
Етика
Тренутне праксе вештачке интелигенције могле би да омогуће нову генерацију тролова за ауторска права

Нова истраживачка сарадња између Хуавеи-а и академске заједнице сугерише да би велики део најважнијих актуелних истраживања у области вештачке интелигенције и машинског учења могао бити изложен судским споровима чим постане комерцијално истакнут, јер се скупови података који омогућавају напредак дистрибуирају са неважећим лиценце које не поштују оригиналне услове јавних домена са којих су подаци добијени.
У ствари, ово има два готово неизбежна могућа исхода: да ће веома успешни, комерцијализовани АИ алгоритми за које се зна да су користили такве скупове података постати будуће мете опортунистичких патентних тролова чија ауторска права нису поштована када су њихови подаци били украдени; и да ће организације и појединци моћи да искористе те исте правне рањивости да протестују против примене или ширења технологија машинског учења које сматрају неприхватљивим.
папир је насловљен Да ли могу да користим овај јавно доступан скуп података за прављење комерцијалног АИ софтвера? Највероватније не, и представља сарадњу између Хуавеи Цанада и Хуавеи Цхина, заједно са Универзитетом Јорк у Великој Британији и Универзитетом Викторија у Канади.
Пет од шест (популарних) скупова података отвореног кода није легално употребљиво
За истраживање, аутори су замолили одељења у Хуавеи-у да изаберу најпожељније скупове података отвореног кода које би желели да искористе у комерцијалним пројектима и изабрали шест најтраженијих скупова података из одговора: ЦИФАР-10 (подскуп од 80 милиона сићушних слика скуп података, пошто Повучен за „погрдне термине“ и „увредљиве слике“, иако се њихови деривати размножавају); ИмагеНет; Градски пејзажи (који садржи искључиво оригинални материјал); ФФХК; ВГГФаце2, и МСЦОЦО.
Да би анализирали да ли су одабрани скупови података погодни за легалну употребу у комерцијалним пројектима, аутори су развили нови канал за праћење ланца лиценци колико год је то било могуће за сваки скуп, иако су често морали да прибегавају снимању веб архива како би лоцирати лиценце са сада истеклих домена, а у одређеним случајевима морао је 'погодити' статус лиценце из најближих доступних информација.
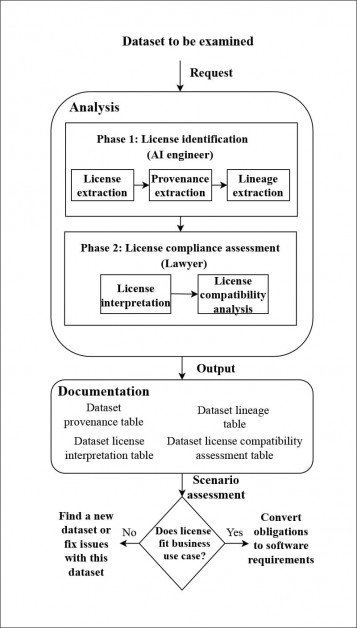
Архитектура за систем праћења провенијенције коју су развили аутори. Извор: хттпс://аркив.орг/пдф/2111.02374.пдф
Аутори су открили да лиценце за пет од шест скупова података 'садрже ризике повезане са најмање једним контекстом комерцијалне употребе':
„[Ми] примећујемо да, осим МС ЦОЦО, ниједна од проучаваних лиценци не дозвољава практичарима право да комерцијализују АИ модел обучен на подацима или чак на излазу обученог АИ модела. Такав резултат такође ефикасно спречава практичаре да чак користе унапред обучене моделе обучене на овим скуповима података. Јавно доступни скупови података и АИ модели који су претходно обучени на њима су широко се користи комерцијално.' *
Аутори даље примећују да три од шест проучаваних скупова података могу додатно довести до кршења лиценце у комерцијалним производима ако се скуп података модификује, пошто само МС-ЦОЦО то дозвољава. Ипак, повећање података и подскупови и суперскупови утицајних скупова података су уобичајена пракса.
У случају ЦИФАР-10, оригинални састављачи уопште нису направили никакав конвенционални облик лиценце, само су захтевали да пројекти који користе скуп података укључују цитирање оригиналног документа који је пратио објављивање скупа података, што представља даљу препреку за успостављање правни статус података.
Даље, само скуп података ЦитиСцапес-а садржи материјал који је искључиво генерисан од стране аутора скупа података, уместо да буде 'курисан' (скраден) из мрежних извора, при чему ЦИФАР-10 и ИмагеНет користе више извора, од којих би сваки требало да се истражи и праћени уназад како би се успоставио било какав механизам ауторских права (или чак смислено одрицање од одговорности).
Но Ваи Оут
Чини се да се комерцијалне компаније за вештачку интелигенцију ослањају на три фактора да би их заштитиле од судских спорова око производа који су користили садржај заштићен ауторским правима из скупова података слободно и без дозволе, за обуку АИ алгоритама. Ништа од овога не пружа много (или било какву) поуздану дугорочну заштиту:
1: Лаиссез Фаире Натионал Лавс
Иако су владе широм света принуђене да олабаве законе у вези са скраћивањем података у настојању да не одустану у трци ка ефикасној вештачкој интелигенцији (која се ослања на велике количине података из стварног света за које би редовно поштовање ауторских права и лиценцирање били нереални), само Сједињене Државе нуде пуни имунитет у овом погледу, под Доктрина поштене употребе – политика која је ратификована 2015. године закључак Гуилд аутора против Гугла, Инц., који је потврдио да гигант за претрагу може слободно да узима материјал заштићен ауторским правима за свој пројекат Гоогле Боокс, а да не буде оптужен за кршење.
