
Вештачка интелигенција
Обука модела рачунарског вида на случајном шуму уместо стварних слика

Истраживачи из Лабораторије за компјутерске науке и вештачку интелигенцију МИТ (ЦСАИЛ) експериментисали су са коришћењем насумичних слика буке у скуповима података компјутерског вида за обуку модела компјутерског вида и открили да је уместо да производи смеће, метода изненађујуће ефикасна:

Генеративни модели из експеримента, сортирани по перформансама. Извор: хттпс://опенревиев.нет/пдф?ид=РКУл8гЗнН7О
Уношење привидног 'визуелног смећа' у популарне архитектуре компјутерског вида не би требало да резултира овом врстом перформанси. На крајњој десној страни горње слике, црне колоне представљају оцене тачности (укључено Имагенет-100) за четири 'права' скупа података. Док скупови података 'случајног шума' који му претходе (на слици у различитим бојама, погледајте индекс горе лево) не могу да се поклапају са тим, скоро сви су унутар респектабилних горњих и доњих граница (црвене испрекидане линије) за тачност.
У овом смислу 'тачност' не значи да резултат нужно изгледа као а правитије цркваје пица, или било који други одређени домен за који бисте могли бити заинтересовани да креирате синтеза слике систем, као што је генеративна супарничка мрежа, или оквир за кодирање/декодер.
Уместо тога, то значи да су ЦСАИЛ модели извели широко применљиве централне 'истине' из сликовних података тако очигледно неструктурираних да не би требало да буду у стању да их обезбеде.
Диверсити Вс. Натурализам
Ни ови резултати се не могу приписати претерано доликује: живахан дискусија између аутора и рецензената на Опен Ревиев открива да мешање различитог садржаја из визуелно различитих скупова података (као што су „мртво лишће“, „фрактали“ и „процедурална бука“ – погледајте слику испод) у скуп података за обуку заправо побољшава прецизност у овим експериментима.
Ово сугерише (и то је помало револуционаран појам) нови тип „недовољног уклапања“, где „разноликост“ надмашује „натурализам“.
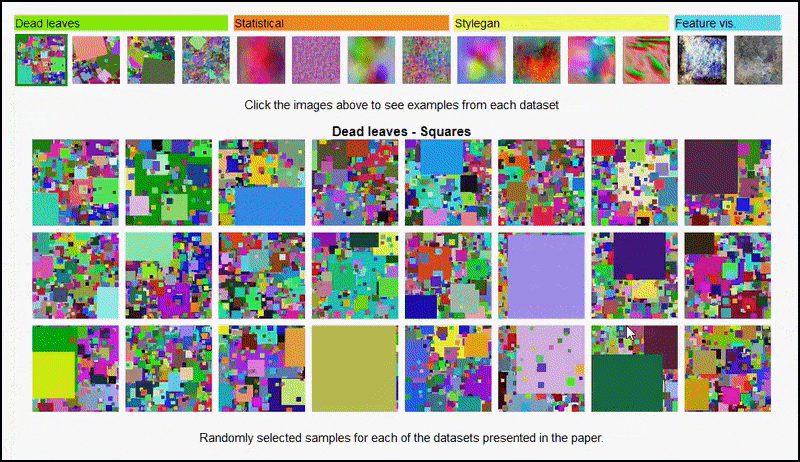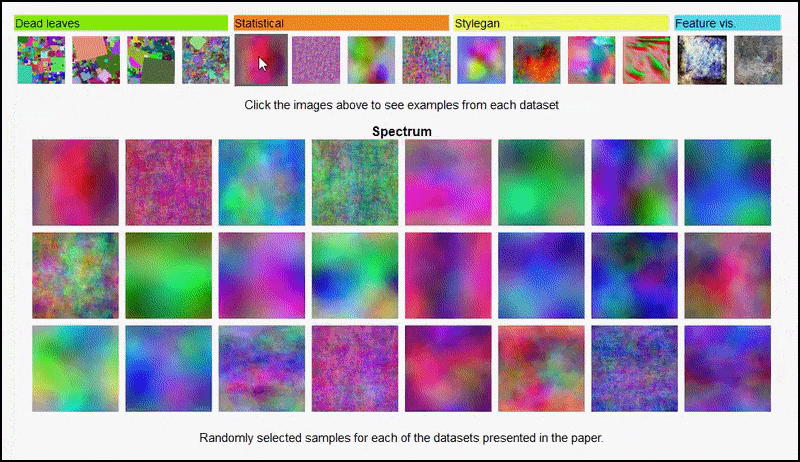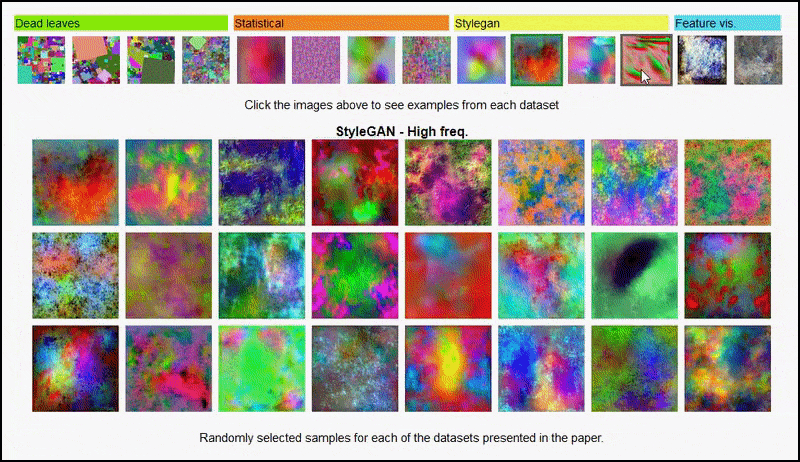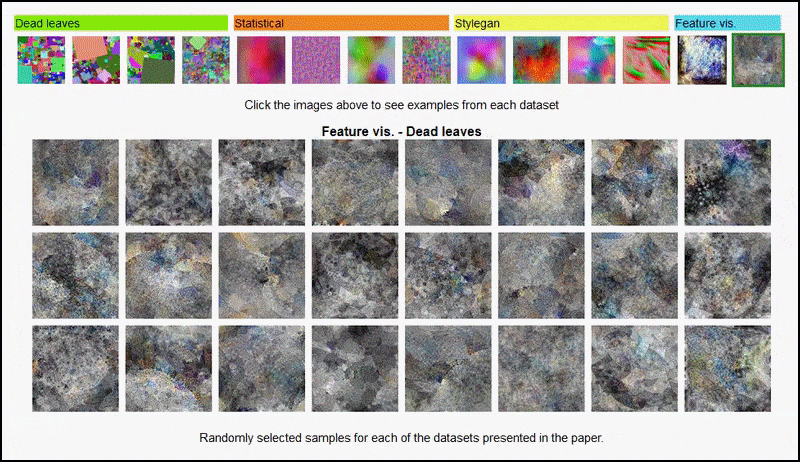
Пројекат страна јер иницијатива вам омогућава да интерактивно видите различите типове насумичних скупова слика који се користе у експерименту. Извор: хттпс://мбарадад.гитхуб.ио/леарнинг_витх_ноисе/
Резултати до којих су дошли истраживачи доводе у питање фундаменталну везу између неуронских мрежа заснованих на сликама и слика „стварног света“ које им се алармантно бацају. веће количине сваке године, и имплицирају потребу да се прибаве, курирају и на други начин препиру скупови слика у хиперскали може на крају постати сувишан. Аутори наводе:
„Тренутни системи визије су обучени на огромним скуповима података, а ови скупови података имају трошкове: курирање је скупо, они наслеђују људске предрасуде и постоји забринутост око приватности и права коришћења. Да би се супротставили овим трошковима, порасло је интересовање за учење из јефтинијих извора података, као што су слике без ознака.
„У овом раду идемо корак даље и питамо се да ли можемо у потпуности да укинемо скупове података стварних слика, учењем из процеса процедуралне буке.“
Истраживачи сугеришу да тренутна генерација архитектура машинског учења може закључити нешто много фундаменталније (или, барем, неочекивано) из слика него што се раније мислило, и да 'бесмислице' слике потенцијално могу пренети велики део овог знања далеко више јефтино, чак и уз могућу употребу ад хоц синтетичких података, преко архитектуре за генерисање скупова података које генеришу насумичне слике у време обуке:
'Идентификујемо две кључне особине које чине добре синтетичке податке за тренинг система вида: 1) природност, 2) разноврсност. Занимљиво је да најприродословнији подаци нису увек најбољи, јер натурализам може доћи по цену различитости.
„Чињеница да натуралистички подаци помажу можда није изненађујућа, а сугерише да заиста стварни подаци великих размера имају вредност. Међутим, налазимо да оно што је кључно није да подаци буду прави али да буде натуралистички, односно мора да обухвати одређена структурна својства стварних података.
'Многа од ових својстава могу се ухватити у једноставним моделима буке.'

