
Вештачка интелигенција
СтилеТТС 2: Претварање текста у говор на нивоу човека са великим моделима говорног језика

Захваљујући повећању природног и синтетичког приступа синтези говора, једно од главних достигнућа које је индустрија вештачке интелигенције постигла у последњих неколико година јесте да ефикасно синтетише оквире за претварање текста у говор са потенцијалним апликацијама у различитим индустријама, укључујући аудио књиге, виртуелне асистенте, глас. -преко нарација и још много тога, са неким најсавременијим модовима који пружају перформансе и ефикасност на нивоу човека у широком спектру задатака везаних за говор. Међутим, упркос њиховим снажним перформансама, још увек има простора за побољшање задатака захваљујући експресивном и разноликом говору, захтеву за великом количином података за обуку за оптимизацију оквира текста од нулте слике до говорних оквира и робусности за ООД или ван дистрибуције текстове који воде програмери да раде на робуснијем и приступачнијем оквиру текста у говор.
У овом чланку ћемо говорити о СтилеТТС-2, робусном и иновативном оквиру текста у говор који је изграђен на темељима СтилеТТС оквира, а има за циљ да представи следећи корак ка најсавременијим системима текста у говор. Оквир СтилеТТС2 моделира стилове говора као латентне случајне променљиве и користи модел вероватноће дифузије за узорковање ових стилова говора или случајних променљивих, чиме омогућава СтилеТТС2 оквиру да ефикасно синтетише реалистичан говор без коришћења референтних аудио улаза. Захваљујући приступу, СтилеТТС2 оквир је у стању да пружи боље резултате и показује високу ефикасност у поређењу са тренутним стањем уметности текст и говорне оквире, али је такође у стању да искористи предности разноврсне синтезе говора коју нуде оквири дифузионих модела. Разговараћемо детаљније о СтилеТТС2 оквиру, и разговараћемо о његовој архитектури и методологији, а такође ћемо погледати резултате постигнуте оквиром. Па хајде да почнемо.
СтилеТТС2 за синтезу текста у говор: Увод
СтилеТТС2 је иновативни модел синтезе текста у говор који чини следећи корак ка изградњи ТТС оквира на људском нивоу, а изграђен је на СтилеТТС, тексту заснованом на стилу за говорни генеративни модел. Оквир СтилеТТС2 моделира стилове говора као латентне случајне променљиве и користи модел вероватноће дифузије за узорковање ових стилова говора или случајних променљивих, чиме омогућава СтилеТТС2 оквиру да ефикасно синтетише реалистичан говор без коришћења референтних аудио улаза. Моделирање стилова као латентних насумичних варијабли је оно што одваја СтилеТТС2 оквир од његовог претходника, СтилеТТС оквира, и има за циљ да генерише најпогоднији стил говора за улазни текст без потребе за референтним аудио улазом, и може да постигне ефикасне латентне дифузије док узима предност разноврсних могућности синтезе говора које нуди дифузиони модели. Поред тога, СтилеТТС2 оквир такође користи унапред обучени велики СЛМ или модел говорног језика као дискриминаторе као што је ВавЛМ оквир, и упарује га са сопственим новим приступом моделирања диференцијалног трајања како би обучио оквир од краја до краја и на крају генерисао говор са побољшаном природношћу. Захваљујући приступу који следи, СтилеТТС2 оквир надмашује тренутне најсавременије оквире за задатке генерисања говора и један је од најефикаснијих оквира за пре-тренинг великих говорних модела у нултом подешавању за задатке прилагођавања говорника.
Идући даље, како би се текст на нивоу човека испоручио у синтезу говора, СтилеТТс2 оквир укључује учења из постојећих радова, укључујући моделе дифузије за синтезу говора и велике моделе говорног језика. Дифузиони модели се обично користе за задатке синтезе говора захваљујући њиховим способностима за фину контролу говора и разноврсним могућностима узорковања говора. Међутим, модели дифузије нису тако ефикасни као неитеративни оквири засновани на ГАН-у и главни разлог за то је захтев да се узоркују латентне репрезентације, таласни облици и мел-спектрограми итеративно до циљног трајања говора.
С друге стране, недавни радови око модела великих говорних језика показали су њихову способност да побољшају квалитет задатака генерисања текста до говора и добро се прилагоде говорнику. Велики модели говорног језика обично конвертују унос текста или у квантизоване или континуиране репрезентације изведене из унапред обучених говорних језичких оквира за задатке реконструкције говора. Међутим, карактеристике ових модела говорног језика нису оптимизоване за директну синтезу говора. Насупрот томе, СтилеТТС2 оквир користи предности знања стеченог великим СЛМ оквирима користећи супротстављену обуку да би синтетизовао карактеристике модела говорног језика без коришћења мапа латентног простора, и стога је учење латентног простора оптимизовано за синтезу говора директно.
