现尽可能高的性能。 这通常会导致牺牲更现实场景的泛化能力。 在本文中,提出了一种基于自然图像退化过程的精心设计的数据增强方案。
“大量实验表明,这种简单但有效的技术显著提高了模型对典型成像工作流程中各种现实扭曲和处理操作的鲁棒性。”
* 生成的脸部中的匹配颗粒是转换过程中风格转移的函数。
首次发布于 29 年 2022 月 8 日。美国东部时间晚上 33:XNUMX 更新,以澄清 Ffmpeg 中的grain 使用。