Визуелизације карактеристика које су резултат кодера изведеног из АлекНет-а на неким од различитих скупова података 'случајних слика' које користе аутори, покривајући 3. и 5. (коначни) конволуцијски слој. Методологија која се овде користи прати ону из Гоогле истраживање вештачке интелигенције из 2017.
папир, представљен на 35. конференцији о системима за неуралну обраду информација (НеурИПС 2021) у Сиднеју, под називом Учење да се види гледајући у буку, и долази од шест истраживача са ЦСАИЛ-а, са једнаким доприносом.
Посао је био Препоручује се консензусом за избор у центру пажње на НеурИПС 2021, са колегама коментаторима који окарактеришу рад као „научно откриће“ које отвара „велику област проучавања“, чак и ако поставља онолико питања колико даје одговоре.
У раду аутори закључују:
„Показали смо да, када су дизајнирани користећи резултате из прошлих истраживања статистике природних слика, ови скупови података могу успешно тренирати визуелне репрезентације. Надамо се да ће овај рад мотивисати проучавање нових генеративних модела способних да произведу структурирану буку постижући још веће перформансе када се користе у разноврсном скупу визуелних задатака.
„Да ли би било могуће упоредити перформансе добијене са ИмагеНет претренингом? Можда у одсуству великог скупа обуке специфичног за одређени задатак, најбоља пред-обука можда неће бити коришћење стандардног стварног скупа података као што је ИмагеНет.'