СтилеТТС2: Архитектура и методологија
У својој сржи, СтилеТТС2 је изграђен на свом претходнику, СтилеТТС оквиру који је неауторегресивни оквир текста у говор који користи стилски кодер за извођење вектора стила из референтног звука, омогућавајући тако експресивно и природно генерисање говора. Вектор стила који се користи у СтилеТТС оквиру је уграђен директно у кодер, трајање и предикторе коришћењем АдаИН-а или адаптивне нормализације инстанце, омогућавајући на тај начин СтилеТТС моделу да генерише говорне излазе са различитим прозодијама, трајањем, па чак и емоцијама. СтилеТТС оквир се састоји од укупно 8 модела који су подељени у три категорије
- Акустични модели или систем за генерисање говора са енкодером стила, енкодером текста и декодером говора.
- Систем предвиђања текста у говор који користи прозодију и предикторе трајања.
- Услужни систем који укључује поравнавач текста, издвајач тона и дискриминатор за потребе обуке.
Захваљујући свом приступу, СтилеТТС фрамеворк пружа врхунске перформансе везане за контролну и разнолику синтезу говора. Међутим, ове перформансе имају своје недостатке као што су деградација квалитета узорка, експресивна ограничења и ослањање на апликације које ометају говор у реалном времену.
Побољшавајући СтилеТТС оквир, СтилеТТС2 модел даје побољшану експресивност текст у говор задатке са побољшаним перформансама ван дистрибуције и високим квалитетом на људском нивоу. СтилеТТС2 оквир користи процес обуке од краја до краја који оптимизује различите компоненте уз помоћ контрадикторног тренинга и заједничку директну синтезу таласног облика. За разлику од СтилеТТС оквира, СтилеТТС2 оквир моделира стил говора као латентну променљиву, и узоркује га преко дифузионих модела тако да генерише различите узорке говора без коришћења референтног звука. Хајде да детаљно погледамо ове компоненте.
Обука од краја до краја за сметње
У оквиру СтилеТТС2, приступ тренинга од краја до краја се користи за оптимизацију различитих компоненти текста у говор ради интерференције без ослањања на фиксне компоненте. СтилеТТС2 оквир ово постиже модификацијом декодера да генерише таласни облик директно из вектора стила, криве висине тона и енергије и усклађених репрезентација. Фрамеворк затим уклања последњи пројекцијски слој декодера и замењује га декодером таласног облика. СтилеТТС2 оквир користи два енкодера: декодер заснован на ХифиГАН-у за директно генерисање таласног облика и декодер заснован на иСТФТ-у за производњу фазе и величине који се претварају у таласне облике за брже сметње и обуку.
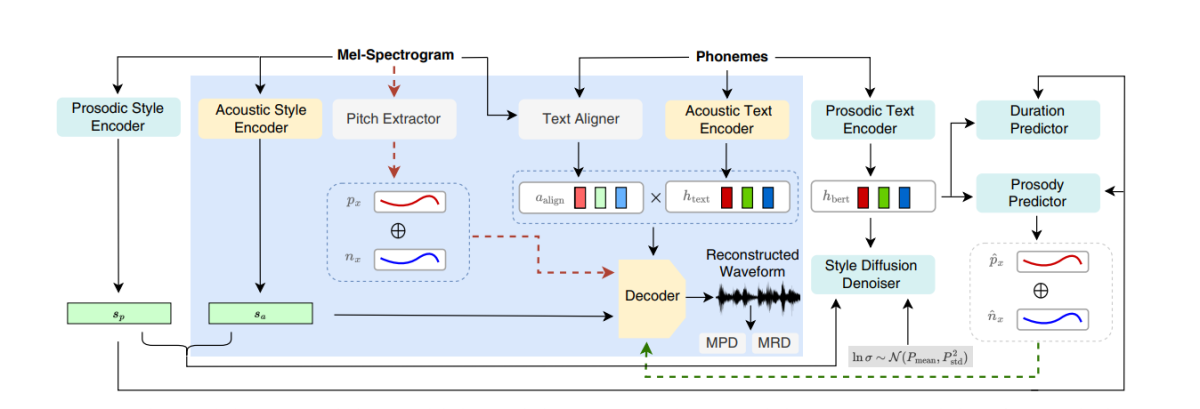
Горња слика представља акустичне моделе који се користе за пре-тренинг и заједнички тренинг. Да би се смањило време тренинга, модули се прво оптимизују у фази пре тренинга, а затим следи оптимизација свих компоненти минус извлачење тона током заједничког тренинга. Разлог зашто заједнички тренинг не оптимизује извлачење висине тона је тај што се користи за обезбеђивање темељне истине за криве нагиба.