Ако се политика доктрине поштене употребе икада промени (тј. као одговор на други значајан случај који укључује довољно моћне организације или корпорације), то би се вероватно сматрало априори држава у смислу искоришћавања тренутних база података којима се крше ауторска права, штитећи раније коришћење; али не у току коришћење и развој система који су омогућени путем материјала заштићеног ауторским правима без договора.
Ово ставља тренутну заштиту Доктрине поштене употребе на веома привремену основу, и потенцијално би, у том сценарију, могло да захтева да успостављени, комерцијализовани алгоритми машинског учења престану са радом у случајевима када је њихово порекло омогућено материјалом заштићеним ауторским правима – чак иу случајевима када модела тегови сада се баве искључиво дозвољеним садржајем, али су обучени (и постали корисни) незаконито копираним садржајем.
Изван САД, као што аутори примећују у новом раду, политике су генерално мање благе. Уједињено Краљевство и Канада обештећују само коришћење података заштићених ауторским правима у некомерцијалне сврхе, док Закон ЕУ о тексту и рударењу података (који није у потпуности поништен од стране недавни предлози за формалнију регулацију АИ) такође искључује комерцијалну експлоатацију за АИ системе који нису у складу са захтевима ауторских права оригиналних података.
Ови последњи аранжмани значе да организација може постићи велике ствари са подацима других људи, све до – али не укључујући – тачке да заради било какав новац од тога. У тој фази, производ би или постао правно изложен, или би морали да се склопе договори са буквално милионима носилаца ауторских права, од којих се многима сада не може ући у траг због променљиве природе интернета – немогуће и неприуштиве могућности.
2: Упозорење Емптор
У случајевима када се организације које крше ауторска права надају да ће одложити кривицу, нови документ такође примећује да се многе лиценце за најпопуларније скупове података отвореног кода аутоматски обештећују од било каквих тврдњи о злоупотреби ауторских права:
„На пример, ИмагеНет-ова лиценца изричито захтева од практичара да обештете ИмагеНет тим од било каквих захтева који произилазе из употребе скупа података. Скупови података ФФХК, ВГГФаце2 и МС ЦОЦО захтевају да скуп података, ако је дистрибуиран или модификован, буде представљен под истом лиценцом.'
У ствари, ово приморава оне који користе ФОСС скупове података да апсорбују кривицу за коришћење материјала заштићеног ауторским правима, суочени са евентуалним судским споровима (иако то не мора нужно да штити оригиналне компајлере у случају када постоји тренутна клима 'сигурне луке').
3: Обештећење кроз непознатост
Сарадничка природа заједнице машинског учења чини прилично тешким коришћењем корпоративног окултизма да би се прикрило присуство алгоритама који су имали користи од скупова података који крше ауторска права. Дугорочни комерцијални пројекти често почињу у отвореним ФОСС окружењима где је употреба скупова података ствар евиденције, на ГитХуб-у и другим јавно доступним форумима, или где је порекло пројекта објављено у препринт или рецензираним радовима.
Чак и тамо где то није случај, инверзија модела is све способнији откривања типичних карактеристика скупова података (или чак експлицитно излазећи неки од изворног материјала), или пружа доказ сам по себи, или довољно сумње у кршење да би се омогућио судски приступ историји развоја алгоритма и детаљима скупова података коришћених у том развоју.
Zakljucak
Рад приказује хаотично и ад хоц коришћење материјала заштићеног ауторским правима добијеног без дозволе, као и низа ланаца лиценци који би, логично праћени све до првобитног извора података, захтевали преговоре са хиљадама носилаца ауторских права чији је рад представљен. под окриљем сајтова са широким спектром услова лиценцирања, од којих многи искључују изведене комерцијалне радове.
Аутори закључују:
„Јавно доступни скупови података се нашироко користе за прављење комерцијалног АИ софтвера. То се може учинити ако [и] само ако лиценца повезана са јавно доступним скупом података даје право на то. Међутим, није лако проверити права и обавезе наведене у лиценци у вези са јавно доступним скуповима података. Јер, понекад је лиценца или нејасна или потенцијално неважећа.'
Још једно ново дело, под насловом Изградња скупова правних података, објављен 2. новембра из Центра за рачунарско право на Универзитету за менаџмент у Сингапуру, такође наглашава потребу да научници података препознају да се ера ад хоц прикупљања података 'дивљег запада' ближи крају, и одражава препоруке Хуавеи-а папир да усвоји строже навике и методологије како би се осигурало да коришћење скупа података не излаже пројекат правним последицама како се култура мења током времена, и пошто тренутна глобална академска активност у сектору машинског учења тражи комерцијални повраћај на године улагања . Аутор примећује*:
„[Корпус] закона који утичу на скупове података МЛ ће се повећати, усред забринутости које тренутни закони нуде недовољан гаранције. Нацрт АИА [Закон ЕУ о вештачкој интелигенцији], ако и када буде усвојен, значајно би променио пејзаж АИ и управљања подацима; друге јурисдикције могу да следе њихов пример својим сопственим актима. '
* Моја конверзија инлине цитата у хипервезе