Горња слика представља супарничку обуку и мешање у ВавЛМ оквир који је претходно обучен, али није унапред подешен. Процес се разликује од оног горе поменутог јер може узети различите уносне текстове, али акумулира градијенте за ажурирање параметара у свакој групи.
Стиле Диффусион
Оквир СтилеТТС2 има за циљ да моделира говор као условну дистрибуцију кроз латентну променљиву која прати условну дистрибуцију, а ова варијабла се назива генерализовани стил говора и представља било коју карактеристику у узорку говора изван опсега било ког фонетског садржаја укључујући лексички нагласак, прозодија, брзина говора, па чак и формантни прелази.
Дискриминатори модела говорног језика
Модели говорног језика су познати по својим општим способностима да кодирају вредне информације о широком спектру семантичких и акустичких аспеката, а СЛМ репрезентације су традиционално биле у стању да опонашају људску перцепцију како би проценили квалитет генерисаног синтетизованог говора. СтилеТТС2 оквир користи приступ супротстављене обуке да би искористио способност СЛМ енкодера за обављање генеративних задатака и користи 12-слојни ВавЛМ оквир као дискриминатор. Овај приступ омогућава оквиру да омогући обуку о текстовима ООД или ван дистрибуције који могу помоћи у побољшању перформанси. Штавише, да би се спречили проблеми претеривања, оквир узоркује ООД текстове и у дистрибуцији са једнаком вероватноћом.
Моделирање диференцираног трајања
Традиционално, предиктор трајања се користи у оквирима текста у говор који производи трајања фонема, али методе повећања узорковања које ови предиктори трајања користе често блокирају ток градијента током Е2Е процеса обуке, а оквир НатуралСпеецх користи упсамплер заснован на пажњи за људски ниво претварање текста у говор. Међутим, СтилеТТС2 оквир сматра да је овај приступ нестабилан током контрадикторне обуке јер СтилеТТС2 тренира користећи диференцибилно упсамплинг са различитим супарничким тренингом без губитка додатних термина због неусклађености у дужини због одступања. Иако коришћење приступа меког динамичког савијања времена може помоћи у ублажавању ове неусклађености, његово коришћење није само рачунски скупо, већ је и његова стабилност забринута када се ради са супротстављеним циљевима или задацима мел-реконструкције. Због тога, да би се постигао учинак на нивоу човека уз контрадикторну обуку и стабилизовао процес обуке, СтилеТТЦ2 оквир користи приступ непараметарског повећања узорковања. Гаусово повећање узорковања је популаран приступ непараметарског повећања узорковања за претварање предвиђених трајања иако има своја ограничења захваљујући фиксној дужини унапред одређених Гаусових језгара. Ово ограничење за Гаусово повећање узорковања ограничава његову способност да прецизно моделује поравнања са различитим дужинама.
Да би се наишао на ово ограничење, СтилеТТЦ2 оквир предлаже да се користи нови приступ непараметарског повећања узорковања без икакве додатне обуке и способан да обрачуна различите дужине поравнања. За сваку фонему, СтилеТТЦ2 оквир моделира поравнање као случајну променљиву и указује на индекс оквира говора са којим је фонема усклађена.
Обука и евалуација модела
СтилеТТЦ2 оквир је обучен и експериментисан на три скупа података: ВЦТК, ЛибриТТС и ЉСпеецх. Компонента са једним звучником СтилеТТС2 оквира је обучена коришћењем ЉСпеецх скупа података који садржи отприлике 13,000+ аудио узорака подељених у 12,500 узорака за обуку, 100 узорака за валидацију и скоро 500 узорака за тестирање, са њиховим комбинованим трајањем од скоро 24 сата. Компонента оквира са више звучника је обучена на ВЦТК скупу података који се састоји од преко 44,000 аудио клипова са преко 100 појединачних изворних звучника са различитим акцентима, и подељена је на 43,500 узорака за обуку, 100 узорака за валидацију и скоро 500 узорака за тестирање. Коначно, да би се оквир опремио могућностима прилагођавања нула снимака, оквир је обучен на комбинованом скупу података ЛибриТТС који се састоји од аудио клипова у укупном трајању од око 250 сати звука са преко 1,150 појединачних звучника. Да би проценио свој учинак, модел користи две метрике: МОС-Н или средња оцена природности, и МОС-С или средња оцена сличности.

Резултати
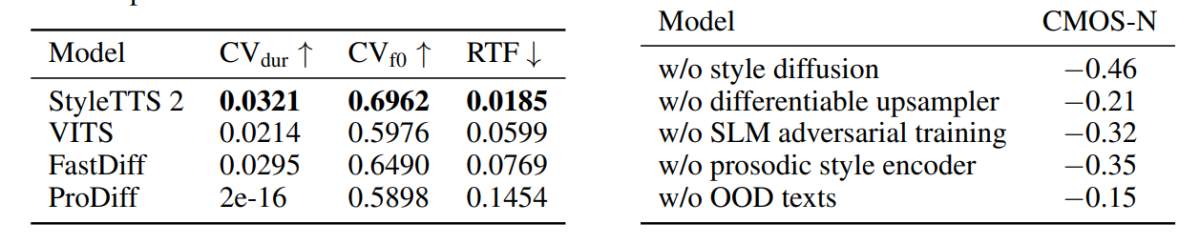
Приступ и методологија која се користи у оквиру СтилеТТС2 приказана је у његовом перформансу јер модел надмашује неколико најсавременијих ТТС оквира, посебно на скупу података НатуралСпеецх, и на путу, постављајући нови стандард за скуп података. Штавише, СтилеТТС2 оквир надмашује најсавременији ВИТС оквир на ВЦТК скупу података, а резултати су приказани на следећој слици.

Модел СтилеТТС2 такође надмашује претходне моделе у скупу података ЉСпеецх и не приказује никакав степен деградације квалитета на текстовима ООД или ван дистрибуције као што је приказано у претходним оквирима на истој метрици. Штавише, у нултом поставци, СтилеТТЦ2 модел надмашује постојећи Валл-Е оквир у природности иако заостаје у смислу сличности. Међутим, вреди напоменути да је СтилеТТС2 оквир у стању да постигне конкурентне перформансе упркос обуци само на 245 сати аудио семплова у поређењу са преко 60 хиљада сати обуке за Валл-Е оквир, чиме се доказује да је СтилеТТЦ2 алтернатива за ефикасне податке. на постојеће велике методе пре-обуке које се користе у Валл-Е.

Крећући се даље, због недостатка аудио текстуалних података означених емоцијама, СтилеТТЦ2 оквир користи ГПТ-4 модел да генерише преко 500 инстанци различитих емоција за визуелизацију вектора стила које оквир креира користећи своје радиодифузија процес.

На првој слици, емоционални стилови као одговор на сентименте уноса текста илустровани су векторима стила из ЉСпеецх модела, и демонстрира способност СтилеТТЦ2 оквира да синтетише експресиван говор са различитим емоцијама. Друга слика приказује различите форме кластера за сваки од пет појединачних звучника, чиме се осликава широк спектар различитости који потиче из једне аудио датотеке. Коначна слика показује лабав кластер емоција из звучника 1 и открива да су, упркос неким преклапањима, кластери засновани на емоцијама истакнути, што указује на могућност манипулисања емоционалном мелодијом звучника без обзира на референтни аудио узорак и његов улазни тон . Упркос коришћењу приступа заснованог на дифузији, СтилеТТС2 оквир успева да надмаши постојеће најсавременије оквире укључујући ВИТС, ПроДифф и ФастДифф.
Завршне мисли
У овом чланку смо говорили о СтилеТТС2, новом, робусном и иновативном оквиру текста у говор који је изграђен на темељима СтилеТТС оквира, а има за циљ да представи следећи корак ка најсавременијим системима текста у говор. СтилеТТС2 оквир моделира стилове говора као латентне случајне променљиве и користи модел вероватноће дифузије за узорковање ових стилова говора или случајних варијабли, чиме се омогућава СтилеТТС2 оквиру да ефикасно синтетише реалистичан говор без коришћења референтних аудио улаза. СтилеТТС2 оквир користи дифузију стила и СЛМ дискриминаторе да постигне перформансе на нивоу човека на задацима од текста до говора, и успева да надмаши постојеће најсавременије оквире на широком спектру говорних задатака.



